Query Cache
The query cache is a powerful feature of StarRocks that can greatly enhance the performance of aggregate queries. By storing the intermediate results of local aggregations in memory, the query cache can avoid unnecessary disk access and computation for new queries that are identical or similar to previous ones. With its query cache, StarRocks can deliver fast and accurate results for aggregate queries, saving time and resources and enabling better scalability. The query cache is especially useful for high-concurrency scenarios where many users run similar queries on large and complex data sets.
This feature is supported since v2.5.
In v2.5, the query cache supports only aggregate queries on single flat tables. Since v3.0, the query cache also supports aggregate queries on multiple tables joined in a star schema.
Application scenarios
We recommend that you use the query cache in the following scenarios:
- You frequently run aggregate queries on individual flat tables or on multiple joined tables that are connected in a star schema.
- Most of your aggregate queries are non-GROUP BY aggregate queries and low-cardinality GROUP BY aggregate queries.
- Your data is loaded in append mode by time partition and can be categorized as hot data and cold data based on access frequency.
The query cache supports queries that meet the following conditions:
-
The query engine is Pipeline. To enable the Pipeline engine, set the session variable
enable_pipeline_enginetotrue.NOTE
Other query engines do not support the query cache.
-
The queries are on native OLAP tables (from v2.5) or cloud-native tables (from v3.0). The query cache does not support queries on external tables. The query cache also supports queries whose plans require access to synchronous materialized views. However, the query cache does not support queries whose plans require access to asynchronous materialized views.
-
The queries are aggregate queries on individual tables or on multiple joined tables.
NOTE
- The query cache supports Broadcast Join and Bucket Shuffle Join.
- The query cache supports two tree structures that contain Join operators: Aggregation-Join and Join-Aggregation. Shuffle joins are not supported in the Aggregation-Join tree structure, while Hash joins are not supported in the Join-Aggregation tree structure.
-
The queries do not include nondeterminstic functions such as
rand,random,uuid, andsleep.
The query cache supports queries on tables that use any of the following partition policies: Unpartitioned, Multi-Column Partitioned, and Single-Column Partitioned.
Feature boundaries
- The query cache is based on per-tablet computations of the Pipeline engine. Per-tablet computation means that a pipeline driver can process entire tablets one by one rather than processing a portion of a tablet or many tablets interleaved together. If the number of tablets that need to be processed by each individual BE for a query is greater than or equal to the number of pipeline drivers that are invoked to run this query, the query cache works. The number of pipeline drivers invoked represents the actual degree of parallelism (DOP). If the number of tablets is smaller than the number of pipeline drivers, each pipeline driver processes only a portion of a specific tablet. In this situation, per-tablet computation results cannot be produced, and therefore the query cache does not work.
- In StarRocks, an aggregate query consists of at least four stages. Per-Tablet computation results generated by AggregateNode in the first stage can be cached only when OlapScanNode and AggregateNode compute data from the same fragment. Per-Tablet computation results generated by AggregateNode in the other stages cannot be cached. For some DISTINCT aggregate queries, if the session variable
cbo_cte_reuseis set totrue, the query cache does not work when OlapScanNode, which produces data, and the stage-1 AggregateNode, which consumes the produced data, compute data from different fragments and are bridged by an ExchangeNode. The following two examples show scenarios in which CTE optimizations are performed and therefore the query cache does not work:- The output columns are computed by using the aggregate function
avg(distinct). - The output columns are computed by multiple DISTINCT aggregate functions.
- The output columns are computed by using the aggregate function
- If your data is shuffled before aggregation, the query cache cannot accelerate the queries on that data.
- If the group-by columns or deduplicating columns of a table are high-cardinality columns, large results will be generated for aggregate queries on that table. In these cases, the queries will bypass the query cache at runtime.
- The query cache occupies a small amount of memory provided by the BE to save computation results. The size of the query cache defaults to 512 MB. Therefore, it is unsuitable for the query cache to save large-sized data items. Additionally, after you enable the query cache, query performance is decreased if the cache hit ratio is low. Therefore, if the size of computation results generated for a tablet exceeds the threshold specified by the
query_cache_entry_max_bytesorquery_cache_entry_max_rowsparameter, the query cache no longer works for the query and the query is switched to Passthrough mode.
How it works
When the query cache is enabled, each BE splits the local aggregation of a query into the following two stages:
-
Per-tablet aggregation
The BE processes each tablet individually. When the BE begins processing a tablet, it first probes the query cache to see if the intermediate result of aggregation on that tablet is in the query cache. If so (a cache hit), the BE directly fetches the intermediate result from the query cache. If no (a cache miss), the BE accesses the data on disk and performs local aggregation to compute the intermediate result. When the BE finished processing a tablet, it populates the query cache with the intermediate result of aggregation on that tablet.
-
Inter-tablet aggregation
The BE gathers the intermediate results from all tablets involved in the query and merges them into a final result.

When a similar query is issued in the future, it can reuse the cached result for the previous query. For example, the query shown in the following figure involves three tablets (Tablets 0 through 2), and the intermediate result for the first tablet (Tablet 0) is already in the query cache. For this example, the BE can directly fetch the result for Tablet 0 from the query cache instead of accessing the data on disk. If the query cache is fully warmed up, it can contain the intermediate results for all three tablets and thus the BE does not need to access any data on disk.

To free up extra memory, the query cache adopts a Least Recently Used (LRU)-based eviction policy to manage the cache entries in it. According to this eviction policy, when the amount of memory occupied by the query cache exceeds its predefined size (query_cache_capacity), the least recently used cache entries are evicted out of the query cache.
NOTE
In the future, StarRocks will also support a Time to Live (TTL)-based eviction policy based on which cache entries can be evicted out of the query cache.
The FE determines whether each query needs to be accelerated by using the query cache and normalizes the queries to eliminate trivial literal details that have no effect on the semantics of queries.
To prevent the performance penalty incurred by the bad cases of the query cache, the BE adopts an adaptive policy to bypass the query cache at runtime.
Enable query cache
This section describes the parameters and session variables that are used to enable and configure the query cache.
FE session variables
| Variable | Default value | Can be dynamically configured | Description |
|---|---|---|---|
| enable_query_cache | false | Yes | Specifies whether to enable the query cache. Valid values: true and false. true specifies to enable this feature, and false specifies to disable this feature. When the query cache is enabled, it works only for queries that meet the conditions specified in the "Application scenarios" section of this topic. |
| query_cache_entry_max_bytes | 4194304 | Yes | Specifies the threshold for triggering the Passthrough mode. Valid values: 0 to 9223372036854775807. When the number of bytes or rows from the computation results of a specific tablet accessed by a query exceeds the threshold specified by the query_cache_entry_max_bytes or query_cache_entry_max_rows parameter, the query is switched to Passthrough mode.If the query_cache_entry_max_bytes or query_cache_entry_max_rows parameter is set to 0, the Passthrough mode is used even when no computation results are generated from the involved tablets. |
| query_cache_entry_max_rows | 409600 | Yes | Same as above. |
BE parameters
You need to configure the following parameter in the BE configuration file be.conf. After you reconfigure this parameter for a BE, you must restart the BE to make the new parameter setting take effect.
| Parameter | Required | Description |
|---|---|---|
| query_cache_capacity | No | Specifies the size of the query cache. Unit: bytes. The default size is 512 MB. Each BE has its own local query cache in memory, and it populates and probes only its own query cache. Note that the query cache size cannot be less than 4 MB. If the memory capacity of the BE is insufficient to provision your expected query cache size, you can increase the memory capacity of the BE. |
Engineered for maximum cache hit rate in all scenarios
Consider three scenarios where the query cache is still effective even when the queries are not identical literally. These three scenarios are:
- Semantically equivalent queries
- Queries with overlapping scanned partitions
- Queries against data with append-only data changes (no UPDATE or DELETE operations)
Semantically equivalent queries
When two queries are similar, which does not mean that they must be literally equivalent but means that they contain semantically equivalent snippets in their execution plans, they are considered semantically equivalent and can reuse each other's computation results. In a broad sense, two queries are semantically equivalent if they query data from the same source, use the same computation method, and have the same execution plan. StarRocks applies the following rules to evaluate whether two queries are semantically equivalent:
-
If the two queries contain multiple aggregations, they are evaluated as semantically equivalent as long as their first aggregations are semantically equivalent. For example, the following two queries, Q1 and Q2, both contain multiple aggregations, but their first aggregations are semantically equivalent. Therefore, Q1 and Q2 are evaluated as semantically equivalent.
