部署使用 StarRocks 存算分离集群
本文介绍如何部署和使用 StarRocks 存算分离集群。该功能从 3.0 版本开始支持。
StarRocks 存算分离集群采用了存储计算分离架构,特别为云存储设计。在存算分离的模式下,StarRocks 将数据存储在兼容 S3 协议的对象存储(例如 AWS S3、OSS 以及 MinIO)或 HDFS 中,而本地盘作为热数据缓存,用以加速查询。通过存储计算分离架构,您可以降低存储成本并且优化资源隔离。除此之外,集群的弹性扩展能力也得以加强。在查询命中缓存的情况下,存算分离集群的查询性能与存算一体集群性能一致。
相对存算一体架构,StarRocks 的存储计算分离架构提供以下优势:
- 廉价且可无缝扩展的存储。
- 弹性可扩展的计算能力。由于数据不存储在 CN 节点中,因此集群无需进行跨节点数据迁移或 Shuffle 即可完成扩缩容。
- 热数据的本地磁盘缓存,用以提高查询性能。
- 可选异步导入数据至对象存储,提高导入效率。
StarRocks 存算分离集群架构如下:
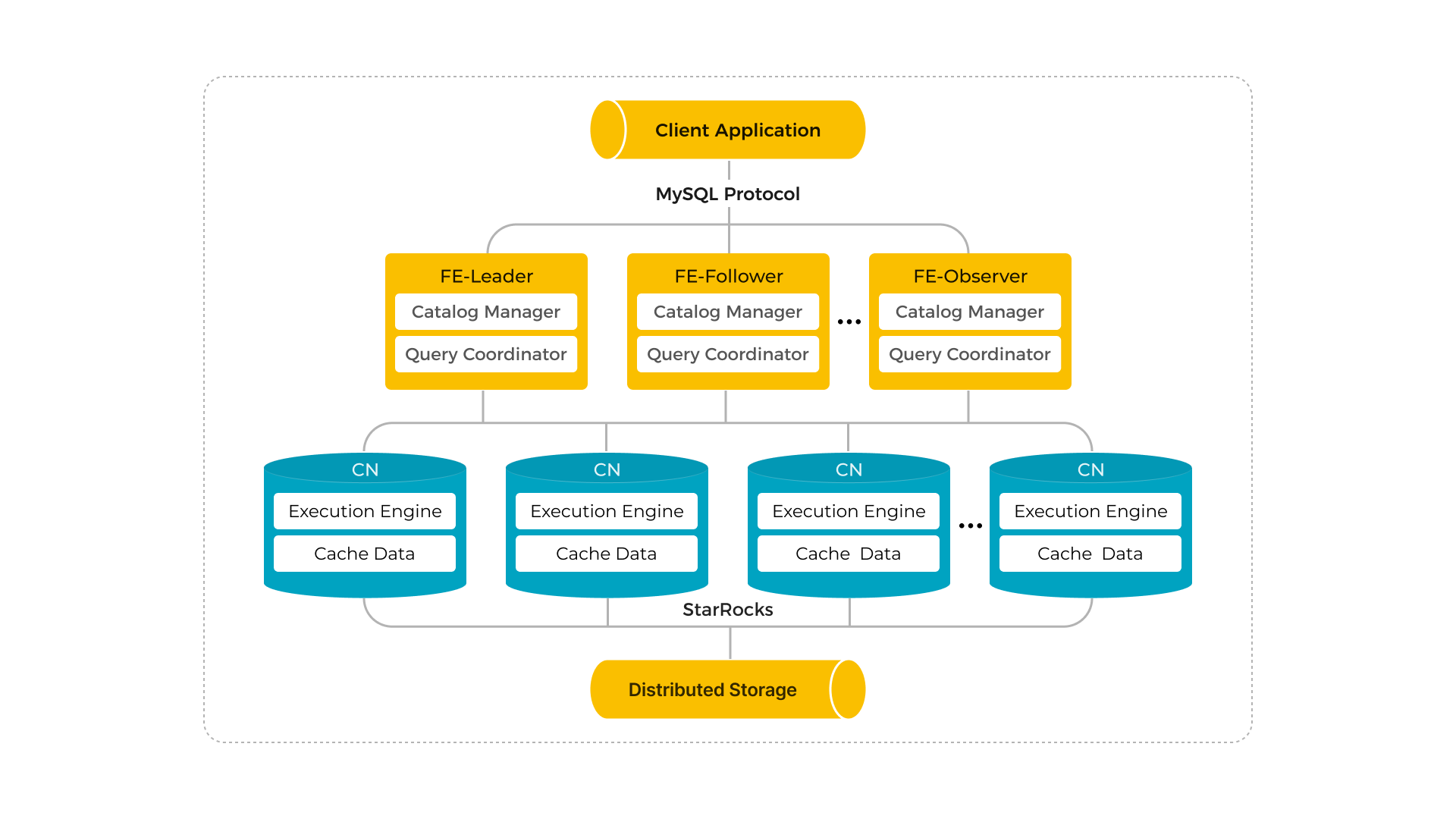
说明
StarRocks 存算分离集群不支持数据备份和恢复。
部署 StarRocks 存算分离集群
StarRocks 存算分离集群的部署方式与存算一体集群的部署方式类似,但存算分离集群需要部署 CN 节点而非 BE 节点。本小节仅列出部署 StarRocks 存算分离集群时需要添加到 FE 和 CN 配置文件 fe.conf 和 cn.conf 中的额外配置项。有关部署 StarRocks 集群的详细说明,请参阅 部署 StarRocks。
配置存算分离集群 FE 节点
在启动 FE 之前,在 FE 配置文件 fe.conf 中添加以下配置项:
| 配置项 | 描述 |
|---|---|
| run_mode | StarRocks 集群的运行模式。有效值:shared_data 和 shared_nothing (默认)。shared_data 表示在存算分离模式下运行 StarRocks。shared_nothing 表示在存算一体模式下运行 StarRocks。注意 StarRocks 集群不支持存算分离和存算一体模式混合部署。 请勿在集群部署完成后更改 run_mode,否则将导致集群无法再次启动。不支持从存算一体集群转换为存算分离集群,反之亦然。 |
| cloud_native_meta_port | 云原生元数据服务监听端口。默认值:6090。 |
| enable_load_volume_from_conf | 是否允许 StarRocks 使用 FE 配置文件中指定的存储相关属性创建默认存储卷。有效值:true(默认)和 false。自 v3.1.0 起支持。
建议您在升级现有的 v3.0 存算分离集群时,保留此项的默认配置 true。如果将此项修改为 false,升级前创建的数据库和表将变为只读,您无法向其中导入数据。 |
| cloud_native_storage_type | 您使用的存储类型。在存算分离模式下,StarRocks 支持将数据存储在 HDFS 、Azure Blob(自 v3.1.1 起支持)、以及兼容 S3 协议的对象存储中(例如 AWS S3、Google GCP、阿里云 OSS 以及 MinIO)。有效值:S3(默认)、AZBLOB 和 HDFS。如果您将此项指定为 S3,则必须添加以 aws_s3 为前缀的配置项。如果您将此项指定为 AZBLOB,则必须添加以 azure_blob 为前缀的配置项。如果将此项指定为 HDFS,则只需指定 cloud_native_hdfs_url。 |
| cloud_native_hdfs_url | HDFS 存储的 URL,例如 hdfs://127.0.0.1:9000/user/xxx/starrocks/。 |
