Iceberg Lakehouse tutorial
Apache Iceberg レイクハウス
概要
- Docker compose を使用して、オブジェクトストレージ、Apache Spark、Iceberg catalog、StarRocks をデプロイ
- 2023年5月のニューヨーク市グリーンタクシーデータを Iceberg データレイクにロード
- Iceberg catalog にアクセスするために StarRocks を設定
- データが存在する場所で StarRocks を使用してデータをクエリ
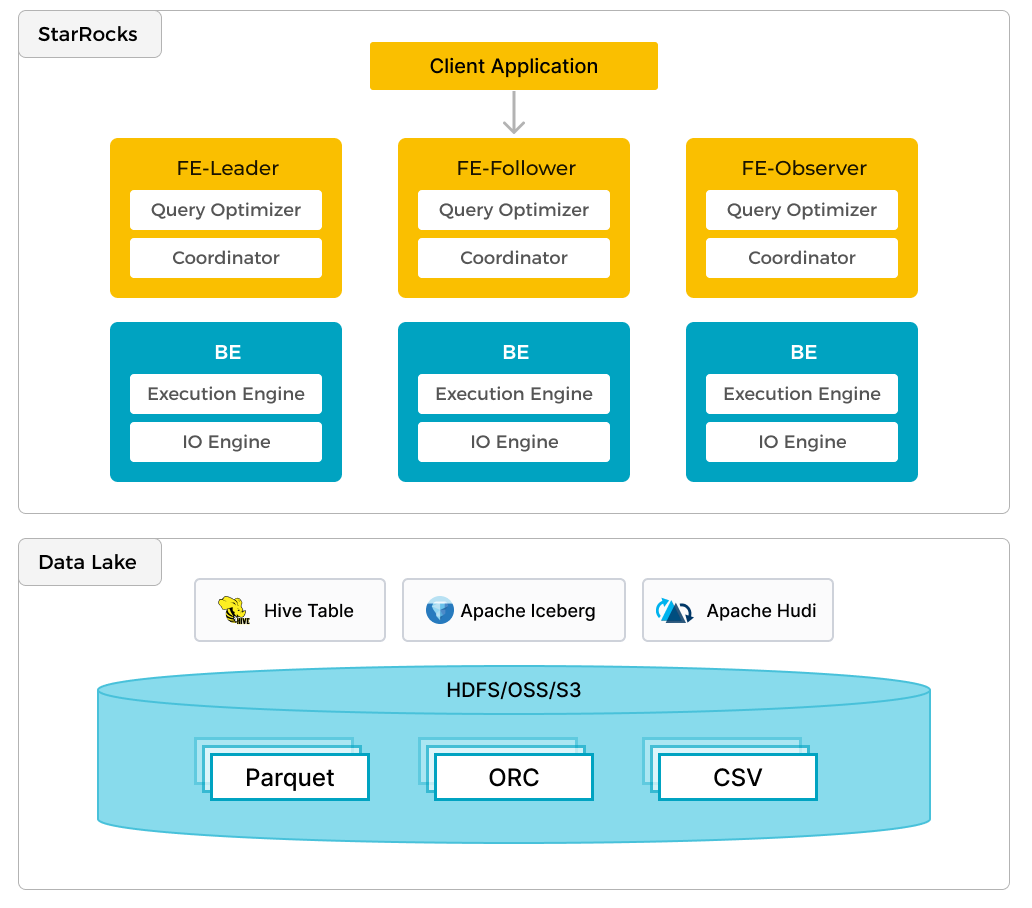
StarRocks は、ローカルデータの効率的な分析に加えて、データレイクに保存されたデータを分析するためのコンピュートエンジンとしても機能します。Apache Hudi、Apache Iceberg、Delta Lake などが含まれます。StarRocks の主要な機能の一つは、外部で管理されているメタストアへのリンクとして機能する external catalog です。この機能により、データ移行の必要なく、外部データソースをシームレスにクエリすることができます。そのため、ユーザーは HDFS や Amazon S3 などの異なるシステムから、Parquet、ORC、CSV などのさまざまなファイル形式でデータを分析できます。
前述の図は、StarRocks がデータの計算と分析を担当し、データレイクがデータの保存、組織化、メンテナンスを担当するデータレイク分析のシナリオを示しています。データレイクは、ユーザーがオープンストレージ形式でデータを保存し、柔軟なスキーマを使用して、さまざまな BI、AI、アドホック、およびレポート用途の「単一の真実の源」に基づくレポートを作成することを可能にします。StarRocks は、そのベクトル化エンジンと CBO の利点を十分に活用し、データレイク分析のパフォーマンスを大幅に向上させます。
前提条件
Docker
- Docker
- Docker に割り当てられた 5 GB の RAM
- Docker に割り当てられた 20 GB の空きディスクスペース
SQL クライアント
Docker 環境で提供される SQL クライアントを使用するか�、システム上のものを使用できます。多くの MySQL 互換クライアントが動作し、このガイドでは DBeaver と MySQL Workbench の設定をカバーしています。
curl
curl はデータセットをダウンロードするために使用されます。OS のプロンプトで curl または curl.exe を実行してインストールされているか確認してください。curl がインストールされていない場合は、こちらから取得してください。
StarRocks 用語
FE
フロントエンドノードは、メタデータ管理、クライアント接続管理、クエリプランニング、およびクエリスケジューリングを担当します。各 FE はメモリ内にメタデータの完全なコピーを保存および維持し、FEs 間での無差別なサービスを保証します。
BE
バックエンド (BE) ノードは、共有なしデプロイメントでのデータストレージとクエリプランの実行の両方を担当します。このガイドで使用されている Iceberg catalog のような外部カタログが使用される場合、BE ノードは外部カタログからデータをキャッシュしてクエリを高速化できます。
環境
このガイドで使用されるコンテナ(サービス)は6つあり、すべて Docker compose でデプロイされます。サービスとその責任は次のとおりです:
| サービス | 責任 |
|---|---|
starrocks-fe | メタデータ管理、クライアント接続、クエリプランとスケジューリング |
starrocks-be | クエリプランの実行 |
rest | Iceberg catalog (メタデータサービス) の提供 |