-
Q1
SELECT
(
ifnull(sum(murmur_hash3_32(hour)), 0) + ifnull(sum(murmur_hash3_32(k0)), 0) + ifnull(sum(murmur_hash3_32(__c_0)), 0)
) AS fingerprint
FROM
(
SELECT
date_trunc('hour', ts) AS hour,
k0,
sum(v1) AS __c_0
FROM
t0
WHERE
ts between '2022-01-03 00:00:00'
and '2022-01-03 23:59:59'
GROUP BY
date_trunc('hour', ts),
k0
) AS t; -
Q2
SELECT
date_trunc('hour', ts) AS hour,
k0,
sum(v1) AS __c_0
FROM
t0
WHERE
ts between '2022-01-03 00:00:00'
and '2022-01-03 23:59:59'
GROUP BY
date_trunc('hour', ts),
k0
-
-
If the two queries both belong to one of the following query types, they can be evaluated as semantically equivalent. Note that queries that include a HAVING clause cannot be evaluated as semantically equivalent to queries that do not include a HAVING clause. However, the inclusion of an ORDER BY or LIMIT clause does not affect the evaluation of whether two queries are semantically equivalent.
-
GROUP BY aggregations
SELECT <GroupByItems>, <AggFunctionItems>
FROM <Table>
WHERE <Predicates> [and <PartitionColumnRangePredicate>]
GROUP BY <GroupByItems>
[HAVING <HavingPredicate>]NOTE
In the preceding example, the HAVING clause is optional.
-
GROUP BY DISTINCT aggregations
SELECT DISTINCT <GroupByItems>, <Items>
FROM <Table>
WHERE <Predicates> [and <PartitionColumnRangePredicate>]
GROUP BY <GroupByItems>
HAVING <HavingPredicate>NOTE
In the preceding example, the HAVING clause is optional.
-
Non-GROUP BY aggregations
SELECT <AggFunctionItems> FROM <Table>
WHERE <Predicates> [and <PartitionColumnRangePredicate>] -
Non-GROUP BY DISTINCT aggregations
SELECT DISTINCT <Items> FROM <Table>
WHERE <Predicates> [and <PartitionColumnRangePredicate>]
-
-
If either query includes
PartitionColumnRangePredicate,PartitionColumnRangePredicateis removed before the two queries are evaluated for semantic equivalence.PartitionColumnRangePredicatespecifies one of the following types of predicates that reference a partitioning column:col between v1 and v2: The values of the partitioning column fall within the [v1, v2] range, in whichv1andv2are constant expressions.v1 < col and col < v2: The values of the partitioning column fall within the (v1, v2) range, in whichv1andv2are constant expressions.v1 < col and col <= v2: The values of the partitioning column fall within the (v1, v2] range, in whichv1andv2are constant expressions.v1 <= col and col < v2: The values of the partitioning column fall within the [v1, v2) range, in whichv1andv2are constant expressions.v1 <= col and col <= v2: The values of the partitioning column fall within the [v1, v2] range, in whichv1andv2are constant expressions.
-
If the output columns of the SELECT clauses of the two queries are the same after they are rearranged, the two queries are evaluated as semantically equivalent.
-
If the output columns of the GROUP BY clauses of the two queries are the same after they are rearranged, the two queries are evaluated as semantically equivalent.
-
If the remaining predicates of the WHERE clauses of the two queries are semantically equivalent after
PartitionColumnRangePredicateis removed, the two queries are evaluated as semantically equivalent. -
If the predicates in the HAVING clauses of the two queries are semantically equivalent, the two queries are evaluated as semantically equivalent.
Use the following table lineorder_flat as an example:
CREATE TABLE `lineorder_flat`
(
`lo_orderdate` date NOT NULL COMMENT "",
`lo_orderkey` int(11) NOT NULL COMMENT "",
`lo_linenumber` tinyint(4) NOT NULL COMMENT "",
`lo_custkey` int(11) NOT NULL COMMENT "",
`lo_partkey` int(11) NOT NULL COMMENT "",
`lo_suppkey` int(11) NOT NULL COMMENT "",
`lo_orderpriority` varchar(100) NOT NULL COMMENT "",
`lo_shippriority` tinyint(4) NOT NULL COMMENT "",
`lo_quantity` tinyint(4) NOT NULL COMMENT "",
`lo_extendedprice` int(11) NOT NULL COMMENT "",
`lo_ordtotalprice` int(11) NOT NULL COMMENT "",
`lo_discount` tinyint(4) NOT NULL COMMENT "",
`lo_revenue` int(11) NOT NULL COMMENT "",
`lo_supplycost` int(11) NOT NULL COMMENT "",
`lo_tax` tinyint(4) NOT NULL COMMENT "",
`lo_commitdate` date NOT NULL COMMENT "",
`lo_shipmode` varchar(100) NOT NULL COMMENT "",
`c_name` varchar(100) NOT NULL COMMENT "",
`c_address` varchar(100) NOT NULL COMMENT "",
`c_city` varchar(100) NOT NULL COMMENT "",
`c_nation` varchar(100) NOT NULL COMMENT "",
`c_region` varchar(100) NOT NULL COMMENT "",
`c_phone` varchar(100) NOT NULL COMMENT "",
`c_mktsegment` varchar(100) NOT NULL COMMENT "",
`s_name` varchar(100) NOT NULL COMMENT "",
`s_address` varchar(100) NOT NULL COMMENT "",
`s_city` varchar(100) NOT NULL COMMENT "",
`s_nation` varchar(100) NOT NULL COMMENT "",
`s_region` varchar(100) NOT NULL COMMENT "",
`s_phone` varchar(100) NOT NULL COMMENT "",
`p_name` varchar(100) NOT NULL COMMENT "",
`p_mfgr` varchar(100) NOT NULL COMMENT "",
`p_category` varchar(100) NOT NULL COMMENT "",
`p_brand` varchar(100) NOT NULL COMMENT "",
`p_color` varchar(100) NOT NULL COMMENT "",
`p_type` varchar(100) NOT NULL COMMENT "",
`p_size` tinyint(4) NOT NULL COMMENT "",
`p_container` varchar(100) NOT NULL COMMENT ""
)
ENGINE=OLAP
DUPLICATE KEY(`lo_orderdate`, `lo_orderkey`)
COMMENT "olap"
PARTITION BY RANGE(`lo_orderdate`)
(PARTITION p1 VALUES [('0000-01-01'), ('1993-01-01')),
PARTITION p2 VALUES [('1993-01-01'), ('1994-01-01')),
PARTITION p3 VALUES [('1994-01-01'), ('1995-01-01')),
PARTITION p4 VALUES [('1995-01-01'), ('1996-01-01')),
PARTITION p5 VALUES [('1996-01-01'), ('1997-01-01')),
PARTITION p6 VALUES [('1997-01-01'), ('1998-01-01')),
PARTITION p7 VALUES [('1998-01-01'), ('1999-01-01')))
DISTRIBUTED BY HASH(`lo_orderkey`)
PROPERTIES
(
"replication_num" = "3",
"colocate_with" = "groupxx1",
"storage_format" = "DEFAULT",
"enable_persistent_index" = "false",
"compression" = "LZ4"
);
The following two queries, Q1 and Q2, on the table lineorder_flat are semantically equivalent after they are processed as follows:
- Rearrange the output columns of the SELECT statement.
- Rearrange the output columns of the GROUP BY clause.
- Remove the output columns of the ORDER BY clause.
- Rearrange the predicates in the WHERE clause.
- Add
PartitionColumnRangePredicate.
-
Q1
SELECT sum(lo_revenue), year(lo_orderdate) AS year,p_brand
FROM lineorder_flat
WHERE p_category = 'MFGR#12' AND s_region = 'AMERICA'
GROUP BY year,p_brand
ORDER BY year,p_brand; -
Q2
SELECT year(lo_orderdate) AS year, p_brand, sum(lo_revenue)
FROM lineorder_flat
WHERE s_region = 'AMERICA' AND p_category = 'MFGR#12' AND
lo_orderdate >= '1993-01-01' AND lo_orderdate <= '1993-12-31'
GROUP BY p_brand, year(lo_orderdate)
Semantic equivalence is evaluated based on the physical plans of queries. Therefore, literal differences in queries do not impact the evaluation for semantic equivalence. Additionally, constant expressions are removed from queries, and cast expressions are removed during query optimizations. Therefore, these expressions do not impact the evaluation for semantic equivalence. Thirdly, the aliases of columns and relations do not impact the evaluation for semantic equivalence either.
Queries with overlapping scanned partitions
Query Cache supports predicate-based query splitting.
