S3 Load
从 AWS S3 导入
StarRocks 支持通过以下方式从 AWS S3 导入数据:
- 使用 INSERT+
FILES()进行同步导入。 - 使用 Broker Load 进行异步导入。
- 使用 Pipe 进行持续的异步导入。
三种导入方式各有优势,具体将在下面分章节详细阐述。
一般情况下,建议您使用 INSERT+FILES(),更为方便易用。
但是,INSERT+FILES() 当前只支持 Parquet、ORC 和 CSV 文件格式。因此,如果您需要导入其他格式(如 JSON)的数据、或者需要在导入过程中执行 DELETE 等数据变更操作,可以使用 Broker Load。
如果需要导入超大数据(比如超过 100 GB、特别是 1 TB 以上的数据量),建议您使用 Pipe。Pipe 会按文件数量或大小,自动对�目录下的文件进行拆分,将一个大的导入作业拆分成多个较小的串行的导入任务,从而降低出错重试的代价。另外,在进行持续性的数据导入时,也推荐使用 Pipe,它能监听远端存储目录的文件变化,并持续导入有变化的文件数据。
准备工作
准备数据源
确保待导入数据已保存在 S3 存储桶。建议您将数据保存在与 StarRocks 集群同处一个地域(Region)的 S3 存储桶,这样可以降低数据传输成本。
本文中,我们提供了样例数据集 s3://starrocks-examples/user-behavior-10-million-rows.parquet,对所有合法的 AWS 用户开放。您只要配置真实有效的安全凭证,即可访问该数据集。
查看权限
导入操作需要目标表的 INSERT 权限。如果您的用户账号没有 INSERT 权限,请参考 GRANT 给用户赋权,语法为 GRANT INSERT ON TABLE <table_name> IN DATABASE <database_name> TO { ROLE <role_name> | USER <user_identity>}。
获取资源访问配置
本文的示例均使用基于 IAM User 的认证方式。为确保您能够顺利访问存储在 AWS S3 中的数据,建议您根据“基于 IAM User 认证鉴权中介绍的准备工作,创建 IAM User、并配置 IAM 策略。
概括来说,如果选择使用基于 IAM User 的认证方式,您需要提前获取以下 AWS 资源信息:
- 数据所在的S3 存储桶
- S3 对象键(或“对象名称”)(只在访问 S3 存储桶中某个特定数据对象时才需要。注意,如果要访问的数据对象保存在子文件夹下,其名称可以包含前缀。)
- S3 存储桶所在的 AWS 地域(Region)
- 作为访问凭证的 Access Key 和 Secret Key
有关 StarRocks 支持的其他认证方式,参见配置 AWS 认证信息。
通过 INSERT+FILES() 导入
该特性从 3.1 版本起支持。当前只支持 Parquet、ORC 和 CSV(自 v3.3.0 起)文件格式。
INSERT+FILES() 优势
FILES() 会根据给定的数据路径等参数读取数据,并自动根据数据文件的格式、列信息等推断出表结构,最终以数据行的形式返回文件中的数据。
通过 FILES(),您可以:
- 使用 SELECT 语句直接从 AWS S3 查询数据。
- 通过 CREATE TABLE AS SELECT(简称 CTAS)语句实现自动建表和导入数据。
- 手动建表,然后通过 INSERT 导入数据。
操作示例
通过 SELECT 直接查询数据
您可以通过 SELECT+FILES() 直接查询 AWS S3 里的数据,从而在建表前对待导入数据有一个整体的了解,其优势包括:
- 您不需要存储数据就可以对其进行查看。
- 您可以查看数据的最大值、最小值,并确定需要使用哪些数据类型。
- 您可以检查数据中是否包含
NULL值。
例如,查询样例数据集 s3://starrocks-examples/user-behavior-10-million-rows.parquet 中的数据:
SELECT * FROM FILES
(
"path" = "s3://starrocks-examples/user-behavior-10-million-rows.parquet",
"format" = "parquet",
"aws.s3.region" = "us-east-1",
"aws.s3.access_key" = "AAAAAAAAAAAAAAAAAAAA",
"aws.s3.secret_key" = "BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB"
)
LIMIT 3;
说明
把上面命令示例中的