spark-iceberg | PySpark を実行するための Apache Spark 環境 |
mc | MinIO 設定 (MinIO コマンドラインクライアント) |
minio | MinIO オブジェクトストレージ |
Docker 構成と NYC グリーンタクシーデータのダウンロード
3つの必要なコンテナを備えた環境を提供するために、StarRocks �は Docker compose ファイルを提供します。curl で compose ファイルとデータセットをダウンロードします。
Docker compose ファイル:
mkdir iceberg
cd iceberg
curl -O https://raw.githubusercontent.com/StarRocks/demo/master/documentation-samples/iceberg/docker-compose.yml
データセット:
curl -O https://raw.githubusercontent.com/StarRocks/demo/master/documentation-samples/iceberg/datasets/green_tripdata_2023-05.parquet
Docker で環境を開始
このコマンドおよびその他の docker compose コマンドは、docker-compose.yml ファイルを含むディレクトリから実行してください。
docker compose up -d
[+] Building 0.0s (0/0) docker:desktop-linux
[+] Running 6/6
✔ Container iceberg-rest Started 0.0s
✔ Container minio Started 0.0s
✔ Container starrocks-fe Started 0.0s
✔ Container mc Started 0.0s
✔ Container spark-iceberg Started 0.0s
✔ Container starrocks-be Started
環境のステータスを確認
サービスの進行状況を確認します。FE と BE が正常になるまで約30秒かかります。
docker compose ps を実行し、FE と BE が healthy のステータスを示すまで待ちます。その他のサービスにはヘルスチェック構成がありませんが、それらと対話することで動作し�ているかどうかがわかります:
jq がインストールされていて、docker compose ps の短いリストを好む場合は次を試してください:
docker compose ps --format json | jq '{Service: .Service, State: .State, Status: .Status}'
docker compose ps
SERVICE CREATED STATUS PORTS
rest 4 minutes ago Up 4 minutes 0.0.0.0:8181->8181/tcp
mc 4 minutes ago Up 4 minutes
minio 4 minutes ago Up 4 minutes 0.0.0.0:9000-9001->9000-9001/tcp
spark-iceberg 4 minutes ago Up 4 minutes 0.0.0.0:8080->8080/tcp, 0.0.0.0:8888->8888/tcp, 0.0.0.0:10000-10001->10000-10001/tcp
starrocks-be 4 minutes ago Up 4 minutes (healthy) 0.0.0.0:8040->8040/tcp