Splitting queries based on predicate semantics help implement reuse of partial computation results. When a query contains a predicate that references the partitioning column of a table and the predicate specifies a value range, StarRocks can split the range into multiple intervals based on table partitioning. The computation results from each individual interval can be separately reused by other queries.
Use the following table t0 as an example:
CREATE TABLE if not exists t0
(
ts DATETIME NOT NULL,
k0 VARCHAR(10) NOT NULL,
k1 BIGINT NOT NULL,
v1 DECIMAL64(7, 2) NOT NULL
)
ENGINE=OLAP
DUPLICATE KEY(`ts`, `k0`, `k1`)
COMMENT "OLAP"
PARTITION BY RANGE(ts)
(
START ("2022-01-01 00:00:00") END ("2022-02-01 00:00:00") EVERY (INTERVAL 1 day)
)
DISTRIBUTED BY HASH(`ts`, `k0`, `k1`)
PROPERTIES
(
"replication_num" = "3",
"storage_format" = "default"
);
The table t0 is partitioned by day, and the column ts is the table's partitioning column. Among the following four queries, Q2, Q3, and Q4 can reuse portions of the computation results cached for Q1:
-
Q1
SELECT date_trunc('day', ts) as day, sum(v0)
FROM t0
WHERE ts BETWEEN '2022-01-02 12:30:00' AND '2022-01-14 23:59:59'
GROUP BY day;The value range specified by the predicate
ts between '2022-01-02 12:30:00' and '2022-01-14 23:59:59'of Q1 can be split into the following intervals:1. [2022-01-02 12:30:00, 2022-01-03 00:00:00),
2. [2022-01-03 00:00:00, 2022-01-04 00:00:00),
3. [2022-01-04 00:00:00, 2022-01-05 00:00:00),
...
12. [2022-01-13 00:00:00, 2022-01-14 00:00:00),
13. [2022-01-14 00:00:00, 2022-01-15 00:00:00), -
Q2
SELECT date_trunc('day', ts) as day, sum(v0)
FROM t0
WHERE ts >= '2022-01-02 12:30:00' AND ts < '2022-01-05 00:00:00'
GROUP BY day;Q2 can reuse the computation results within the following intervals of Q1:
1. [2022-01-02 12:30:00, 2022-01-03 00:00:00),
2. [2022-01-03 00:00:00, 2022-01-04 00:00:00),
3. [2022-01-04 00:00:00, 2022-01-05 00:00:00), -
Q3
SELECT date_trunc('day', ts) as day, sum(v0)
FROM t0
WHERE ts >= '2022-01-01 12:30:00' AND ts <= '2022-01-10 12:00:00'
GROUP BY day;Q3 can reuse the computation results within the following intervals of Q1:
2. [2022-01-03 00:00:00, 2022-01-04 00:00:00),
3. [2022-01-04 00:00:00, 2022-01-05 00:00:00),
...
8. [2022-01-09 00:00:00, 2022-01-10 00:00:00), -
Q4
SELECT date_trunc('day', ts) as day, sum(v0)
FROM t0
WHERE ts BETWEEN '2022-01-02 12:30:00' and '2022-01-02 23:59:59'
GROUP BY day;Q4 can reuse the computation results within the following intervals of Q1:
1. [2022-01-02 12:30:00, 2022-01-03 00:00:00),
The support for reuse of partial computation results varies depending on the partitioning policy used, as described in the following table.
| Partitioning policy | Support for reuse of partial computation results |
|---|---|
| Unpartitioned | Not supported |
| Multi-Column Partitioned | Not supported NOTE This feature may be supported in the future. |
| Single-Column Partitioned | Supported |
Queries against data with append-only data changes
Query Cache supports multi-version caching.
As data loads are made, new versions of tablets are generated. Consequently, the cached computation results that are generated from the previous versions of the tablets become stale and lag behind the latest tablet versions. In this situation, the multi-version caching mechanism tries to merge the stale results saved in the query cache and the incremental versions of the tablets stored on disk into the final results of the tablets so that new queries can carry the latest tablet versions. Multi-version caching is constrained by table types, query types, and data update types.
The support for multi-version caching varies depending on table types and query types, as described in the following table.
| Table type | Query type | Support for multi-version caching |
|---|---|---|
| Duplicate Key table |
|
|
| Aggregate table | Queries on base tables or queries on synchronous materialized views | Supported in all situations except the following:The schemas of base tables contain the aggregate function replace.The GROUP BY, HAVING, or WHERE clauses of queries reference aggregation columns.Incremental tablet versions contain data deletion records. |
| Unique Key table | N/A | Not supported. However, the query cache is supported. |
| Primary Key table | N/A | Not supported. However, the query cache is supported. |
The impact of data update types on multi-version caching is as follows:
-
Data deletions
Multi-version caching cannot work if incremental versions of tablets contain delete operations.
-
Data insertions
- If an empty version is generated for a tablet, the existing data of the tablet in the query cache remains valid and can still be retrieved.
- If a non-empty version is generated for a tablet, the existing data of the tablet in the query cache remains valid, but its version lags behind the latest version of the tablet. In this situation, StarRocks reads the incremental data generated from the version of the existing data to the latest version of the tablet, merges the existing data with the incremental data, and populates the merged data into the query cache.
-
Schema changes and tablet truncations
If the schema of a table is changed or specific tablets of the table are truncated, new tablets are generated for the table. As a result, the existing data of the tablets of the table in the query cache becomes invalid.
Metrics
The profiles of queries for which the query cache works contain CacheOperator statistics.
In the source plan of a query, if the pipeline contains OlapScanOperator, the names of OlapScanOperator and aggregate operators are prefixed with ML_ to denote that the pipeline uses MultilaneOperator to perform per-tablet computations. CacheOperator is inserted preceding ML_CONJUGATE_AGGREGATE to process the logic that controls how the query cache runs in Passthrough, Populate, and Probe modes. The profile of the query contains the following CacheOperator metrics that help you understand the query cache usage.
| Metric | Description |
|---|---|
| CachePassthroughBytes | The number of bytes generated in Passthrough mode. |
| CachePassthroughChunkNum | The number of chunks generated in Passthrough mode. |
| CachePassthroughRowNum | The number of rows generated in Passthrough mode. |
| CachePassthroughTabletNum | The number of tablets generated in Passthrough mode. |
| CachePassthroughTime: | The amount of computation time taken in Passthrough mode. |
| CachePopulateBytes | The number of bytes generated in Populate mode. |
| CachePopulateChunkNum | The number of chunks generated in Populate mode. |
| CachePopulateRowNum | The number of rows generated in Populate mode. |
| CachePopulateTabletNum | The number of tablets generated in Populate mode. |
| CachePopulateTime | The amount of computation time taken in Populate mode. |
| CacheProbeBytes | The number of bytes generated for cache hits in Probe mode. |
| CacheProbeChunkNum | The number of chunks generated for cache hits in Probe mode. |
| CacheProbeRowNum | The number of rows generated for cache hits in Probe mode. |
| CacheProbeTabletNum | The number of tablets generated for cache hits in Probe mode. |
| CacheProbeTime | The amount of computation time taken in Probe mode. |
CachePopulateXXX metrics provide statistics about query cache misses for which the query cache is updated.
CachePassthroughXXX metrics provide statistics about query cache misses for which the query cache is not updated because the size of per-tablet computation results generated is large.
CacheProbeXXX metrics provide statistics about query cache hits.
In the multi-version caching mechanism, CachePopulate metrics and CacheProbe metrics may contain the same tablet statistics, and CachePassthrough metrics and CacheProbe metrics may also contain the same tablet statistics. For example, when StarRocks computes the data of each tablet, it hits the computation results generated on the historical version of the tablet. In this situation, StarRocks reads the incremental data generated from the historical version to the latest version of the tablet, computes the data, and merges the incremental data with the cached data. If the size of the computation results generated after the merging does not exceed the threshold specified by the query_cache_entry_max_bytes or query_cache_entry_max_rows parameter, the statistics of the tablet are collected into CachePopulate metrics. Otherwise, the statistics of the tablet are collected into CachePassthrough metrics.