AAA和BBB替换成真实有效的 Access Key 和 Secret Key 作为访问凭证。由于这里使用的数据对象对所有合法的 AWS 用户开放,因此您填入任何真实有效的 Access Key 和 Secret Key 都可以。
系统返回如下查询结果:
+--------+---------+------------+--------------+---------------------+
| UserID | ItemID | CategoryID | BehaviorType | Timestamp |
+--------+---------+------------+--------------+---------------------+
| 543711 | 829192 | 2355072 | pv | 2017-11-27 08:22:37 |
| 543711 | 2056618 | 3645362 | pv | 2017-11-27 10:16:46 |
| 543711 | 1165492 | 3645362 | pv | 2017-11-27 10:17:00 |
+--------+---------+------------+--------------+---------------------
说明
以上返回结果中的列名是源 Parquet 文件中定义的列名。
通过 CTAS 自动建表并导入数据
该示例是上一个示例的延续。该示例中,通过在 CREATE TABLE AS SELECT (CTAS) 语句中嵌套上一个示例中的 SELECT 查询,StarRocks 可以自动推断表结构、创建表、并把数据导入新建的表中。Parquet 格式的文件自带�列名和数据类型,因此您不需要指定列名或数据类型。
说明
使用表结构推断功能时,CREATE TABLE 语句不支持设置副本数,因此您需要在建表前把副本数设置好。例如,您可以通过如下命令设置副本数为
1:ADMIN SET FRONTEND CONFIG ('default_replication_num' = "1");
通过如下语句创建数据库、并切换至该数据库:
CREATE DATABASE IF NOT EXISTS mydatabase;
USE mydatabase;
通过 CTAS 自动创建表、并把样例数据集 s3://starrocks-examples/user-behavior-10-million-rows.parquet 中的数据导入到新建表中:
CREATE TABLE user_behavior_inferred AS
SELECT * FROM FILES
(
"path" = "s3://starrocks-examples/user-behavior-10-million-rows.parquet",
"format" = "parquet",
"aws.s3.region" = "us-east-1",
"aws.s3.access_key" = "AAAAAAAAAAAAAAAAAAAA",
"aws.s3.secret_key" = "BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB"
);
说明
把上面命令示例中的
AAA和BBB替换成真实有效的 Access Key 和 Secret Key 作为访问凭证。由于这里使用的数据对象对所有合法的 AWS 用户开放,因此您填入任何真实有效的 Access Key 和 Secret Key 都可以。
建表完成后,您可以通过 DESCRIBE 查看新建表的表结构:
DESCRIBE user_behavior_inferred;
系统返回如下查询结果:
+--------------+------------------+------+-------+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------------+------------------+------+-------+---------+-------+
| UserID | bigint | YES | true | NULL | |
| ItemID | bigint | YES | true | NULL | |
| CategoryID | bigint | YES | true | NULL | |
| BehaviorType | varchar(1048576) | YES | false | NULL | |
| Timestamp | varchar(1048576) | YES | false | NULL | |
+--------------+------------------+------+-------+---------+-------+
