使用 Routine Load 导入数据
本文介绍 Routine Load 的基本原理、以及如何通过 Routine Load 持续消费 Apache Kafka® 的消息并导入至 StarRocks 中。
如果您需要将消息流不间断地导入至 StarRocks,则可以将消息流存储在 Kafka 的 Topic 中,并向 StarRocks 提交一个 Routine Load 导入作业。 StarRocks 会常驻地运行这个导入作业,持续生成一系列导入任务,消费 Kafka 集群中该 Topic 中的全部或部分分区的消息并导入到 StarRocks 中。
Routine Load 支持 Exactly-Once 语义,能够保证数据不丢不重。
Routine Load 支持在导入过程中做数据转换、以及通过 UPSERT 和 DELETE 操作实现数据变更。请参见导入过程中实现数据转换和通过导入实现数据变更。
注意
Routine Load 操作需要目标表的 INSERT 权限。如果您的用户账号没有 INSERT 权限,请参考 GRANT 给用户赋权。
支持的数据文件格式
Routine Load 目前支持从 Kakfa 集群中消费 CSV、JSON、Avro (自 v3.0.1) 格式的数据。
说明
对于 CSV 格式的数据,需要注意以下两点:
- StarRocks 支持设置长度最大不超过 50 个字节的 UTF-8 编码字符串作为列分隔符,包括常见的逗号 (,)、Tab 和 Pipe (|)。
- 空值 (null) 用
\N表示。比如,数据文件一共有三列,其中某行数据的第一列、第三列数据分别为a和b,第二列没有数据,则第二列需要用\N来表示空值,写作a,\N,b,而不是a,,b。a,,b表示第二列是一个空字符串。
基本原理
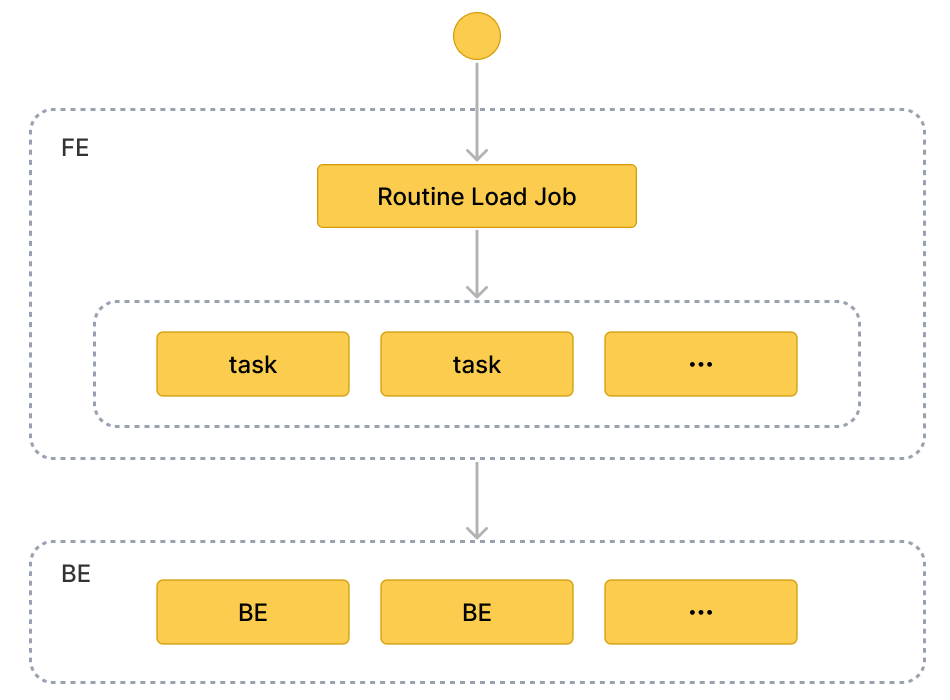
概念
-
导入作业(Load job)
导入作业会常驻运行,当导入作业的状态为 RUNNING 时,会持续不断生成一个或多个并行的导入任务,不断消费 Kafka 集群中一个 Topic 的消息,并导入至 StarRocks 中。
-
导入任务(Load task)
导入作业会按照一定规则拆分成若干个导入任务。导入任务是执行导入的基本单位,作为一个独立的事务,通过 Stream Load 导入机制实现。若干个导入任务并行消费一个 Topic 中不同分区的消息,并导入至 StarRocks 中。
作业流程
-
创建常驻的导入作业
您需要向 StarRocks 提交创建导入作业的 SQL 语句。 FE 会解析 SQL 语句,并创建一个常驻的导入作业。
-
拆分导入作业为多个导入任务
FE 将导入作业按照一定规则拆分成若干个导入任务。一个导入任务作为一个独立的事务。
拆分规则如下:
- FE 根据期望任务并行度
desired_concurrent_number、Kafka Topic 的分区数量、存活 BE 数量等,计算得出实际任务并行度。 - FE 根据实际任务并行度将导入作业分为若干导入任务,放入任务执行队列中。
每个 Topic 会有多个分区,分区与导入任务之间的对应关系为:
- 每个分区的消息只能由一个对应的导入任务消费。
- 一个导入任务可能会消费一个或多个分区。
- 分区会尽可能均匀地分配给导入任务。
- FE 根据期望任务并行度
-
多个导入任务并行进行,消费 Kafka 多个分区的消息,导入至 StarRocks
-
调度和提交导入任务:FE 定时调度任务执行队列中的导入任务,分配给选定的 Coordinator BE。调度导入任务的时间间隔由
max_batch_interval参数,并且 FE 会尽可能均匀地向所有 BE 分配导入任务。有关max_batch_interval参数的详细介绍,请参见 CREATE ROUTINE LOAD。 -
执行导入任务:Coordinator BE 执行导入任务,消费分区的消息,解析并过滤数据。导入任务需要消费足够多的消息,或者消费足够长时间。消费时间和消费的数据量由 FE 配置项
max_routine_load_batch_size、routine_load_task_consume_second决定,有关该配置项的更多说明,请参见 配置参数。然后,Coordinator BE 将消息分发至相关 Executor BE 节点, Executor BE 节点将消息写入磁盘。
说明
StarRocks 支持通过安全协议,包括 SASL_SSL、SAS_PLAINTEXT、SSL,或者 PLAINTEXT 来连接 Kafka。本文以 PLAINTEXT 方式连接 Kafka 为例进行演示,如果您需要通过其他安全协议连接 Kafka,请参见CREATE ROUTINE LOAD。
-
-
持续生成新的导入任务,不间断地导入数据
Executor BE 节点成功写入数据后, Coordonator BE 会向 FE 汇报导入结果。
FE 根据汇报结果,继续生成新的导入任务,或者对失败的导入任务进行重试,连续地导入数据,并且能够保证导入数据不丢不重。
准备工作