starrocks-fe 4 minutes ago Up 4 minutes (healthy) 0.0.0.0:8030->8030/tcp, 0.0.0.0:9020->9020/tcp, 0.0.0.0:9030->9030/tcp
PySpark
Iceberg と対話する方法はいくつかありますが、このガイドでは PySpark を使用します。PySpark に慣れていない場合は、詳細情報セクションにリ�ンクされたドキュメントがありますが、実行する必要のあるすべてのコマンドが以下に提供されています。
グリーンタクシーデータセット
データを spark-iceberg コンテナにコピーします。このコマンドはデータセットファイルを spark-iceberg サービスの /opt/spark/ ディレクトリにコピーします:
docker compose \
cp green_tripdata_2023-05.parquet spark-iceberg:/opt/spark/
PySpark を起動
このコマンドは spark-iceberg サービスに接続し、pyspark コマンドを実行します:
docker compose exec -it spark-iceberg pyspark
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 3.5.0
/_/
Using Python version 3.9.18 (main, Nov 1 2023 11:04:44)
Spark context Web UI available at http://6ad5cb0e6335:4041
Spark context available as 'sc' (master = local[*], app id = local-1701967093057).
SparkSession available as 'spark'.
>>>
データセットをデータフレームに読み込む
データフレームは Spark SQL の一部であり、データベーステーブルやスプレッドシートに似たデータ構造を提供します。
グリーンタクシーデータはニューヨーク市タクシー・リムジン委員会によって Parquet 形式で提供されています。/opt/spark ディレクトリからファイルをロードし、最初の数レコードを SELECT して最初の3行のデータの最初の数列を確認します。これらのコマンド��は pyspark セッションで実行する必要があります。コマンド:
- ディスクからデータセットファイルを読み込み、
dfという名前のデータフレームに格納 - Parquet ファイルのスキーマを表示
df = spark.read.parquet("/opt/spark/green_tripdata_2023-05.parquet")
df.printSchema()
root
|-- VendorID: integer (nullable = true)
|-- lpep_pickup_datetime: timestamp_ntz (nullable = true)
|-- lpep_dropoff_datetime: timestamp_ntz (nullable = true)
|-- store_and_fwd_flag: string (nullable = true)
|-- RatecodeID: long (nullable = true)
|-- PULocationID: integer (nullable = true)
|-- DOLocationID: integer (nullable = true)
|-- passenger_count: long (nullable = true)
|-- trip_distance: double (nullable = true)
|-- fare_amount: double (nullable = true)
|-- extra: double (nullable = true)