您可以查询新建表中的数据,验证数据已成功导入。例如:
SELECT * from user_behavior_inferred LIMIT 3;
系统返回如下查询结果,表明数据已成功导入:
+--------+---------+------------+--------------+---------------------+
| UserID | ItemID | CategoryID | BehaviorType | Timestamp |
+--------+---------+------------+--------------+---------------------+
| 225586 | 3694958 | 1040727 | pv | 2017-12-01 00:58:40 |
| 225586 | 3726324 | 965809 | pv | 2017-12-01 02:16:02 |
| 225586 | 3732495 | 1488813 | pv | 2017-12-01 00:59:46 |
+--------+---------+------------+--------------+---------------------+
手动建表并通过 INSERT 导入数据
在实际业务场景中,您可能需要自定义目标表的表结构,包括:
- 各列的数据类型和默认值、以及是否允许
NULL值 - 定义哪些列作为键、以及这些列的数据类型
- 数据分区分桶
说明
要实现高效的表结构设计,您需要深度了解表中数据的用途、以及表中各列的内容。本文不对表设计做过多赘述,有关表设计的详细信息,参见表设计。
该示例主要演示如何根据源 Parquet 格式文件中数据的特点、以及目标表未来的查询用途等对目标表进行定义和创建。在创建表之前,您可以先查看一下保存在 AWS S3 中的源文件,从而了解源文件中数据的特点,例如:
- 源文件中包含一个数据类型为 VARCHAR 的
Timestamp列,并且 StarRocks 将 VARCHAR 数据类型转换为 DATETIME 数据类型,因此建表语句中会定义一个数据类型为 DATETIME 的Timestamp列。 - 源文件中的数据中没有
NULL值,因此建表语句中也不需要定义任何列为允许NULL值。 - 根据未来的查询类型,建表语句中会定义
UserID列为排序键和分桶键。根据实际业务场景需要,您还可��以定义其他列比如ItemID或者定义UserID与其他列的组合作为排序键。
通过如下语句创建数据库、并切换至该数据库:
CREATE DATABASE IF NOT EXISTS mydatabase;
USE mydatabase;
通过如下语句手动创建表:
CREATE TABLE user_behavior_declared
(
UserID int(11),
ItemID int(11),
CategoryID int(11),
BehaviorType varchar(65533),
Timestamp datetime
)
ENGINE = OLAP
DUPLICATE KEY(UserID)
DISTRIBUTED BY HASH(UserID);
通过 DESCRIBE 查看新建表的表结构:
DESCRIBE user_behavior_declared;
+--------------+----------------+------+-------+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------------+----------------+------+-------+---------+-------+
| UserID | int | YES | true | NULL | |
| ItemID | int | YES | false | NULL | |
| CategoryID | int | YES | false | NULL | |
| BehaviorType | varchar(65533) | YES | false | NULL | |
| Timestamp | datetime | YES | false | NULL | |
+--------------+----------------+------+-------+---------+-------+
5 rows in set (0.00 sec)
您可以从以下几个方面来对比手动建表的表结构与 FILES() 函数自动推断出来的表结构之间具体有哪些不同:
- 数据类型
- 是否允许
NULL值 - 定义为键的字段