RESTful API operations
-
metrics |grep query_cacheThis API operation is used to query the metrics related to the query cache.
curl -s http://<be_host>:<be_http_port>/metrics |grep query_cache
# TYPE starrocks_be_query_cache_capacity gauge
starrocks_be_query_cache_capacity 536870912
# TYPE starrocks_be_query_cache_hit_count gauge
starrocks_be_query_cache_hit_count 5084393
# TYPE starrocks_be_query_cache_hit_ratio gauge
starrocks_be_query_cache_hit_ratio 0.984098
# TYPE starrocks_be_query_cache_lookup_count gauge
starrocks_be_query_cache_lookup_count 5166553
# TYPE starrocks_be_query_cache_usage gauge
starrocks_be_query_cache_usage 0
# TYPE starrocks_be_query_cache_usage_ratio gauge
starrocks_be_query_cache_usage_ratio 0.000000 -
api/query_cache/statThis API operation is used to query the usage of the query cache.
curl http://<be_host>:<be_http_port>/api/query_cache/stat
{
"capacity": 536870912,
"usage": 0,
"usage_ratio": 0.0,
"lookup_count": 5025124,
"hit_count": 4943720,
"hit_ratio": 0.983800598751394
} -
api/query_cache/invalidate_allThis API operation is used to clear the query cache.
curl -XPUT http://<be_host>:<be_http_port>/api/query_cache/invalidate_all
{
"status": "OK"
}
The parameters in the preceding API operations are as follows:
be_host: the IP address of the node on which the BE resides.be_http_port: the HTTP port number of the node on which the BE resides.
Precautions
- StarRocks needs to populate the query cache with the computation results of queries that are initiated for the first time. As a result, the query performance may be slightly lower than expected, and the query latency is increased.
- If you configure a large query cache size, the amount of memory that can be provisioned to query evaluation on the BE is decreased. We recommend that the query cache size do not exceed 1/6 of the memory capacity provisioned to query evaluation.
- If the number of tablets that need to be processed is smaller than the value of
pipeline_dop, the query cache does not work. To enable the query cache to work, you can setpipeline_dopto a smaller value such as1. From v3.0 onwards, StarRocks adaptively adjusts this parameter based on query parallelism.
Examples
Dataset
-
Log in to your StarRocks cluster, go to the destination database, and run the following command to create a table named
t0:CREATE TABLE t0
(
`ts` datetime NOT NULL COMMENT "",
`k0` varchar(10) NOT NULL COMMENT "",
`k1` char(6) NOT NULL COMMENT "",
`v0` bigint(20) NOT NULL COMMENT "",
`v1` decimal64(7, 2) NOT NULL COMMENT ""
)
ENGINE=OLAP
DUPLICATE KEY(`ts`, `k0`, `k1`)
COMMENT "OLAP"
PARTITION BY RANGE(`ts`)
(
START ("2022-01-01 00:00:00") END ("2022-02-01 00:00:00") EVERY (INTERVAL 1 DAY)
)
DISTRIBUTED BY HASH(`ts`, `k0`, `k1`)
PROPERTIES
(
"replication_num" = "3",
"storage_format" = "DEFAULT",
"enable_persistent_index" = "false"
); -
Insert the following data records into
t0:INSERT INTO t0
VALUES
('2022-01-11 20:42:26', 'n4AGcEqYp', 'hhbawx', '799393174109549', '8029.42'),
('2022-01-27 18:17:59', 'i66lt', 'mtrtzf', '100400167', '10000.88'),
('2022-01-28 20:10:44', 'z6', 'oqkeun', '-58681382337', '59881.87'),
('2022-01-29 14:54:31', 'qQ', 'dzytua', '-19682006834', '43807.02'),
('2022-01-31 08:08:11', 'qQ', 'dzytua', '7970665929984223925', '-8947.74'),
('2022-01-15 00:40:58', '65', 'hhbawx', '4054945', '156.56'),
('2022-01-24 16:17:51', 'onqR3JsK1', 'udtmfp', '-12962', '-72127.53'),
('2022-01-01 22:36:24', 'n4AGcEqYp', 'fabnct', '-50999821', '17349.85'),
('2022-01-21 08:41:50', 'Nlpz1j3h', 'dzytua', '-60162', '287.06'),
('2022-01-30 23:44:55', '', 'slfght', '62891747919627339', '8014.98'),
('2022-01-18 19:14:28', 'z6', 'dzytua', '-1113001726', '73258.24'),
('2022-01-30 14:54:59', 'z6', 'udtmfp', '111175577438857975', '-15280.41'),
('2022-01-08 22:08:26', 'z6', 'ympyls', '3', '2.07'),
('2022-01-03 08:17:29', 'Nlpz1j3h', 'udtmfp', '-234492', '217.58'),
('2022-01-27 07:28:47', 'Pc', 'cawanm', '-1015', '-20631.50'),
('2022-01-17 14:07:47', 'Nlpz1j3h', 'lbsvqu', '2295574006197343179', '93768.75'),
('2022-01-31 14:00:12', 'onqR3JsK1', 'umlkpo', '-227', '-66199.05'),
('2022-01-05 20:31:26', '65', 'lbsvqu', '684307', '36412.49'),
('2022-01-06 00:51:34', 'z6', 'dzytua', '11700309310', '-26064.10'),
('2022-01-26 02:59:00', 'n4AGcEqYp', 'slfght', '-15320250288446', '-58003.69'),
('2022-01-05 03:26:26', 'z6', 'cawanm', '19841055192960542', '-5634.36'),
('2022-01-17 08:51:23', 'Pc', 'ghftus', '35476438804110', '13625.99'),
('2022-01-30 18:56:03', 'n4AGcEqYp', 'lbsvqu', '3303892099598', '8.37'),
('2022-01-22 14:17:18', 'i66lt', 'umlkpo', '-27653110', '-82306.25'),
('2022-01-02 10:25:01', 'qQ', 'ghftus', '-188567166', '71442.87'),
('2022-01-30 04:58:14', 'Pc', 'ympyls', '-9983', '-82071.59'),
('2022-01-05 00:16:56', '7Bh', 'hhbawx', '43712', '84762.97'),
('2022-01-25 03:25:53', '65', 'mtrtzf', '4604107', '-2434.69'),
('2022-01-27 21:09:10', '65', 'udtmfp', '476134823953365199', '38736.04'),
('2022-01-11 13:35:44', '65', 'qmwhvr', '1', '0.28'),
('2022-01-03 19:13:07', '', 'lbsvqu', '11', '-53084.04'),
('2022-01-20 02:27:25', 'i66lt', 'umlkpo', '3218824416', '-71393.20'),
('2022-01-04 04:52:36', '7Bh', 'ghftus', '-112543071', '-78377.93'),
('2022-01-27 18:27:06', 'Pc', 'umlkpo', '477', '-98060.13'),
('2022-01-04 19:40:36', '', 'udtmfp', '433677211', '-99829.94'),
('2022-01-20 23:19:58', 'Nlpz1j3h', 'udtmfp', '361394977', '-19284.18'),
('2022-01-05 02:17:56', 'Pc', 'oqkeun', '-552390906075744662', '-25267.92'),
('2022-01-02 16:14:07', '65', 'dzytua', '132', '2393.77'),
('2022-01-28 23:17:14', 'z6', 'umlkpo', '61', '-52028.57'),
('2022-01-12 08:05:44', 'qQ', 'hhbawx', '-9579605666539132', '-87801.81'),
('2022-01-31 19:48:22', 'z6', 'lbsvqu', '9883530877822', '34006.42'),
('2022-01-11 20:38:41', '', 'piszhr', '56108215256366', '-74059.80'),
('2022-01-01 04:15:17', '65', 'cawanm', '-440061829443010909', '88960.51'),
('2022-01-05 07:26:09', 'qQ', 'umlkpo', '-24889917494681901', '-23372.12'),
('2022-01-29 18:13:55', 'Nlpz1j3h', 'cawanm', '-233', '-24294.42'),
('2022-01-10 00:49:45', 'Nlpz1j3h', 'ympyls', '-2396341', '77723.88'),
('2022-01-29 08:02:58', 'n4AGcEqYp', 'slfght', '45212', '93099.78'),
('2022-01-28 08:59:21', 'onqR3JsK1', 'oqkeun', '76', '-78641.65'),
('2022-01-26 14:29:39', '7Bh', 'umlkpo', '176003552517', '-99999.96'),
('2022-01-03 18:53:37', '7Bh', 'piszhr', '3906151622605106', '55723.01'),
('2022-01-04 07:08:19', 'i66lt', 'ympyls', '-240097380835621', '-81800.87'),
('2022-01-28 14:54:17', 'Nlpz1j3h', 'slfght', '-69018069110121', '90533.64'),
('2022-01-22 07:48:53', 'Pc', 'ympyls', '22396835447981344', '-12583.39'),
('2022-01-22 07:39:29', 'Pc', 'uqkghp', '10551305', '52163.82'),
('2022-01-08 22:39:47', 'Nlpz1j3h', 'cawanm', '67905472699', '87831.30'),
('2022-01-05 14:53:34', '7Bh', 'dzytua', '-779598598706906834', '-38780.41'),
('2022-01-30 17:34:41', 'onqR3JsK1', 'oqkeun', '346687625005524', '-62475.31'),
('2022-01-29 12:14:06', '', 'qmwhvr', '3315', '22076.88'),
('2022-01-05 06:47:04', 'Nlpz1j3h', 'udtmfp', '-469', '42747.17'),
('2022-01-19 15:20:20', '7Bh', 'lbsvqu', '347317095885', '-76393.49'),
('2022-01-08 16:18:22', 'z6', 'fghmcd', '2', '90315.60'),
('2022-01-02 00:23:06', 'Pc', 'piszhr', '-3651517384168400', '58220.34'),
('2022-01-12 08:23:31', 'onqR3JsK1', 'udtmfp', '5636394870355729225', '33224.25'),
('2022-01-28 10:46:44', 'onqR3JsK1', 'oqkeun', '-28102078612755', '6469.53'),
('2022-01-23 23:16:11', 'onqR3JsK1', 'ghftus', '-707475035515433949', '63422.66'),
('2022-01-03 05:32:31', 'z6', 'hhbawx', '-45', '-49680.52'),
('2022-01-27 03:24:33', 'qQ', 'qmwhvr', '375943906057539870', '-66092.96'),
('2022-01-25 20:07:22', '7Bh', 'slfght', '1', '72440.21'),
('2022-01-04 16:07:24', 'qQ', 'uqkghp', '751213107482249', '16417.31'),
('2022-01-23 19:22:00', 'Pc', 'hhbawx', '-740731249600493', '88439.40'),
('2022-01-05 09:04:20', '7Bh', 'cawanm', '23602', '302.44');
Query examples
The statistics of query cache-related metrics in this section are examples and are for reference only.
