【公测中】行列混�存表
StarRocks 属于 OLAP 数据库,原先数据是按列存储的方式,能够提高复杂查询(例如聚合查询)的性能。自 3.2.3 开始,StarRocks 还支持行列混存的表存储格式,能够支撑基于主键的高并发、低延时点查,以及数据部分列更新等场景,同时还保留了原有列存的高效分析能力。此外,行列混存表还支持预准备语句,能够提高查询的性能和安全性。
列存和行列混存对比
行列混存
-
存储方式:数据同时按照列和行存储。简单来说,行列混存表会额外加一个隐藏的二进制类型的列
__row,写入数据至表的同时还会将一行数据所有 value 列编码后的值写入列__row(如下所示)。由于数据同时按照列和行存储,因此会带来额外的存储成本。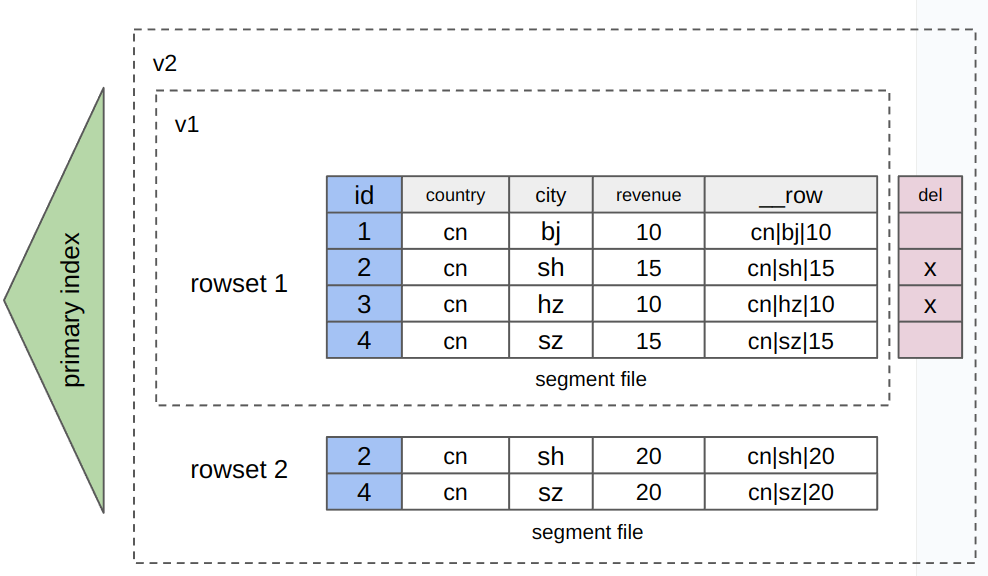
-
适用场景:能够兼顾行存和列存的场景,但是会带来额外的存储成本。
- 按行存储的适用场景。
- 基于主键的高并发点查。
- 表的字段个数比较少,并且通常会查询大部分字段。
- 部分列更新(更新多列和少量数据行)
- 列存的场景:复杂数据分析。
列存
-
存储方式:按列存储数据。
-
适用场景:复杂数据分析。
- 针对海量数据进行复杂查询分析,比如聚合分析、多表关联查询。
- 表的字段比较多(比如大宽表),但查询的字段不多。
基本操作
创建行列混存表
-
开启 FE 配置项
enable_experimental_rowstore。ADMIN SET FRONTEND CONFIG ("enable_experimental_rowstore" = "true"); -
建表时在
PROPERTIES中配置"STORE_TYPE" = "column_with_row"。
- 必须为主键模型表。
__row列的长度不能超过 1 MB。- 自 3.2.4 起,列的类型新增支持 BITMAP、HLL、JSON、ARRAY、MAP 和 STRUCT。
- 表中除了主键列外必须包含更多的列。
CREATE TABLE users (
id bigint not null,
country string,
city string,
revenue bigint
)
PRIMARY KEY (id)
DISTRIBUTED BY HASH(id)
PROPERTIES ("storage_type" = "column_with_row");
增删改数据
和列存表一样,您可以通过数据导入和 DML 语句向行列混存表中增加、删除和修改数据。本小节使用 DML 语句和上述行列混存表进行演示。
-
插入数据。
INSERT INTO users (id, country, city, revenue)
VALUES
(1, 'USA', 'New York', 5000),
(2, 'UK', 'London', 4500),
(3, 'France', 'Paris', 6000),
(4, 'Germany', 'Berlin', 4000),
(5, 'Japan', 'Tokyo', 7000),
(6, 'Australia', 'Sydney', 7500); -
删除一行数据。
DELETE FROM users WHERE id = 6; -
修改一行数据。
UPDATE users SET revenue = 6500 WHERE id = 4;
查询数据
这里以点查为例。点查走短路径,即直接查询按行存储的数据,可以提高查询性能。
依然使用上述行列混存表进行演示。该表经过上述的建表和数据变更操作,其包含的数据应该为:
MySQL [example_db]> SELECT * FROM users ORDER BY id;
+------+---------+----------+---------+
| id | country | city | revenue |
+------+---------+----------+---------+
| 1 | USA | New York | 5000 |
| 2 | UK | London | 4500 |
| 3 | France | Paris | 6000 |
| 4 | Germany | Berlin | 6500 |