在生产环境中,为更好地控制目标表的表结构、实现更高的查询性能,建议您手动创建表、指定表结构。
建表完成后,您可以通过 INSERT INTO SELECT FROM FILES() 向表内导入数据:
INSERT INTO user_behavior_declared
SELECT * FROM FILES
(
"path" = "s3://starrocks-examples/user-behavior-10-million-rows.parquet",
"format" = "parquet",
"aws.s3.region" = "us-east-1",
"aws.s3.access_key" = "AAAAAAAAAAAAAAAAAAAA",
"aws.s3.secret_key" = "BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB"
);
说明
把上面命令示例中的
AAA和BBB替换成真实有效的 Access Key 和 Secret Key 作为访问凭证。由于这里使用的数据对象对所有合法的 AWS 用户开放,因此您填入任何真实有效的 Access Key 和 Secret Key 都可以。
导入完成后,您可以查询新建表中的数据,验证数据已成功导入。例如:
SELECT * from user_behavior_declared LIMIT 3;
系统返回如下查询结果,表明数据已成功导入:
+--------+---------+------------+--------------+---------------------+
| UserID | ItemID | CategoryID | BehaviorType | Timestamp |
+--------+---------+------------+--------------+---------------------+
| 393529 | 3715112 | 883960 | pv | 2017-12-02 02:45:44 |
| 393529 | 2650583 | 883960 | pv | 2017-12-02 02:45:59 |
| 393529 | 3715112 | 883960 | pv | 2017-12-02 03:00:56 |
+--------+---------+------------+--------------+---------------------+
查看导入进度
通过 StarRocks Information Schema 库中的 loads 视图查看导入作业的进度。该功能自 3.1 版本起支持。例如:
SELECT * FROM information_schema.loads ORDER BY JOB_ID DESC;
有关 loads 视图提供的字段详情,参见 loads。
如果您提交了多个导入作业,您可以通过 LABEL 过滤出想要查看的作业。例如:
SELECT * FROM information_schema.loads WHERE LABEL = 'insert_e3b882f5-7eb3-11ee-ae77-00163e267b60' \G
*************************** 1. row ***************************
JOB_ID: 10243
LABEL: insert_e3b882f5-7eb3-11ee-ae77-00163e267b60
DATABASE_NAME: mydatabase
STATE: FINISHED
PROGRESS: ETL:100%; LOAD:100%
TYPE: INSERT
PRIORITY: NORMAL
SCAN_ROWS: 10000000
FILTERED_ROWS: 0
UNSELECTED_ROWS: 0
SINK_ROWS: 10000000
ETL_INFO:
TASK_INFO: resource:N/A; timeout(s):300; max_filter_ratio:0.0
CREATE_TIME: 2023-11-09 11:56:01
ETL_START_TIME: 2023-11-09 11:56:01
ETL_FINISH_TIME: 2023-11-09 11:56:01
LOAD_START_TIME: 2023-11-09 11:56:01
LOAD_FINISH_TIME: 2023-11-09 11:56:44