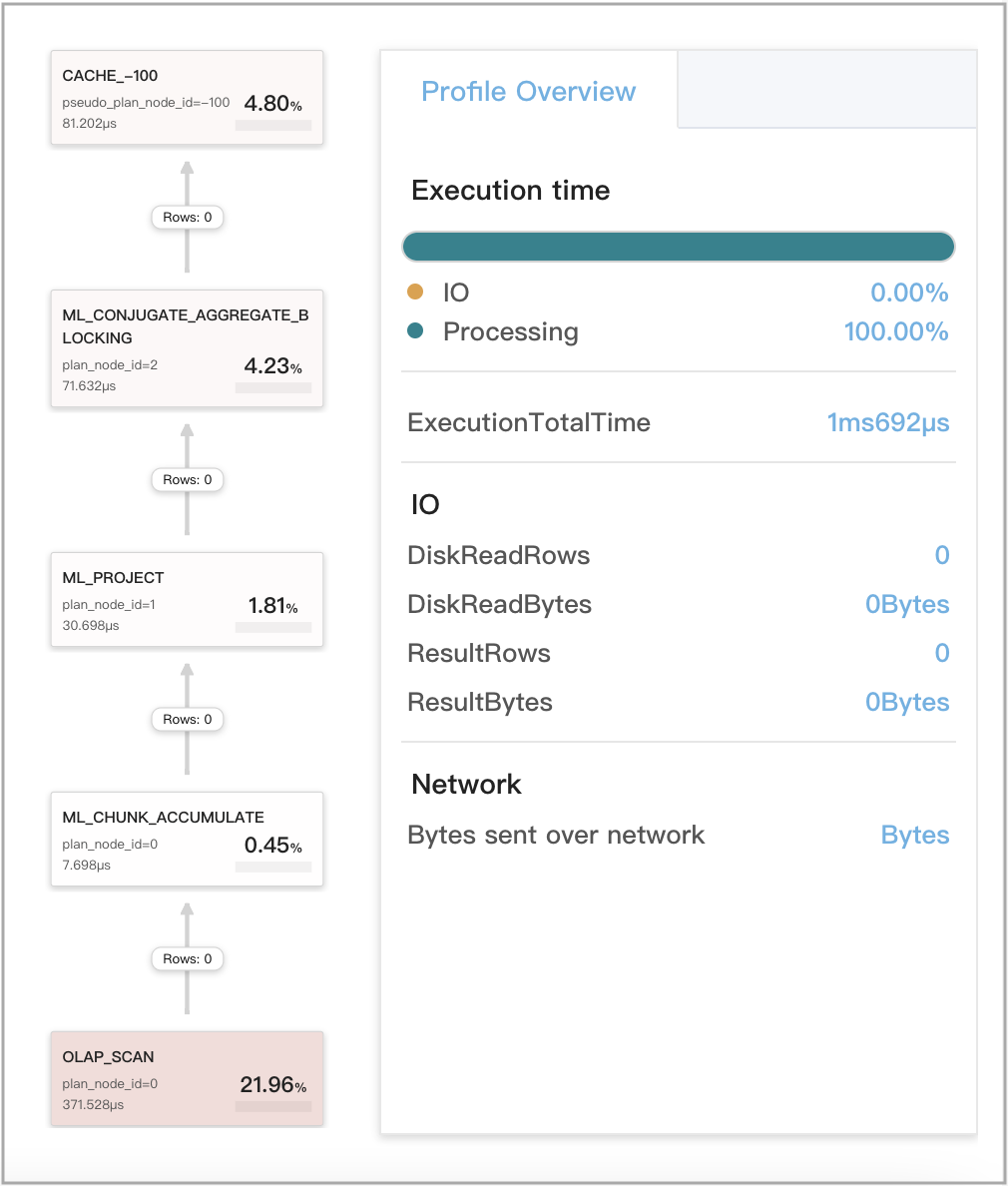
Query cache works for local aggregations at stage 1
This includes three situations:
- The query accesses only a single tablet.
- The query accesses multiple tablets from multiple partitions of a table that itself comprises a colocated group, and data does not need to be shuffled for aggregations.
- The query accesses multiple tablets from the same partition of a table, and data does not need to be shuffled for aggregations.
Query example:
SELECT
date_trunc('hour', ts) AS hour,
k0,
sum(v1) AS __c_0
FROM
t0
WHERE
ts between '2022-01-03 00:00:00'
and '2022-01-03 23:59:59'
GROUP BY
date_trunc('hour', ts),
k0
The following figure shows the query cache-related metrics in the query profile.
Query cache does not work for remote aggregations at stage 1
When aggregations on multiple tablets are forcibly performed at stage 1, data is first shuffled and then aggregated.
Query example:
SET new_planner_agg_stage = 1;
SELECT
date_trunc('hour', ts) AS hour,
v0 % 2 AS is_odd,
sum(v1) AS __c_0
FROM
t0
WHERE
ts between '2022-01-03 00:00:00'
and '2022-01-03 23:59:59'
GROUP BY
date_trunc('hour', ts),
is_odd
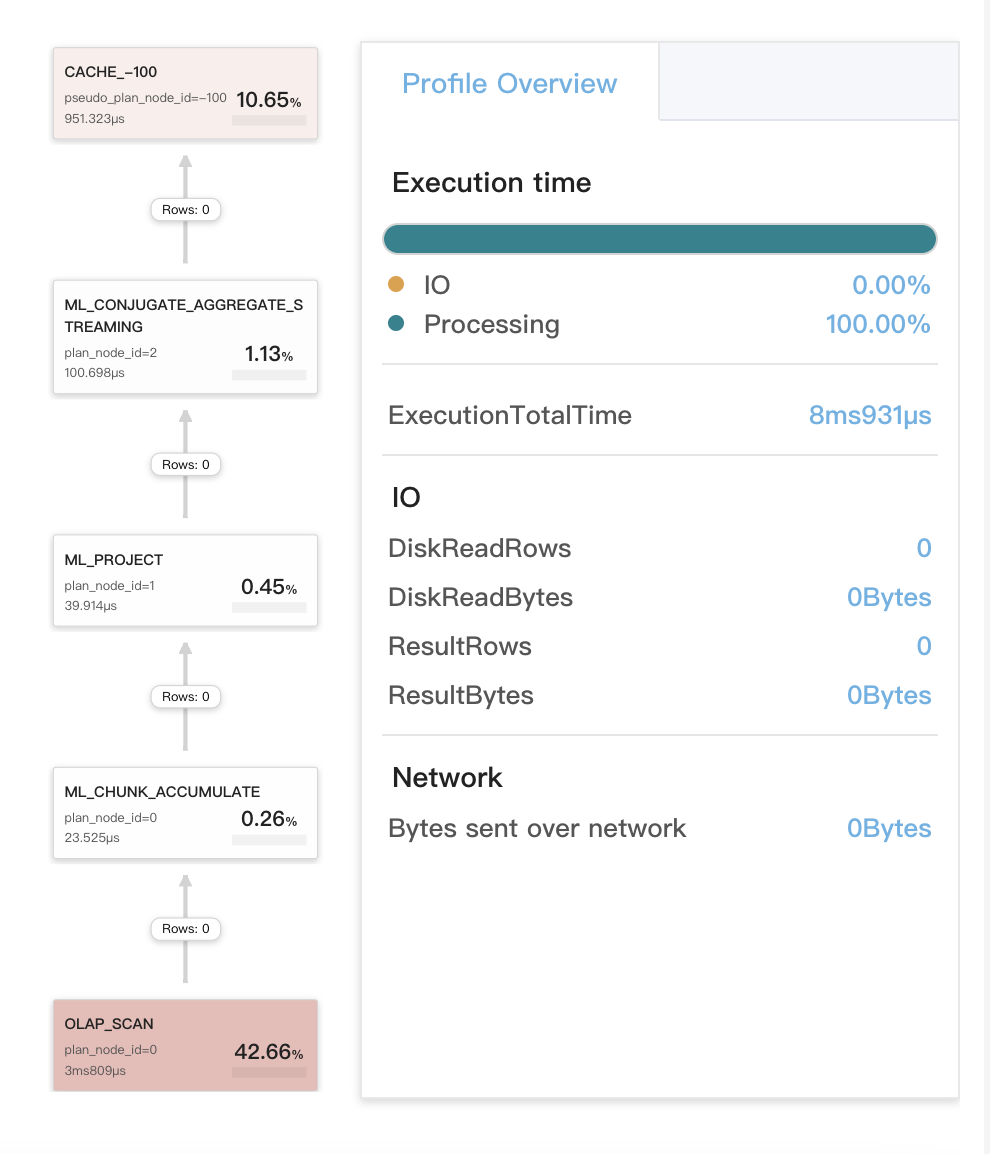
Query cache works for local aggregations at stage 2
This includes three situations:
- The aggregations at stage 2 of the query are compiled to compare the same type of data. The first aggregation is a local aggregation. After the first aggregation is complete, the results generated from the first aggregation are computed to perform a second aggregation, which is a global aggregation.