|-- mta_tax: double (nullable = true)
|-- tip_amount: double (nullable = true)
|-- tolls_amount: double (nullable = true)
|-- ehail_fee: double (nullable = true)
|-- improvement_surcharge: double (nullable = true)
|-- total_amount: double (nullable = true)
|-- payment_type: long (nullable = true)
|-- trip_type: long (nullable = true)
|-- congestion_surcharge: double (nullable = true)
>>>
最初の数行(3行)のデータの最初の数列(7列)を確認します:
df.select(df.columns[:7]).show(3)
+--------+--------------------+---------------------+------------------+----------+------------+------------+
|VendorID|lpep_pickup_datetime|lpep_dropoff_datetime|store_and_fwd_flag|RatecodeID|PULocationID|DOLocationID|
+--------+--------------------+---------------------+------------------+----------+------------+------------+
| 2| 2023-05-01 00:52:10| 2023-05-01 01:05:26| N| 1| 244| 213|
| 2| 2023-05-01 00:29:49| 2023-05-01 00:50:11| N| 1| 33| 100|
| 2| 2023-05-01 00:25:19| 2023-05-01 00:32:12| N| 1| 244| 244|
+--------+--------------------+---------------------+------------------+----------+------------+------------+
only showing top 3 rows
テーブルに書き込む
このステップで作成されるテーブルは、次のステップで StarRocks に提供される catalog に含まれます。
- Catalog:
demo - データベース:
nyc - テーブル:
greentaxis
df.writeTo("demo.nyc.greentaxis").create()
StarRocks を Iceberg Catalog にアクセスするように設定
PySpark からは今すぐ退出することができますが、新しいターミナルを開いて SQL コマンドを実行することもできます。新しいターミナルを開く場合は、docker-compose.yml ファイルを含む quickstart ディレクトリに移動してから続行してください。
SQL クライアントを使用して StarRocks に接続
SQL クライアント
これらの3つのクライアントはこのチュートリアルでテストされていますが、1つだけ使用すれば大丈夫です。
- mysql CLI: Docker 環境またはあなたのマシンから実行できます。
- DBeaver は、コミュニティ版と Pro 版があります。
- MySQL Workbench
�クライアントの設定
- mysql CLI
- DBeaver
- MySQL Workbench