下载并安装 Kafka。创建 Topic 并且上传数据。操作步骤,请参见Apache Kafka quickstart。
创建导入作业
这里通过三个简单的示例,介绍如何通过 Routine Load 持续消费 Kafka 中 CSV、JSON 和 Avro 格式的数据,并导入至 StarRocks 中。有关创建 Routine Load 的详细语法和参数说明,请参见 CREATE ROUTINE LOAD。
导入 CSV 数据
本小节介绍如何创建一个 Routine Load 导入作业,持续不断地消费 Kafka 集群的 CSV 格式的数据,然后导入至 StarRocks 中。
数据集
假设 Kafka 集群的 Topic ordertest1 存在如下 CSV 格式的数据,其中 CSV 数据中列的含义依次是订单编号、支付日期、顾客姓名、国籍、性别、支付金额。
2020050802,2020-05-08,Johann Georg Faust,Deutschland,male,895
2020050802,2020-05-08,Julien Sorel,France,male,893
2020050803,2020-05-08,Dorian Grey,UK,male,1262
2020050901,2020-05-09,Anna Karenina",Russia,female,175
2020051001,2020-05-10,Tess Durbeyfield,US,female,986
2020051101,2020-05-11,Edogawa Conan,japan,male,8924
目标数据库和表
根据 CSV 数据中需要导入的几列(例如除第五列性别外的其余五列需要导入至 StarRocks), 在 StarRocks 集群的目标数据库 example_db 中创建表 example_tbl1。
CREATE TABLE example_db.example_tbl1 (
`order_id` bigint NOT NULL COMMENT "订单编号",
`pay_dt` date NOT NULL COMMENT "支付日期",
`customer_name` varchar(26) NULL COMMENT "顾客姓名",
`nationality` varchar(26) NULL COMMENT "国籍",
`price`double NULL COMMENT "支付金额"
)
ENGINE=OLAP
DUPLICATE KEY (order_id,pay_dt)
DISTRIBUTED BY HASH(`order_id`);
注意
自 2.5.7 版本起,StarRocks 支持在建表和新增分区时自动设置分桶数量 (BUCKETS),您无需手动设置分桶数量。更多信息,请参见 设置分桶数量。
导入作业
通过如下语句,向StarRocks 提交一个 Routine Load 导入作业 example_tbl1_ordertest1,持续消费 Kafka 集群中 Topic ordertest1 的消息,并导入至数据库 example_db 的表 example_tbl1 中。并且导入作业会从该 Topic 所指定分区的最早位点 (Offset) 开始消费。
CREATE ROUTINE LOAD example_db.example_tbl1_ordertest1 ON example_tbl1
COLUMNS TERMINATED BY ",",
COLUMNS (order_id, pay_dt, customer_name, nationality, temp_gender, price)
PROPERTIES
(
"desired_concurrent_number" = "5"
)
FROM KAFKA
(
"kafka_broker_list" = "<kafka_broker1_ip>:<kafka_broker1_port>,<kafka_broker2_ip>:<kafka_broker2_port>",
"kafka_topic" = "ordertest1",
"kafka_partitions" = "0,1,2,3,4",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
);
提交导入作业后,您可以执行 SHOW ROUTINE LOAD,查看导入作业执行情况。
-
导入作业的名称
一张表可能有多个导入作业,建议您根据 Kafka Topic 的名称和创建导入作业的大致时间等信息来给导入作业命名,这样有助于区分同一张表上的不同导入作业。
-
列分隔符
COLUMN TERMINATED BY指定 CSV 数据的列分隔符,默认为\t。 -
消费分区和起始消费位点
如果需要指定分区、起始消费位点,则可以配置参数
kafka_partitions、kafka_offsets。例如待消费分区为"0,1,2,3,4",并且为每个分区单独指定起始消费位点,则可以指定如下配置:"kafka_partitions" ="0,1,2,3,4",