- The query is a SELECT DISTINCT query.
- The query includes one of the following DISTINCT aggregate functions:
sum(distinct),count(distinct), andavg(distinct). In most cases, aggregations are performed at stage 3 or 4 for such a query. However, you can runset new_planner_agg_stage = 1to forcibly perform aggregations at stage 2 for the query. If the query containsavg(distinct)and you want to perform aggregations at stage, you also need to runset cbo_cte_reuse = falseto disable CTE optimizations.
Query example:
SELECT
date_trunc('hour', ts) AS hour,
v0 % 2 AS is_odd,
sum(v1) AS __c_0
FROM
t0
WHERE
ts between '2022-01-03 00:00:00'
and '2022-01-03 23:59:59'
GROUP BY
date_trunc('hour', ts),
is_odd
The following figure shows the query cache-related metrics in the query profile.
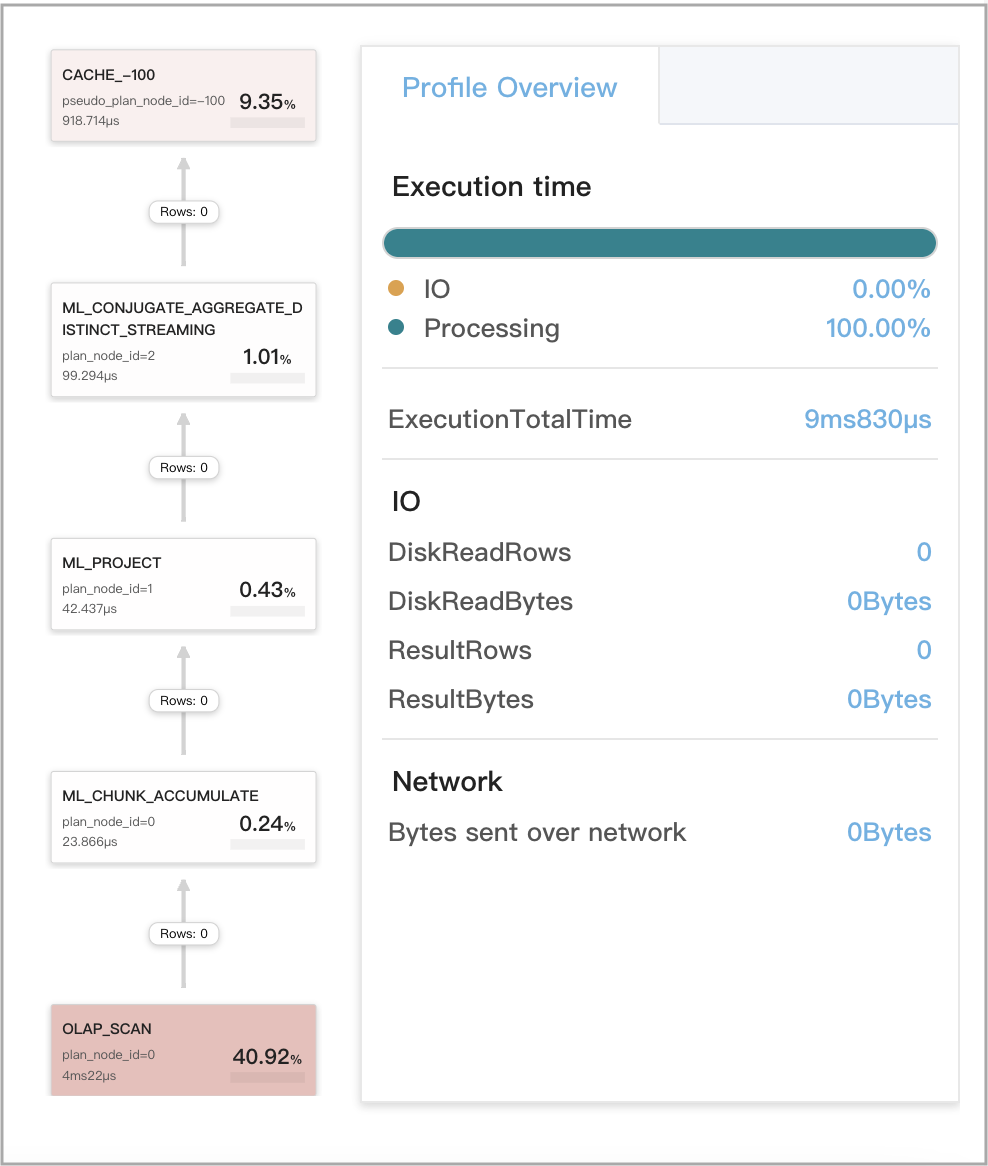
Query cache works for local aggregations at stage 3
The query is a GROUP BY aggregate query that includes a single DISTINCT aggregate function.
The supported DISTINCT aggregate functions are sum(distinct), count(distinct), and avg(distinct).
NOTICE
If the query includes
avg(distinct), you also need to runset cbo_cte_reuse = falseto disable CTE optimizations.
Query example:
SELECT
date_trunc('hour', ts) AS hour,
v0 % 2 AS is_odd,
sum(distinct v1) AS __c_0
FROM
t0
WHERE
ts between '2022-01-03 00:00:00'
and '2022-01-03 23:59:59'
GROUP BY
date_trunc('hour', ts),
is_odd;
The following figure shows the query cache-related metrics in the query profile.