mysql CLI を使用する最も簡単な方法は、StarRocks コンテナ starrocks-fe から実行することです。
docker compose exec starrocks-fe \
mysql -P 9030 -h 127.0.0.1 -u root --prompt="StarRocks > "
すべての docker compose コマンドは、docker-compose.yml ファイルを含むディレクトリから実行する必要があります。
mysql CLI をインストールしたい場合は、以下の mysql client install を展開してください。
mysql client install
- macOS: Homebrew を使用していて MySQL Server が不要な場合、
brew install mysql-client@8.0を実行して CLI をインストールします。 - Linux:
mysqlクライアントをリポジトリシステムで確認します。例えば、yum install mariadb。 - Microsoft Windows: MySQL Community Server をインストールして提供されたクライアントを実行するか、WSL から
mysqlを実行します。
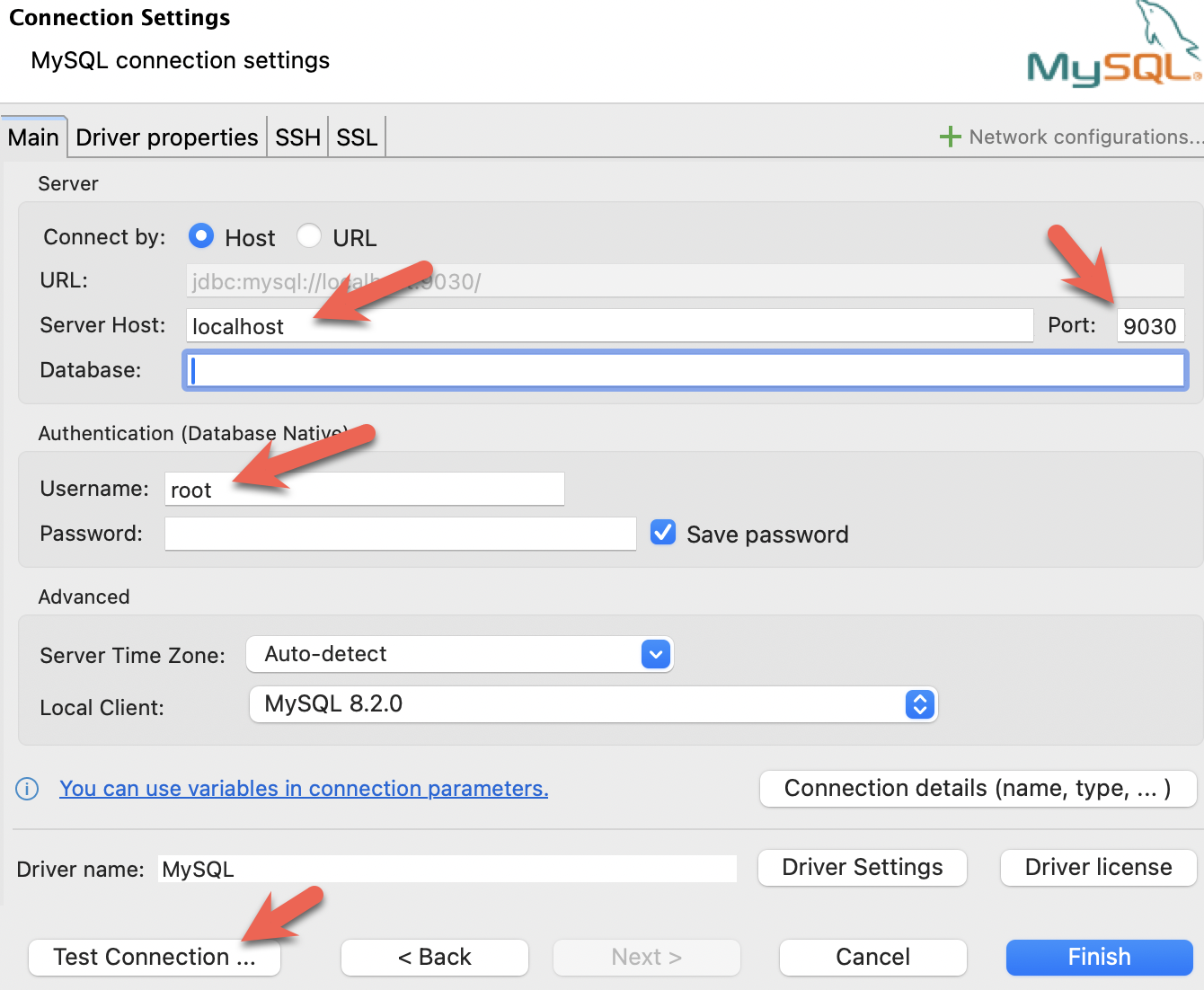
- DBeaver をインストールし、接続を追加します。

- ポート、IP、ユーザー名を設定します。接続をテストし、テストが成功したら Finish をクリックします。
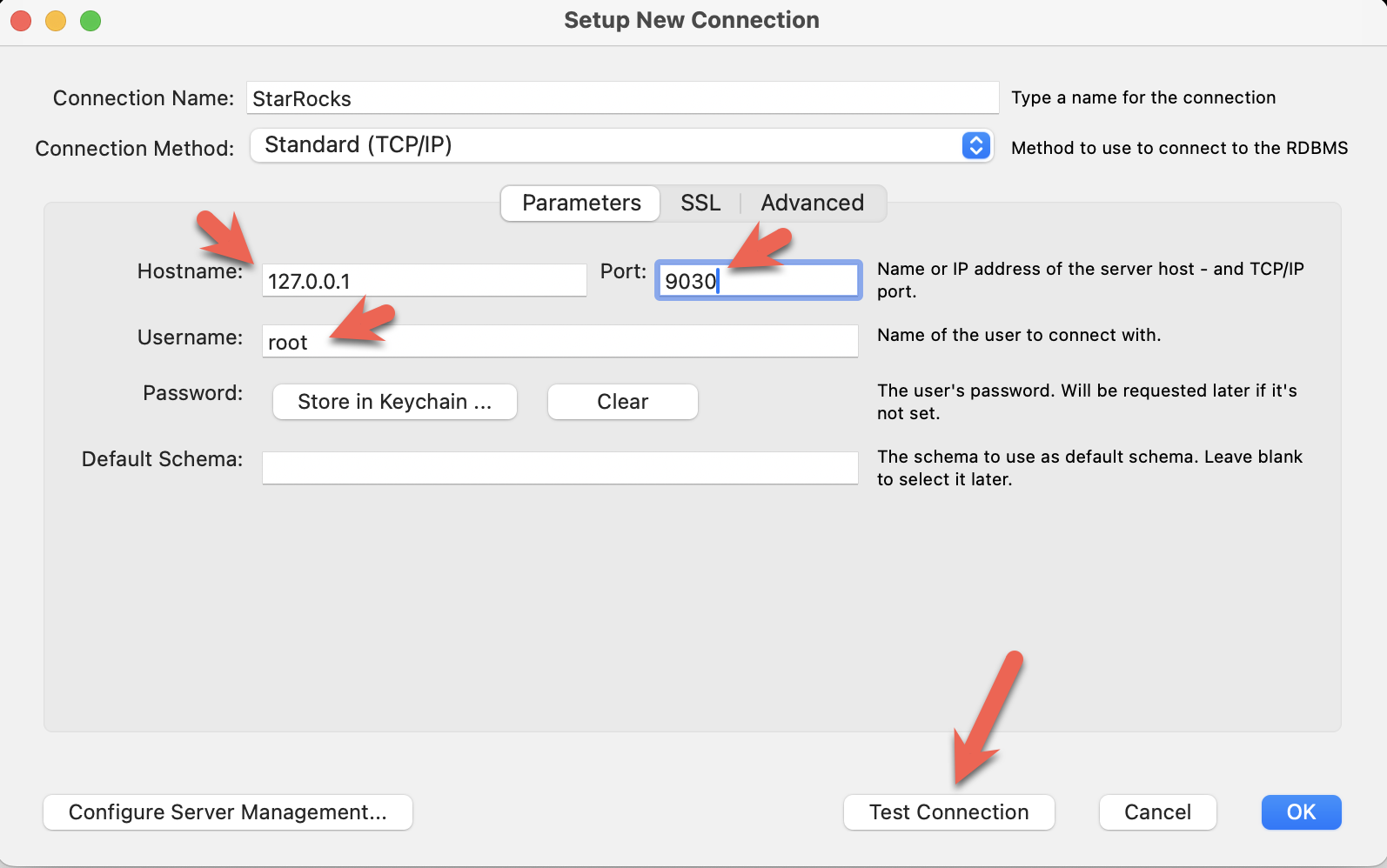
- MySQL Workbench をインストールし、接続を追加します。
- ポート、IP、ユーザー名を設定し、接続をテストします。
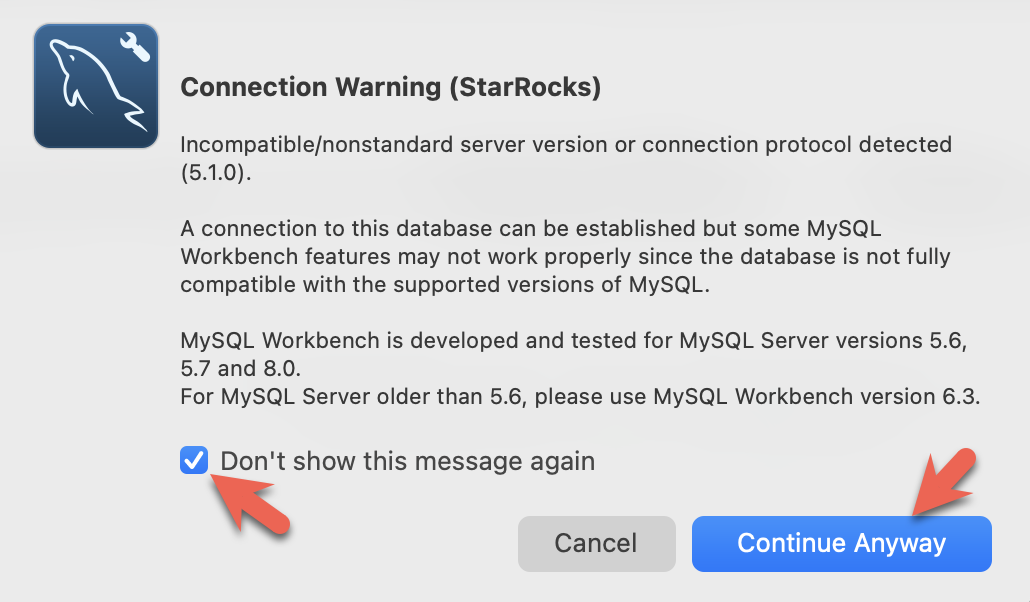
- Workbench は特定の MySQL バージョンをチェックするため、警告が表示されます。警告を無視し、プロンプトが表示されたら、Workbench が警告を表示しないように設定できます。
PySpark セッションを終了し、StarRocks に接続できま��す。
このコマンドは、docker-compose.yml ファイルを含むディレクトリから実行してください。
mysql CLI 以外のクライアントを使用している場合は、今すぐ開いてください。
docker compose exec starrocks-fe \
mysql -P 9030 -h 127.0.0.1 -u root --prompt="StarRocks > "
StarRocks >
外部カタログを作成
外部カタログは、StarRocks が Iceberg データを StarRocks のデータベースやテーブルにあるかのように操作できるようにする設定です。個々の設定プロパティはコマンドの後に詳述されます。
CREATE EXTERNAL CATALOG 'iceberg'
COMMENT "External catalog to Apache Iceberg on MinIO"
PROPERTIES
(
"type"="iceberg",
"iceberg.catalog.type"="rest",
"iceberg.catalog.uri"="http://iceberg-rest:8181",
"iceberg.catalog.warehouse"="warehouse",
"aws.s3.access_key"="admin",
"aws.s3.secret_key"="password",
"aws.s3.endpoint"="http://minio:9000",
"aws.s3.enable_path_style_access"="true",
"client.factory"="com.starrocks.connector.iceberg.IcebergAwsClientFactory"