JOB_DETAILS: {"All backends":{"e3b882f5-7eb3-11ee-ae77-00163e267b60":[10142]},"FileNumber":0,"FileSize":0,"InternalTableLoadBytes":311710786,"InternalTableLoadRows":10000000,"ScanBytes":581574034,"ScanRows":10000000,"TaskNumber":1,"Unfinished backends":{"e3b882f5-7eb3-11ee-ae77-00163e267b60":[]}}
ERROR_MSG: NULL
TRACKING_URL: NULL
TRACKING_SQL: NULL
REJECTED_RECORD_PATH: NULL
NOTE
由于 INSERT 语句是一个同步命令,因此,如果作业还在运行当中,您需要打开另一个会话来查看 INSERT 作业的执行情况。
通过 Broker Load 导入
作为一种异步的导入方式,Broker Load 负责建立与 AWS S3 的连接、拉取数据、并将数据存储到 StarRocks 中。
当前支持以下文件格式:
- Parquet
- ORC
- CSV
- JSON(自 3.2.3 版本起支持)
Broker Load 优势
- Broker Load 在后台运行,客户端不需要保持连接也能确保导入作业不中断。
- Broker Load 作业默认超时时间为 4 小时,适合导入数据较大、导入运行时间较长的场景。
- 除 Parquet 和 ORC 文件格式,Broker Load 还支持 CSV 文件格式和 JSON 文件格式(JSON 文件格式自 3.2.3 版本起支持)。
工作原理
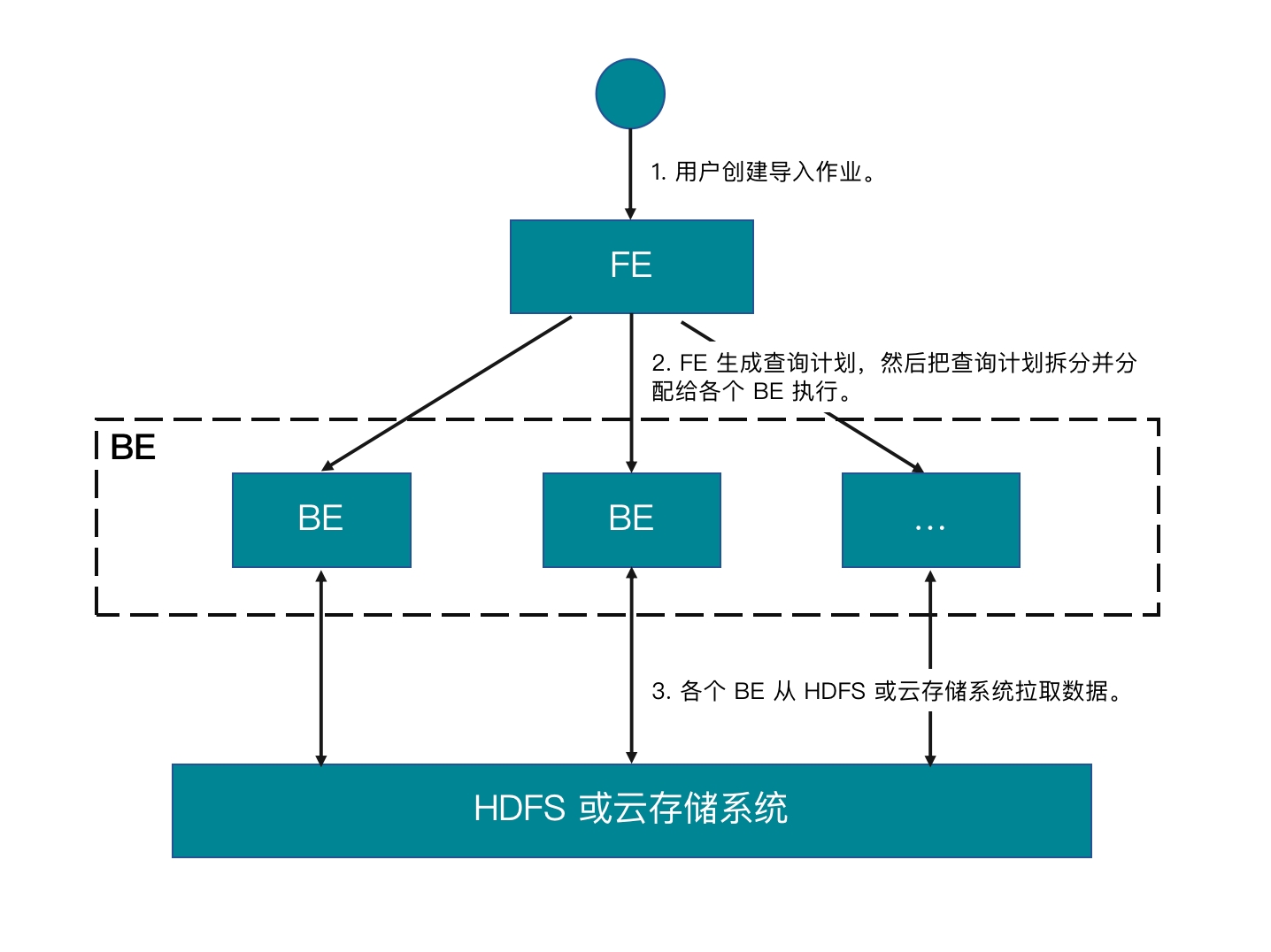
- 用户创建导入作业。
- FE 生成查询计划,然后把查询计划拆分并分分配给各个 BE(或 CN)执行。
- 各个 BE(或 CN)从数据源拉取数据并把数据导入到 StarRocks 中。
操作示例
创建 StarRocks 表,启动导入作业从 AWS S3 拉取样例数据集 s3://starrocks-examples/user-behavior-10-million-rows.parquet 的数据,然后验证导入过程和结果是否成功。
建库建表
通过如下语句创建数据库、并切换至该数据库:
CREATE DATABASE IF NOT EXISTS mydatabase;
USE mydatabase;
通过如下语句手动创建表(建议表结构与您在 AWS S3 存储的待导入数据结构一致):
CREATE TABLE user_behavior
(
UserID int(11),
ItemID int(11),
CategoryID int(11),
BehaviorType varchar(65533),
Timestamp datetime
)
ENGINE = OLAP
DUPLICATE KEY(UserID)
DISTRIBUTED BY HASH(UserID);
提交导入作业
执行如下命令创建 Broker Load 作业,把样例数据集 s3://starrocks-examples/user-behavior-10-million-rows.parquet 中的数据导入到表 user_behavior中:
LOAD LABEL user_behavior
(
DATA INFILE("s3://starrocks-examples/user-behavior-10-million-rows.parquet")
INTO TABLE user_behavior
FORMAT AS "parquet"
)
WITH BROKER
(
"aws.s3.enable_ssl" = "true",
"aws.s3.use_instance_profile" = "false",
"aws.s3.region" = "us-east-1",
"aws.s3.access_key" = "AAAAAAAAAAAAAAAAAAAA",
"aws.s3.secret_key" = "BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB"
)
PROPERTIES
(
"timeout" = "72000"
);
说明
把上面命令示例中的
AAA和BBB替换成真实有效的 Access Key 和 Secret Key 作为访问凭证。由于这里使用的数据对象对所有合法的 AWS 用户开放,因此您填入任何真实有效的 Access Key 和 Secret Key 都可以。
导入语句包含四个部分:
LABEL:导入作业的标签,字符串类型,可用于查询导入作业的状态。LOAD声明:包括源数据文件所在的 URI、源数据文件的格式、以及目标表的名称等作业描述信息。BROKER:连接数据源的认证信息配置。PROPERTIES:用于指定超时时间等可选的作业属性。