"kafka_offsets" = "OFFSET_BEGINNING, OFFSET_END, 1000, 2000, 3000"您也可以使用
property.kafka_default_offsets来设置全部分区的默认消费位点。"kafka_partitions" ="0,1,2,3,4",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"更多参数说明,请参见 CREATE ROUTINE LOAD。
-
数据转换
如果需要指定源数据和目标表之间列的映射和转换关系,则需要配置
COLUMNS。COLUMNS中列的顺序与 CSV 数据中列的顺序一致,并且名称与目标表中的列名对应。本示例中,由于无需导入 CSV 数据的第五列至目标表,因此COLUMNS中把第五列临时命名为temp_gender用于占位,其他列都直接映射至表example_tbl1中。更多数据转换的说明,请参见导入时实现数据转换。
说明
如果 CSV 数据中列的名称、顺序和数量都能与目标表中列完全对应,则无需配置
COLUMNS。 -
增加实际任务并行度 加快导入速度
当分区数量较多,并且 BE 节点数量充足时,如果您期望加快导入速度,则可以增加实际任务并行度,将一个导入作业分成尽可能多的导入任务并行执行。
实际任务并行度由如下多个参数组成的公式决定。如果需要增加实际任务并行度,您可以在创建Routine Load 导入作业时为单个导入作业设置较高的期望任务并行度
desired_concurrent_number,以及设置较高的 Routine Load 导入作业的默认最大任务并行度的max_routine_load_task_concurrent_num,该参数为 FE 动态参数,详细说明,请参见 配置参数。此时实际任务并行度上限为存活 BE 节点数量或者指定分区数量。本示例中存活 BE 数量为 5, 指定分区数量为 5,
max_routine_load_task_concurrent_num为默认值5,如果需要增加实际任务并发度至上限,则需要将desired_concurrent_number为5(默认值为 3),计算出实际任务并行度为 5。min(aliveBeNum, partitionNum, desired_concurrent_number, max_routine_load_task_concurrent_num)更多调整导入速度的说明,请参见 Routine Load 常见问题。
导入 JSON 数据
数据集
假设 Kafka 集群的 Topic ordertest2 中存在如下 JSON 格式的数据。其中一个JSON 对象中 key 的含义依次是 品类 ID、顾客姓名、顾客国籍、支付日期、支付金额。
并且,您希望在导入时进行数据转换,将 JSON 数据中的 pay_time 键转换为 DATE 类型,并导入到目标表的列pay_dt中。
{"commodity_id": "1", "customer_name": "Mark Twain", "country": "US","pay_time": 1589191487,"price": 875}
{"commodity_id": "2", "customer_name": "Oscar Wilde", "country": "UK","pay_time": 1589191487,"price": 895}
{"commodity_id": "3", "customer_name": "Antoine de Saint-Exupéry","country": "France","pay_time": 1589191487,"price": 895}
注意
这里每行一个 JSON 对象必须在一个 Kafka 消息中,否则会出现“JSON 解析错误”的问题。
目标数据库和表
根据 JSON 数据中需要导入的 key,在 StarRocks 集群的目标数据库 example_db 中创建表 example_tbl2 。
CREATE TABLE `example_tbl2` (
`commodity_id` varchar(26) NULL COMMENT "品类ID",
`customer_name` varchar(26) NULL COMMENT "顾客姓名",
`country` varchar(26) NULL COMMENT "顾客国籍",
`pay_time` bigint(20) NULL COMMENT "支付时间",
`pay_dt` date NULL COMMENT "支付日期",
`price`double SUM NULL COMMENT "支付金额"
)
ENGINE=OLAP
AGGREGATE KEY(`commodity_id`,`customer_name`,`country`,`pay_time`,`pay_dt`)
DISTRIBUTED BY HASH(`commodity_id`);
注意
自 2.5.7 版本起,StarRocks 支持在建表和新增分区时自动设置分桶数量 (BUCKETS),您无需手动设置分桶数量。更多信息,请参见 设置分桶数量。