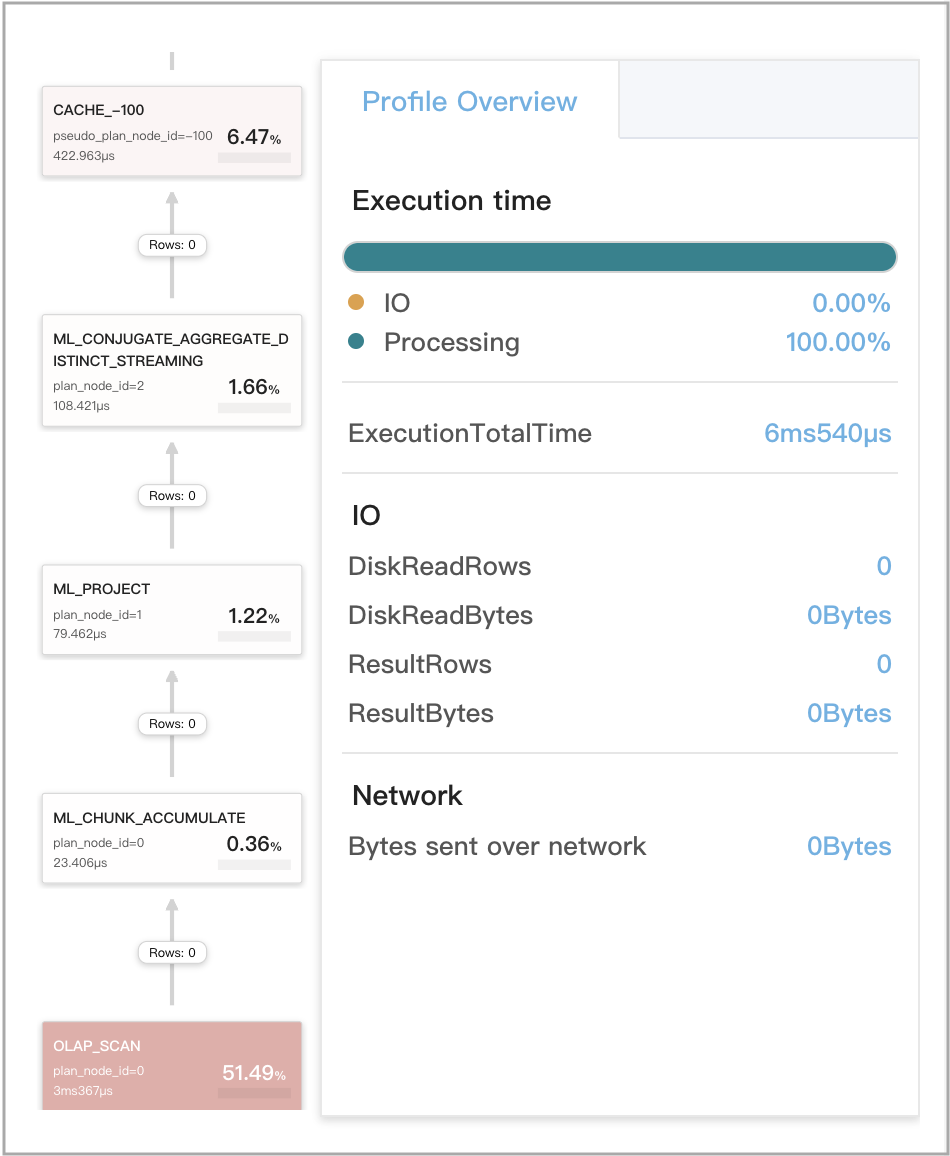
Query cache works for local aggregations at stage 4
The query is a non-GROUP BY aggregate query that includes a single DISTINCT aggregate function. Such queries include classical queries that remove deduplicate data.
Query example:
SELECT
count(distinct v1) AS __c_0
FROM
t0
WHERE
ts between '2022-01-03 00:00:00'
and '2022-01-03 23:59:59'
The following figure shows the query cache-related metrics in the query profile.
Cached results are reused for two queries whose first aggregations are semantically equivalent
Use the following two queries, Q1 and Q2, as an example. Q1 and Q2 both include multiple aggregations, but their first aggregations are semantically equivalent. Therefore, Q1 and Q2 are evaluated as semantically equivalent, and can reuse each other's computation results saved in the query cache.
-
Q1
SELECT
(
ifnull(sum(murmur_hash3_32(hour)), 0) + ifnull(sum(murmur_hash3_32(k0)), 0) + ifnull(sum(murmur_hash3_32(__c_0)), 0)
) AS fingerprint
FROM
(
SELECT
date_trunc('hour', ts) AS hour,
k0,
sum(v1) AS __c_0
FROM
t0
WHERE
ts between '2022-01-03 00:00:00'
and '2022-01-03 23:59:59'
GROUP BY
date_trunc('hour', ts),
k0
) AS t; -
Q2
SELECT
date_trunc('hour', ts) AS hour,
k0,
sum(v1) AS __c_0
FROM
t0
WHERE
ts between '2022-01-03 00:00:00'
and '2022-01-03 23:59:59'
GROUP BY
date_trunc('hour', ts),
k0
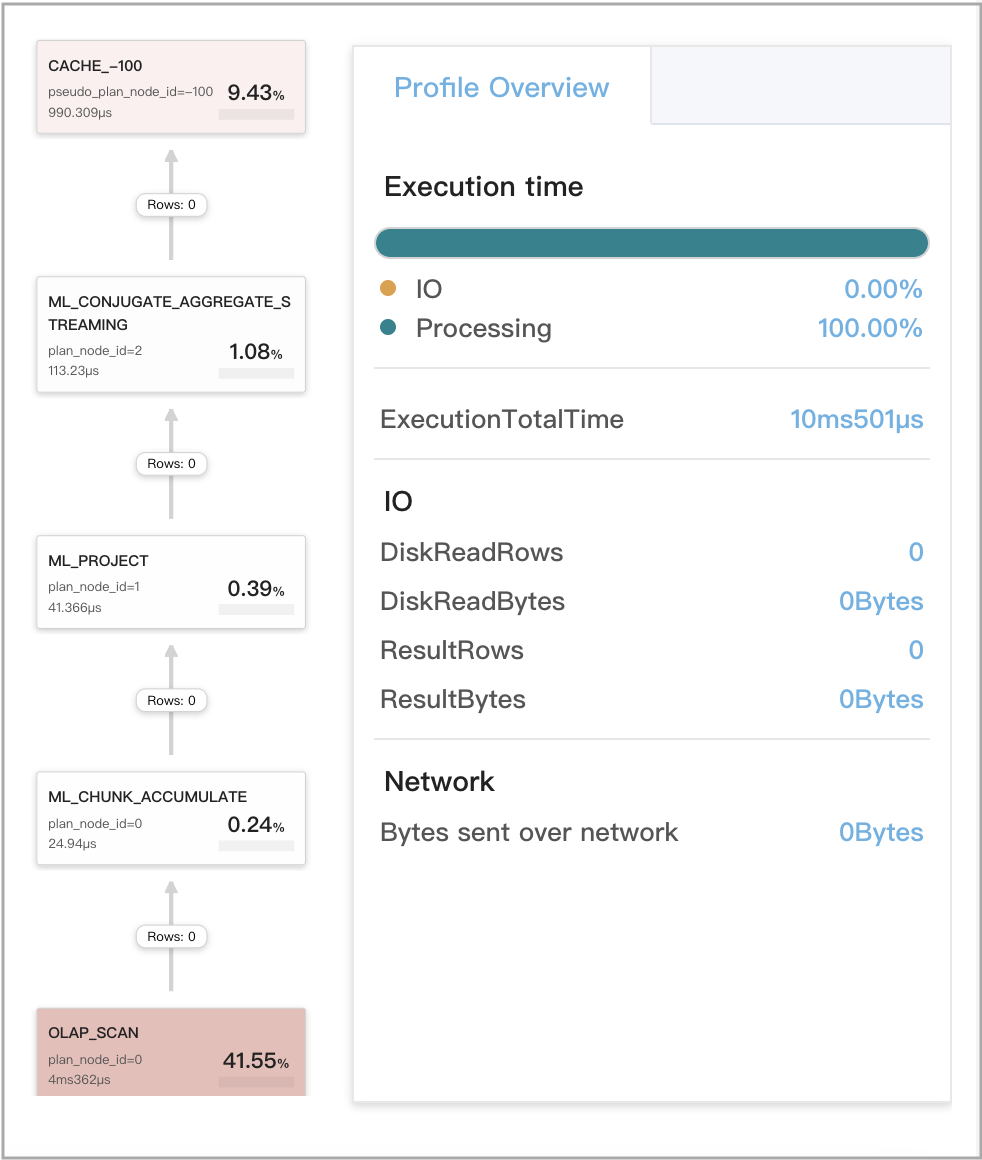
The following figure shows the CachePopulate metrics for Q1.