);
PROPERTIES
| プロパティ | 説明 |
|---|---|
type | この例では iceberg タイプです。他のオプションには Hive、Hudi、Delta Lake、JDBC があります。 |
iceberg.catalog.type | この例では rest が使用されています。Tabular は使用される Docker イメージを提供し、Tabular は REST を使用します。 |
iceberg.catalog.uri | REST サーバーのエンドポイント。 |
iceberg.catalog.warehouse | Iceberg catalog の識別子。この場合、compose ファイルで指定されたウェアハウス名は warehouse です。 |
aws.s3.access_key | MinIO キー。この場合、キーとパスワードは compose ファイルで admin に設定されています。 |
aws.s3.secret_key | パスワード。 |
aws.s3.endpoint | MinIO エンドポイント。 |
aws.s3.enable_path_style_access | MinIO をオブジェクトストレージとして使用する場合に必要です。MinIO はこの形式 http://host:port/<bucket_name>/<key_name> を期待します。 |
client.factory | このプロパティを iceberg.IcebergAwsClientFactory に設定することで、aws.s3.access_key と aws.s3.secret_key パラメータが認証に使用されます。 |
SHOW CATALOGS;
+-----------------+----------+------------------------------------------------------------------+
| Catalog | Type | Comment |
+-----------------+----------+------------------------------------------------------------------+
| default_catalog | Internal | An internal catalog contains this cluster's self-managed tables. |
| iceberg | Iceberg | External catalog to Apache Iceberg on MinIO |
+-----------------+----------+------------------------------------------------------------------+
2 rows in set (0.03 sec)
SET CATALOG iceberg;
SHOW DATABASES;
表示されるデータベースは、PySpark セッションで作成されました。CATALOG iceberg を追加すると、データベース nyc が StarRocks で表示可能になりました。
+--------------------+
| Database |
+--------------------+
| information_schema |
| nyc |
+--------------------+
2 rows in set (0.07 sec)
USE nyc;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
SHOW TABLES;
+---------------+
| Tables_in_nyc |
+---------------+
| greentaxis |