有关详细的语法和参数说明,参见 BROKER LOAD。
查看导入进度
通过 StarRocks Information Schema 库中的 loads 视图查看导入作业的进度。该功能自 3.1 版本起支持。
SELECT * FROM information_schema.loads WHERE LABEL = 'user_behavior';
有关 loads 视图提供的字段详情,参见 loads。
系统返回如下结果,作业状态为 LOADING,进度为 39%。您可以重复执行上面命令,直到作业状态显示为 FINISHED。
JOB_ID: 10466
LABEL: user_behavior
DATABASE_NAME: mydatabase
STATE: LOADING
PROGRESS: ETL:100%; LOAD:39%
TYPE: BROKER
PRIORITY: NORMAL
SCAN_ROWS: 4620288
FILTERED_ROWS: 0
UNSELECTED_ROWS: 0
SINK_ROWS: 4620288
ETL_INFO:
TASK_INFO: resource:N/A; timeout(s):72000; max_filter_ratio:0.0
CREATE_TIME: 2024-02-28 22:11:36
ETL_START_TIME: 2024-02-28 22:11:41
ETL_FINISH_TIME: 2024-02-28 22:11:41
LOAD_START_TIME: 2024-02-28 22:11:41
LOAD_FINISH_TIME: NULL
JOB_DETAILS: {"All backends":{"2fb97223-b14c-404b-9be1-83aa9b3a7715":[10004]},"FileNumber":1,"FileSize":136901706,"InternalTableLoadBytes":144032784,"InternalTableLoadRows":4620288,"ScanBytes":143969616,"ScanRows":4620288,"TaskNumber":1,"Unfinished backends":{"2fb97223-b14c-404b-9be1-83aa9b3a7715":[10004]}}
ERROR_MSG: NULL
TRACKING_URL: NULL
TRACKING_SQL: NULL
导入作业完成后,您可以从表内查询数据,验证数据是否已成功导入。例如:
SELECT * from user_behavior LIMIT 3;
系统返回如下查询结果,表明数据已经成功导入:
+--------+---------+------------+--------------+---------------------+
| UserID | ItemID | CategoryID | BehaviorType | Timestamp |
+--------+---------+------------+--------------+---------------------+
| 34 | 856384 | 1029459 | pv | 2017-11-27 14:43:27 |
| 34 | 5079705 | 1029459 | pv | 2017-11-27 14:44:13 |
| 34 | 4451615 | 1029459 | pv | 2017-11-27 14:45:52 |
+--------+---------+------------+--------------+---------------------+
通过 Pipe 导入
从 3.2 版本起,StarRocks 提供 Pipe 导入方式,当前只支持 Parquet 和 ORC 文件格式。
Pipe 优势
Pipe 适用于大规模批量导入数据、以及持续导入数据的场景:
-
大规模分批导入,降低出错重试成本。
需要导入的数据��文件较多、数据量大。Pipe 会按文件数量或大小,自动对目录下的文件进行拆分,将一个大的导入作业拆分成多个较小的串行的导入任务。单个文件的数据错误不会导致整个导入作业的失败。另外,Pipe 会记录每个文件的导入状态。当导入结束后,您可以修复出错的数据文件,然后重新导入修正后的数据文件即可。这有助于降低数据出错重试的代价。
-
不间断持续导入,减少人力操作成本。
需要将新增或变化的数据文件写入到某个文件夹下,并且新增的数据需要持续地导入到 StarRocks 中。您只需要创建一个基于 Pipe 的持续导入作业(在语句中指定