导入作业
通过如下语句,向 StarRocks 提交一个 Routine Load 导入作业 example_tbl2_ordertest2,持续消费 Kafka 集群中 Topic ordertest2 的消息,并导入至 example_tbl2 表中。并且导入作业会从此 Topic 所指定分区的最早位点开始消费。
CREATE ROUTINE LOAD example_db.example_tbl2_ordertest2 ON example_tbl2
COLUMNS(commodity_id, customer_name, country, pay_time, price, pay_dt=from_unixtime(pay_time, '%Y%m%d'))
PROPERTIES
(
"desired_concurrent_number" = "5",
"format" = "json",
"jsonpaths" = "[\"$.commodity_id\",\"$.customer_name\",\"$.country\",\"$.pay_time\",\"$.price\"]"
)
FROM KAFKA
(
"kafka_broker_list" = "<kafka_broker1_ip>:<kafka_broker1_port>,<kafka_broker2_ip>:<kafka_broker2_port>",
"kafka_topic" = "ordertest2",
"kafka_partitions" = "0,1,2,3,4",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
);
提交导入作业后,您可以执行 SHOW ROUTINE LOAD,查看导入作业执行情况。
-
数据格式
需要
PROPERTIES子句的"format" = "json"中指定数据格式为 JSON。 -
数据提取和转换
如果需要指定源数据和目标表之间列的映射和转换关系,则可以配置
COLUMNS和jsonpaths参数。COLUMNS中的列名对应目标表的列名,列的顺序对应源数据中的列顺序。jsonpaths参数用于提取 JSON 数据中需要的字段数据,就像新生成的 CSV 数据一样。然后COLUMNS参数对jsonpaths中的字段按顺序进行临时命名。由于源数据中
pay_time键需要转换为 DATE 类型,导入到目标表的列pay_dt,因此COLUMNS中需要使用函数from_unixtime进行转换。其他字段都能直接映射至表example_tbl2中。更多数据转换的说明,请参见导入时实现数据转换。
说明
如果每行一个 JSON 对象中 key 的名称和数量(顺序不需要对应)都能对应目标表中列,则无需配置
COLUMNS。
导入 Avro 数据
自 3.0.1 版本开始,StarRocks 支持使用 Routine Load 导入 Avro 数据。
数据集
Avro schema
-
创建如下 Avro schema 文件
avro_schema.avsc:{
"type": "record",
"name": "sensor_log",
"fields" : [
{"name": "id", "type": "long"},
{"name": "name", "type": "string"},
{"name": "checked", "type" : "boolean"},
{"name": "data", "type": "double"},
{"name": "sensor_type", "type": {"type": "enum", "name": "sensor_type_enum", "symbols" : ["TEMPERATURE", "HUMIDITY", "AIR-PRESSURE"]}}
]
} -
注册该 Avro schema 至 Schema Registry。
Avro 数据
构建 Avro 数据并且发送至 Kafka 集群的 topic topic_0。
目标数据库和表
根据 Avro 数据中需要导入的字段,在 StarRocks 集群的目标数据库 sensor 中创建表 sensor_log。表的列名与 Avro 数据的字段名保持一致。两者的数据类型映射关系,请参见数据类型映射。
CREATE TABLE example_db.sensor_log (
`id` bigint NOT NULL COMMENT "sensor id",
`name` varchar(26) NOT NULL COMMENT "sensor name",
`checked` boolean NOT NULL COMMENT "checked",
`data` double NULL COMMENT "sensor data",
`sensor_type` varchar(26) NOT NULL COMMENT "sensor type"
)
ENGINE=OLAP
DUPLICATE KEY (id)
DISTRIBUTED BY HASH(`id`);