| 5 | Japan | Tokyo | 7000 |
+------+---------+----------+---------+
5 rows in set (0.03 sec)
-
确保系统已经开启短路径查询。短路径查询开启后,满足条件(用于评估是否为点查)的查询会走短路径,直接查询按行存储的数据。
SHOW VARIABLES LIKE '%enable_short_circuit%';如果短路径查询未开启,可以执行命令
SET enable_short_circuit = true;,设置变量enable_short_circuit为true。 -
查询数据。如果查询满足本条件:WHERE 子句的条件列必须包含所有主键列,并且运算符为
=或者IN,该查询才会走短路径。备注WHERE 子句的条件列在包含所有主键列的基础上,还可以包含其他列。
SELECT * FROM users WHERE id=1;您可以通过查看查询规划来确认查询是否走短路径。如果查询规划中包括
Short Circuit Scan: true,则代表查询走的是短路径。MySQL [example_db]> EXPLAIN SELECT * FROM users WHERE id=1;
+---------------------------------------------------------+
| Explain String |
+---------------------------------------------------------+
| PLAN FRAGMENT 0 |
| OUTPUT EXPRS:1: id | 2: country | 3: city | 4: revenue |
| PARTITION: RANDOM |
| |
| RESULT SINK |
| |
| 0:OlapScanNode |
| TABLE: users |
| PREAGGREGATION: OFF. Reason: null |
| PREDICATES: 1: id = 1 |
| partitions=1/1 |
| rollup: users |
| tabletRatio=1/6 |
| tabletList=10184 |
| cardinality=-1 |
| avgRowSize=0.0 |
| Short Circuit Scan: true | -- 短路径查询生效
+---------------------------------------------------------+
17 rows in set (0.00 sec)
使用预准备语句
您可以使用预准备语句来查询行列混存表的数据。例如:
-- 准备语句以供执行。
PREPARE select_all_stmt FROM 'SELECT * FROM users';
PREPARE select_by_id_stmt FROM 'SELECT * FROM users WHERE id = ?';
-- 声明语句中的变量。
SET @id1 = 1, @id2 = 2;
-- 使用已声明的变量来执行语句。
-- 分别查询 ID 为 1 和 2 的数��据
EXECUTE select_by_id_stmt USING @id1;
EXECUTE select_by_id_stmt USING @id2;
注意事项
- StarRocks 存算分离集群暂不支持行列混存表。
- 自 3.2.4 版本起,行列混存表支持 ALTER TABLE。
- 短路径查询目前仅适合定期批量导入后纯查询的场景。因为目前短路径查询和写流程中的 apply 步骤互斥访问索引,所以写操作可能会堵塞短路径查询,导致写入时会影响点查的响应时间。
- 行列混存表可能会大幅增加存储空间的占用。因为数据会按行和列格式存储两份,并且按行存储压缩比可能不如按列存储高。
- 行列混存表会增加数据导入耗时和资源占用。
- 如果业务场景中有在线服务的需求,�行列混存表可以作为一种可行的解决方案,但其性能可能无法与成熟 OLTP 数据库竞争。
- 行列混存表不支持列模式部分更新等依赖按列存储的特性。
- 仅适用于主键表。