"AUTO_INGEST" = "TRUE"),该 Pipe 会持续监控该作业中指定的路径下的数据文件变化,将新增或有变动的数据文件自动导入到 StarRocks 目标表中。
此外,Pipe 还支持文件唯一性判断,避免重复数据导入。在导入过程中,Pipe 会根据文件名和文件对应的摘要值判断数据文件是否重复。如果文件名和文件摘要值在同一个 Pipe 导入作业中已经处理过,后续导入会自动跳过已经处理过的文件。注意,AWS S3 等对象存储使用 ETag 作为文件摘要
导入过程中的文件状态会记录到 information_schema.pipe_files 视图下,您可以通过该视图查看 Pipe 导入作业下各文件的导入状态。如果该视图关联的 Pipe 作业被删除,那么该视图下相关的记录也会同步清理。
Pipe 与 INSERT+FILES() 的区别
Pipe 导入操作会根据每个数据文件的大小和包含的行数,分割成一个或多个事务,导入过程中的中间结果对用户可见。INSERT+FILES() 导入操作是一个整体事务,导入过程中数据对用户不可见。
文件导入顺序
Pipe 导入操作会在内部维护一个文件队列,分批次从队列中取出对应文件进行导入。Pipe 并不能保证文件的导入顺序和文件上传顺序一致,因此可能会出现新的数据早于老的数据导入。
操作示例
建库建表
通过如下语句创建数据库、并切换至该数据库:
CREATE DATABASE IF NOT EXISTS mydatabase;
USE mydatabase;
通过如下语句手动创建表(建议表结构与您在 AWS S3 存储的待导入数据结构一致):
CREATE TABLE user_behavior_from_pipe
(
UserID int(11),
ItemID int(11),
CategoryID int(11),
BehaviorType varchar(65533),
Timestamp datetime
)
ENGINE = OLAP
DUPLICATE KEY(UserID)
DISTRIBUTED BY HASH(UserID);
提交导入作业
执行如下命令创建 Pipe 作业,把样例数据集 s3://starrocks-examples/user-behavior-10-million-rows/ 中的数据导入到表 user_behavior_from_pipe 中。该 Pipe 作业同时使用了 Pipe 特有的微批导入和持续导入功能。
在本文前面介绍的几种集中导入方式及其示例中,都是一次性导入单个 Parquet 文件中所包含的所有 1000 万行数据。在本小节介绍的 Pipe 导入方式及其示例中,导入的是同样的 Parquet 文件,但是文件被拆分成了 57 个独立的小文件,所有小文件都存放在同一个 S3 路径下。注意,在下面的 CREATE PIPE 命令示例中,path 参数中传入的 S3 URI 必须是一个路径(URI 以 /* 结尾),而不是一个具体的文件名(URI 以文件名结尾)。这��样,该 Pipe 作业会持续地在指定的 S3 路径中轮询检查是否有新文件产生,并持续地将新文件中的数据导入到 StarRocks 中。
CREATE PIPE user_behavior_pipe
PROPERTIES
(
"AUTO_INGEST" = "TRUE"
)
AS
INSERT INTO user_behavior_from_pipe
SELECT * FROM FILES
(
"path" = "s3://starrocks-examples/user-behavior-10-million-rows/*",
"format" = "parquet",
"aws.s3.region" = "us-east-1",
"aws.s3.access_key" = "AAAAAAAAAAAAAAAAAAAA",
"aws.s3.secret_key" = "BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB"
);
说明
把上面命令示例中的
AAA和BBB替换成真实有效的 Access Key 和 Secret Key 作为访问凭证。由于这里使用的数据对象对所有合法的 AWS 用户开放,因此您填入任何真实有效的 Access Key 和 Secret Key 都可以。
导入语句包含四个部分:
pipe_name:Pipe 的名称。该名称在 Pipe 所在的数据库内必须唯一。INSERT_SQL:INSERT INTO SELECT FROM FILES 语句,用于从指定的源数据文件导入数据到目标表。PROPERTIES:用于控制 Pipe 执行的一些参数,例如AUTO_INGEST、POLL_INTERVAL、BATCH_SIZE和BATCH_FILES,格式为"key" = "value"。