注意
自 2.5.7 版本起,StarRocks 支持在建表和新增分区时自动设置分桶数量 (BUCKETS),您无需手动设置分桶数量。更多信息,请参见 设置分桶数量。
导入作业
提交一个导入作业 sensor_log_load_job,持续消费 Kafka 集群中 Topic topic_0 的 Avro 消息,并将其导入到数据库 sensor 中的表 sensor_log。并且导入作业会从此 Topic 所指定分区的最早位点开始消费。
CREATE ROUTINE LOAD example_db.sensor_log_load_job ON sensor_log
PROPERTIES
(
"format" = "avro"
)
FROM KAFKA
(
"kafka_broker_list" = "<kafka_broker1_ip>:<kafka_broker1_port>,<kafka_broker2_ip>:<kafka_broker2_port>,...",
"confluent.schema.registry.url" = "http://172.xx.xxx.xxx:8081",
"kafka_topic" = "topic_0",
"kafka_partitions" = "0,1,2,3,4,5",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
);
-
数据格式
在
PROPERTIES子句中,通过配置"format" = "avro"指定数据格式为 Avro。 -
Schema Registry
通过 confluent.schema.registry.url 参数指定注册该 Avro schema 的 Schema Registry 的 URL,StarRocks 会从该 URL 获取 Avro schema。格式如下:
confluent.schema.registry.url = http[s]://[<schema-registry-api-key>:<schema-registry-api-secret>@]<hostname|ip address>[:<port>] -
数据映射和转换
如果需要指定源数据和目标表之间列的映射和转换关系,则可以配置
COLUMNS和jsonpaths参数。COLUMNS中的列名对应目标表的列名,列的顺序对应jsonpaths中的字段顺序。jsonpaths参数用于提取 Avro 数据中需要的字段数据,而后(就像新生成的 CSV 数据一样)被COLUMNS参数按顺序临时命名。更多数据转换的说明,请参见导入时实现数据转换。
说明
如果一条 Avro record 中字段的名称和数量(顺序不需要对应)都能对应目标表中列,则无需配置
COLUMNS。
提交导入作业后,您可以执行 SHOW ROUTINE LOAD,查看导入作业执行情况。
数据类型映射
StarRocks 支持导入所有类型的 Avro 数据。导入 Avro 数据至 StarRocks 时,其类型映射关系如下:
原始类型
| Avro | StarRocks |
|---|---|
| null | NULL |
| boolean | BOOLEAN |
| int | INT |
| long | BIGINT |
| float | FLOAT |
| double | DOUBLE |
| bytes | STRING |
| string | STRING |
复杂类型
| Avro | StarRocks |
|---|---|
| record | 将 RECORD 类型的字段或者其子字段中作为 JSON 导入 |
| enums | STRING |
| arrays | ARRAY |
| maps | JSON |
| union(T, null) | NULLABE(T) |
| fixed | STRING |
使用限制
-
StarRocks 暂时不支持 schema evolution,每次仅从 schema registry 服务获取最新版本的 schema 信息。
-
每条 Kafka 消息中应仅包含单条 Avro 数据。
查看导入作业和任务
查看导入作业
执行 SHOW ROUTINE LOAD,查看名称为 example_tbl2_ordertest2 的导入作业的信息,比如导入作业状态State,导入作业的统计信息Statistic(消费的总数据行数、已导入的行数等),消费的分区及进度Progress等。
如果导入作业状态自动变为 PAUSED,则可能为导入任务错误行数超过阈值。错误行数阈值的设置方式,请参考 CREATE ROUTINE LOAD。您可以参考ReasonOfStateChanged、ErrorLogUrls报错进行排查和修复。修复后您可以使用 RESUME ROUTINE LOAD,恢复 PAUSED 状态的导入作业。
如果导入作业状态为 CANCELLED,则可能为导入任务执行遇到异常(如表被删除)。您可以参考ReasonOfStateChanged、ErrorLogUrls报错进行排查和修复。但是修复后,您无法恢复 CANCELLED 状态的导入作业。