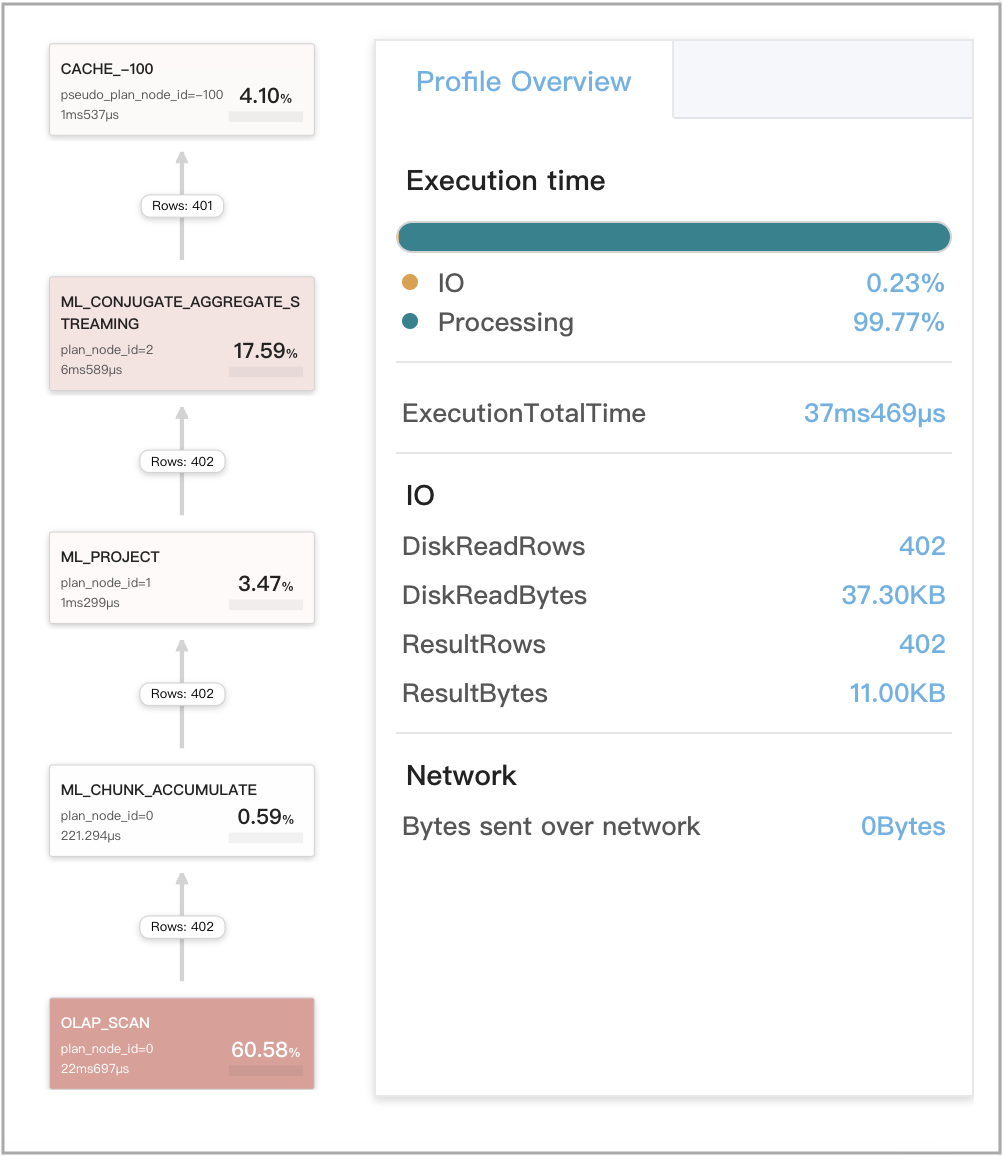
The following figure shows the CacheProbe metrics for Q2.
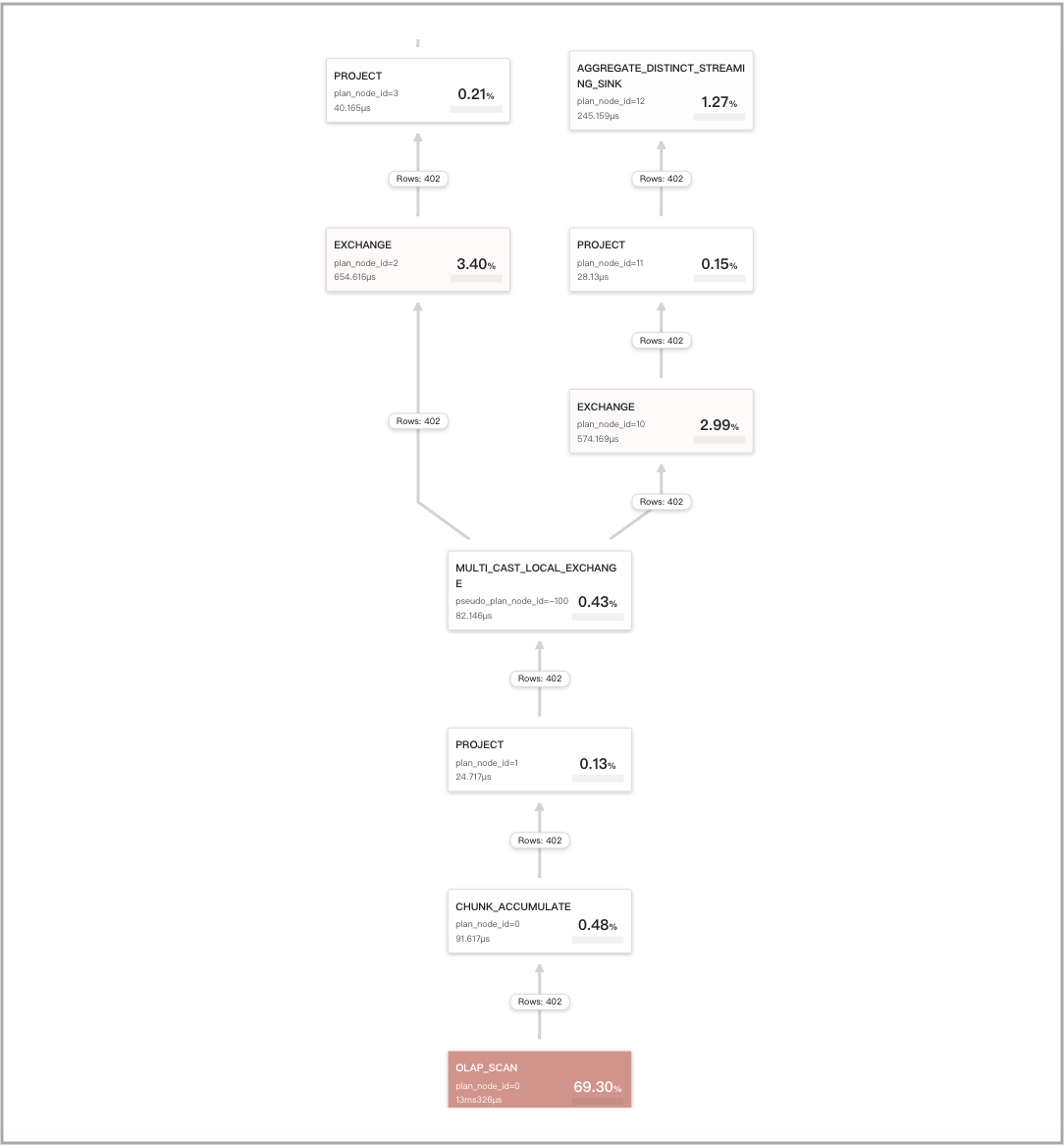
Query cache does not work for DISTINCT queries for which CTE optimizations are enabled
After you run set cbo_cte_reuse = true to enable CTE optimizations, the computation results for specific queries that include DISTINCT aggregate functions cannot be cached. A few examples are as follows:
-
The query contains a single DISTINCT aggregate function
avg(distinct):SELECT
avg(distinct v1) AS __c_0
FROM
t0
WHERE
ts between '2022-01-03 00:00:00'
and '2022-01-03 23:59:59';
-
The query contains multiple DISTINCT aggregate functions that reference the same column:
SELECT
avg(distinct v1) AS __c_0,
sum(distinct v1) AS __c_1,
count(distinct v1) AS __c_2
FROM
t0
WHERE
ts between '2022-01-03 00:00:00'
and '2022-01-03 23:59:59';

-
The query contains multiple DISTINCT aggregate functions that each reference a different column:
SELECT
sum(distinct v1) AS __c_1,
count(distinct v0) AS __c_2
FROM
t0
WHERE
ts between '2022-01-03 00:00:00'
and '2022-01-03 23:59:59';

Best practices
When you create your table, specify a reasonable partition description and a reasonable distribution method, including:
- Choose a single DATE-type column as the partition column. If the table contains more than one DATE-type column, choose the column whose values roll forward as data is incrementally ingested and that is used to define your interesting time ranges of queries.
- Choose a proper partition width. The data ingested most recently may modify the latest partitions of the table. Therefore, the cache entries involving the latest partitions are unstable and are apt to be invalidated.
- Specify a bucket number that is several dozen in the distribution description of the table creation statement. If the bucket number is exceedingly small, the query cache cannot take effect when the number of tablets that need to be processed by the BE is less than the value of
pipeline_dop.