有关详细的语法和参数说明,参见 CREATE PIPE。
查看导入进度
-
在当前数据库中通过 SHOW PIPES 查看导入作业。
SHOW PIPES WHERE NAME = 'user_behavior_pipe' \G系统返回如下查询结果:
提示在下面的返回结果中可以看到,该 Pipe 作业处于
RUNNING状态,并且在您手动停止该作业前,会一直处于RUNNING状态。同时还可以看到,当前总共已导入多少个文件(57 个)、以及最后一个文件的导入时间。*************************** 1. row ***************************
DATABASE_NAME: mydatabase
PIPE_ID: 10476
PIPE_NAME: user_behavior_pipe
STATE: RUNNING
TABLE_NAME: mydatabase.user_behavior_from_pipe
LOAD_STATUS: {"loadedFiles":57,"loadedBytes":295345637,"loadingFiles":0,"lastLoadedTime":"2024-02-28 22:14:19"}
LAST_ERROR: NULL
CREATED_TIME: 2024-02-28 22:13:41
1 row in set (0.02 sec) -
通过 StarRocks Information Schema 库中的
pipes视图查看当前数据库中的导入作业。SELECT * FROM information_schema.pipes WHERE pipe_name = 'uuser_behavior_pipe' \G系统返回如下查询结果:
提示本文中某些查询语句结尾用的是
\G、而不是分号 (;),目的是为了让 MySQL 客户端输出的查询结果垂直展示,便于查看。如果您使用的是 DBeaver 或其他客户端,则可能只能在查询语句末尾使用分号 (;),而不能使用\G。*************************** 1. row ***************************
DATABASE_NAME: mydatabase
PIPE_ID: 10217
PIPE_NAME: user_behavior_replica
STATE: RUNNING
TABLE_NAME: mydatabase.user_behavior_replica
LOAD_STATUS: {"loadedFiles":1,"loadedBytes":132251298,"loadingFiles":0,"lastLoadedTime":"2023-11-09 15:35:42"}
LAST_ERROR:
CREATED_TIME: 9891-01-15 07:51:45
1 row in set (0.01 sec)
查看导入的文件信息
您可以通过 StarRocks Information Schema 库中的 pipe_files 视图查看导入的文件信息。
SELECT * FROM information_schema.pipe_files WHERE pipe_name = 'user_behavior_replica' \G
系统返回如下查询结果:
*************************** 1. row ***************************
DATABASE_NAME: mydatabase
PIPE_ID: 10217
PIPE_NAME: user_behavior_replica
FILE_NAME: s3://starrocks-examples/user-behavior-10-million-rows.parquet
FILE_VERSION: e29daa86b1120fea58ad0d047e671787-8
FILE_SIZE: 132251298
LAST_MODIFIED: 2023-11-06 13:25:17
LOAD_STATE: FINISHED
STAGED_TIME: 2023-11-09 15:35:02
START_LOAD_TIME: 2023-11-09 15:35:03
FINISH_LOAD_TIME: 2023-11-09 15:35:42
ERROR_MSG:
1 row in set (0.03 sec)
管理导入作业
创建 Pipe 导入作业以后,您可以根据需要对这些作业进行修改��、暂停或重新启动、删除、查询、以及尝试重新导入等操作。详情参见 ALTER PIPE、SUSPEND or RESUME PIPE、DROP PIPE、SHOW PIPES、RETRY FILE。