+---------------+
1 rows in set (0.05 sec)
DESCRIBE greentaxis;
StarRocks が使用するスキーマを、以前の PySpark セッションの df.printSchema() の出力と比較してください。Spark の timestamp_ntz データ型は StarRocks の DATETIME などとして表されます。
+-----------------------+---------------------+------+-------+---------+-------+---------+
| Field | Type | Null | Key | Default | Extra | Comment |
+-----------------------+---------------------+------+-------+---------+-------+---------+
| VendorID | INT | Yes | false | NULL | | NULL |
| lpep_pickup_datetime | DATETIME | Yes | false | NULL | | NULL |
| lpep_dropoff_datetime | DATETIME | Yes | false | NULL | | NULL |
| store_and_fwd_flag | VARCHAR(1073741824) | Yes | false | NULL | | NULL |
| RatecodeID | BIGINT | Yes | false | NULL | | NULL |
| PULocationID | INT | Yes | false | NULL | | NULL |
| DOLocationID | INT | Yes | false | NULL | | NULL |
| passenger_count | BIGINT | Yes | false | NULL | | NULL |
| trip_distance | DOUBLE | Yes | false | NULL | | NULL |
| fare_amount | DOUBLE | Yes | false | NULL | | NULL |
| extra | DOUBLE | Yes | false | NULL | | NULL |
| mta_tax | DOUBLE | Yes | false | NULL | | NULL |
| tip_amount | DOUBLE | Yes | false | NULL | | NULL |
| tolls_amount | DOUBLE | Yes | false | NULL | | NULL |
| ehail_fee | DOUBLE | Yes | false | NULL | | NULL |
| improvement_surcharge | DOUBLE | Yes | false | NULL | | NULL |
| total_amount | DOUBLE | Yes | false | NULL | | NULL |
| payment_type | BIGINT | Yes | false | NULL | | NULL |
| trip_type | BIGINT | Yes | false | NULL | | NULL |
| congestion_surcharge | DOUBLE | Yes | false | NULL | | NULL |
+-----------------------+---------------------+------+-------+---------+-------+---------+
20 rows in set (0.03 sec)