MySQL [example_db]> SHOW ROUTINE LOAD FOR example_tbl2_ordertest2 \G
*************************** 1. row ***************************
Id: 63013
Name: example_tbl2_ordertest2
CreateTime: 2022-08-10 17:09:00
PauseTime: NULL
EndTime: NULL
DbName: default_cluster:example_db
TableName: example_tbl2
State: RUNNING
DataSourceType: KAFKA
CurrentTaskNum: 3
JobProperties: {"partitions":"*","partial_update":"false","columnToColumnExpr":"commodity_id,customer_name,country,pay_time,pay_dt=from_unixtime(`pay_time`, '%Y%m%d'),price","maxBatchIntervalS":"20","whereExpr":"*","dataFormat":"json","timezone":"Asia/Shanghai","format":"json","json_root":"","strict_mode":"false","jsonpaths":"[\"$.commodity_id\",\"$.customer_name\",\"$.country\",\"$.pay_time\",\"$.price\"]","desireTaskConcurrentNum":"3","maxErrorNum":"0","strip_outer_array":"false","currentTaskConcurrentNum":"3","maxBatchRows":"200000"}
DataSourceProperties: {"topic":"ordertest2","currentKafkaPartitions":"0,1,2,3,4","brokerList":"<kafka_broker1_ip>:<kafka_broker1_port>,<kafka_broker2_ip>:<kafka_broker2_port>"}
CustomProperties: {"kafka_default_offsets":"OFFSET_BEGINNING"}
Statistic: {"receivedBytes":230,"errorRows":0,"committedTaskNum":1,"loadedRows":2,"loadRowsRate":0,"abortedTaskNum":0,"totalRows":2,"unselectedRows":0,"receivedBytesRate":0,"taskExecuteTimeMs":522}
Progress: {"0":"1","1":"OFFSET_ZERO","2":"OFFSET_ZERO","3":"OFFSET_ZERO","4":"OFFSET_ZERO"}
ReasonOfStateChanged:
ErrorLogUrls:
OtherMsg:
注意
StarRocks 只支持查看当前正在运行中的导入作业,不支持查看已经停止和未开始的导入作业。
查看导入任务
执行 SHOW ROUTINE LOAD TASK,查看导入作业example_tbl2_ordertest2 中一个或多个导入任务的信息。比如当前有多少任务正在运行,消费分区及进度DataSourceProperties,以及对应的 Coordinator BE 节点 BeId。
MySQL [example_db]> SHOW ROUTINE LOAD TASK WHERE JobName = "example_tbl2_ordertest2" \G
*************************** 1. row ***************************
TaskId: 18c3a823-d73e-4a64-b9cb-b9eced026753
TxnId: -1
TxnStatus: UNKNOWN
JobId: 63013
CreateTime: 2022-08-10 17:09:05
LastScheduledTime: 2022-08-10 17:47:27
ExecuteStartTime: NULL
Timeout: 60
BeId: -1
DataSourceProperties: {"1":0,"4":0}
Message: there is no new data in kafka, wait for 20 seconds to schedule again
*************************** 2. row ***************************
TaskId: f76c97ac-26aa-4b41-8194-a8ba2063eb00
TxnId: -1
TxnStatus: UNKNOWN
JobId: 63013
CreateTime: 2022-08-10 17:09:05
LastScheduledTime: 2022-08-10 17:47:26
ExecuteStartTime: NULL
Timeout: 60
BeId: -1
DataSourceProperties: {"2":0}
Message: there is no new data in kafka, wait for 20 seconds to schedule again
*************************** 3. row ***************************
TaskId: 1a327a34-99f4-4f8d-8014-3cd38db99ec6
TxnId: -1
TxnStatus: UNKNOWN
JobId: 63013
CreateTime: 2022-08-10 17:09:26
LastScheduledTime: 2022-08-10 17:47:27
ExecuteStartTime: NULL
Timeout: 60
BeId: -1
DataSourceProperties: {"0":2,"3":0}
Message: there is no new data in kafka, wait for 20 seconds to schedule again
暂停导入作业
执行 PAUSE ROUTINE LOAD 语句后,会暂停导入作业。导入作业会进入 PAUSED 状态,但是导入作业未结束,您可以执行 [RESUME R../sql-reference/sql-statements/loading_unloading/routine_load/RESUME_ROUTINE_LOAD.mdUTINE_LOAD.md) 语句重启该导入作业。您也可以执行 SHOW ROUTINE LOAD 语句查看已暂停的导入作业的状态。
例如,可以通过以下语句,暂停导入作业example_tbl2_ordertest2:
PAUSE ROUTINE LOAD FOR example_tbl2_ordertest2;
恢复导入作业
执行 RESUME ROUTINE LOAD,恢复导入作业。导入作业会先短暂地进入 NEED_SCHEDULE 状态,表示正在重新调度导入作业,一段时间后会恢复至 RUNNING 状态,继续消费 Kafka 消息并且导入数据。您可以执行 SHOW ROUTINE LOAD 语句查看已恢复的导入作业。
例如,可以通过以下语句,恢复导入作业example_tbl2_ordertest2:
RESUME ROUTINE LOAD FOR example_tbl2_ordertest2;
修改导入作业
修改前,您需要先执行 PAUSE ROUTINE LOAD 暂停导入作业。然后执行 ALTER ROUTINE LOAD 语句,修改导入作业的参数配置。修改成功后,您需要执行 RESUME ROUTINE LOAD,恢复导入作业。然后执行 SHOW ROUTINE LOAD 语句查看修改后的导入作业。
例如,当存活 BE 节点数增至 6 个,待消费分区为"0,1,2,3,4,5,6,7"时,如果您希望提高实际的导入并行度,则可以通过以下语句,将期望任务并行度desired_concurrent_number 增加至 6(大于等于存活 BE 节点数),并且调整待消费分区和起始消费位点。
说明
由于实际导入并行度由多个参数的最小值决定,此时,您还需要确保 FE 动态参数
max_routine_load_task_concurrent_num的值大于或等于6。
ALTER ROUTINE LOAD FOR example_tbl2_ordertest2
PROPERTIES
(
"desired_concurrent_number" = "6"
)
FROM kafka
(
"kafka_partitions" = "0,1,2,3,4,5,6,7",
"kafka_offsets" = "OFFSET_BEGINNING,OFFSET_BEGINNING,OFFSET_BEGINNING,OFFSET_BEGINNING,OFFSET_END,OFFSET_END,OFFSET_END,OFFSET_END"
);
停止导入作业
执行 STOP ROUTINE LOAD,可以停止导入作业。导入作业会进入 STOPPED 状态,代表此导入作业已经结束,且无法恢复。再次执行 SHOW ROUTINE LOAD 语句,将无法看到已经停止的导入作业。
例如,可以通过以下语句,停止导入作业example_tbl2_ordertest2:
STOP ROUTINE LOAD FOR example_tbl2_ordertest2;
常见问题
请参见 Routine Load 常见问题。