StarRocks ドキュメントの一部の SQL クエリは、セミコロンの代わりに \G で終わります。\G は mysql CLI にクエリ結果を縦に表示させます。
多くの SQL クライアントは縦のフォーマット出力を解釈しないため、mysql CLI を使用していない場合は \G を ; に置き換えるべきです。
StarRocks でクエリ
ピックアップ日時のフォーマットを確認
SELECT lpep_pickup_datetime FROM greentaxis LIMIT 10;
+----------------------+
| lpep_pickup_datetime |
+----------------------+
| 2023-05-01 00:52:10 |
| 2023-05-01 00:29:49 |
| 2023-05-01 00:25:19 |
| 2023-05-01 00:07:06 |
| 2023-05-01 00:43:31 |
| 2023-05-01 00:51:54 |
| 2023-05-01 00:27:46 |
| 2023-05-01 00:27:14 |
| 2023-05-01 00:24:14 |
| 2023-05-01 00:46:55 |
+----------------------+
10 rows in set (0.07 sec)
忙しい時間帯を見つける
このクエリは、1日の時間ごとにトリップを集計し、最も忙しい時間帯が18:00であることを示します。
SELECT COUNT(*) AS trips,
hour(lpep_pickup_datetime) AS hour_of_day
FROM greentaxis
GROUP BY hour_of_day
ORDER BY trips DESC;
+-------+-------------+
| trips | hour_of_day |
+-------+-------------+
| 5381 | 18 |
| 5253 | 17 |
| 5091 | 16 |
| 4736 | 15 |
| 4393 | 14 |
| 4275 | 19 |
| 3893 | 12 |
| 3816 | 11 |
| 3685 | 13 |
| 3616 | 9 |
| 3530 | 10 |
| 3361 | 20 |
| 3315 | 8 |
| 2917 | 21 |
| 2680 | 7 |
| 2322 | 22 |
| 1735 | 23 |
| 1202 | 6 |
| 1189 | 0 |
| 806 | 1 |
| 606 | 2 |
| 513 | 3 |
| 451 | 5 |
| 408 | 4 |
+-------+-------------+
24 rows in set (0.08 sec)
まとめ
このチュートリアルでは、StarRocks の外部カタログを使用して、Iceberg REST catalog を使用してデータをその場でクエリできることを示しました。Hive、Hudi、Delta Lake、JDBC カタログを使用した他の多くの統合が利用可能です。
このチュートリアルでは以下を行いました:
- Docker で StarRocks と Iceberg/PySpark/MinIO 環境をデプロイ
- Iceberg catalog にアクセスするために StarRocks の外部カタログを設定
- ニューヨーク市が提供するタクシーデータを Iceberg データレイクにロード
- データレイクからデータをコピーせずに StarRocks で SQL を使用してデータをクエリ
詳細情報
Apache Iceberg ドキュメント および クイックスタート (PySpark を含む)
グリーンタクシートリップ記録 データセットは、ニューヨーク市によって提供され、これらの 利用規約 および プライバシーポリシー に従います。