| aws_s3_path | 用于存储数据的 S3 存储空间路径,由 S3 存储桶的名称及其下的子路径(如有)组成,如 testbucket/subpath。 |
| aws_s3_region | 需访问的 S3 存储空间的地区,如 us-west-2。 |
| aws_s3_endpoint | 访问 S3 存储空间的连接地址,如 https://s3.us-west-2.amazonaws.com。 |
| aws_s3_use_aws_sdk_default_behavior | 是否使用 AWS SDK 默认的认证凭证。有效值:true 和 false (默认)。 |
| aws_s3_use_instance_profile | 是否使用 Instance Profile 或 Assumed Role 作为安全凭证访问 S3。有效值:true 和 false (默认)。
|
| aws_s3_access_key | 访问 S3 存储空间的 Access Key。 |
| aws_s3_secret_key | 访问 S3 存储空间的 Secret Key。 |
| aws_s3_iam_role_arn | 有访问 S3 存储空间权限 IAM Role 的 ARN。 |
| aws_s3_external_id | 用于跨 AWS 账户访问 S3 存储空间的外部 ID。 |
| azure_blob_path | 用于存储数据的 Azure Blob Storage 路径,由 Storage Account 中的容器名称和容器下的子路径(如有)组成,如 testcontainer/subpath。 |
| azure_blob_endpoint | Azure Blob Storage 的链接地址,如 https://test.blob.core.windows.net。 |
| azure_blob_shared_key | 访问 Azure Blob Storage 的 Shared Key。 |
| azure_blob_sas_token | 访问 Azure Blob Storage 的共享访问签名(SAS)。 |
注意
成功创建存算分离集群后,您只能修改与安全凭证相关的配置项。如果您更改了原有存储路径相关的配置项,则在此之前创建的数据库和表将变为只读,您无法向其中导入数据。
如果您想在集群创建后手动创建默认存储卷,则只需添加以下配置项:
run_mode = shared_data
cloud_native_meta_port = <meta_port>
enable_load_volume_from_conf = false
如果您想在 FE 配置文件中指定存储相关的属性,示例如下:
-
如果您使用 HDFS 存储,请添加以下配置项:
run_mode = shared_data
cloud_native_meta_port = <meta_port>
cloud_native_storage_type = HDFS
cloud_native_hdfs_url = <hdfs_url> -
如果您使用 AWS S3:
-
如果您使用 AWS SDK 默认的认证凭证,请添加以下配置项:
run_mode = shared_data
cloud_native_meta_port = <meta_port>
cloud_native_storage_type = S3
# 如 testbucket/subpath
aws_s3_path = <s3_path>
# 如 us-west-2
aws_s3_region = <region>
# 如 https://s3.us-west-2.amazonaws.com
aws_s3_endpoint = <endpoint_url>
aws_s3_use_aws_sdk_default_behavior = true -
如果您使用 IAM user-based 认证,请添加以下配置项:
run_mode = shared_data
cloud_native_meta_port = <meta_port>
cloud_native_storage_type = S3
aws_s3_path = <s3_path>
aws_s3_region = <region>
aws_s3_endpoint = <endpoint_url>
aws_s3_access_key = <access_key>
aws_s3_secret_key = <secret_key> -
如果您使用 Instance Profile 认证,请添加以下配置项:
run_mode = shared_data
cloud_native_meta_port = <meta_port>
cloud_native_storage_type = S3
# 如 testbucket/subpath
aws_s3_path = <s3_path>
# 如 us-west-2
aws_s3_region = <region>
# 如 https://s3.us-west-2.amazonaws.com
aws_s3_endpoint = <endpoint_url>
aws_s3_use_instance_profile = true -
如果您使用 Assumed Role 认证,请添加以下配置项:
run_mode = shared_data
cloud_native_meta_port = <meta_port>
cloud_native_storage_type = S3
# 如 testbucket/subpath
aws_s3_path = <s3_path>
# 如 us-west-2
aws_s3_region = <region>
# 如 https://s3.us-west-2.amazonaws.com
aws_s3_endpoint = <endpoint_url>
aws_s3_use_instance_profile = true
aws_s3_iam_role_arn = <role_arn> -
如果您使用外部 AWS 账户通过 Assumed Role 认证,请添加以下配置项:
run_mode = shared_data
cloud_native_meta_port = <meta_port>
cloud_native_storage_type = S3
# 如 testbucket/subpath
aws_s3_path = <s3_path>
# 如 us-west-2
aws_s3_region = <region>
# 如 https://s3.us-west-2.amazonaws.com
aws_s3_endpoint = <endpoint_url>
aws_s3_use_instance_profile = true
aws_s3_iam_role_arn = <role_arn>
aws_s3_external_id = <external_id>
-
-
如果您使用 Azure Blob Storage(自 v3.1.1 起支持):
-
如果您使用共享密钥(Shared Key)认证,请添加以下配置项:
run_mode = shared_data
cloud_native_meta_port = <meta_port>
cloud_native_storage_type = AZBLOB
# 如 testcontainer/subpath
azure_blob_path = <blob_path>
# 如 https://test.blob.core.windows.net
azure_blob_endpoint = <endpoint_url>
azure_blob_shared_key = <shared_key> -
如果您使用共享访问签名(SAS)认证,请添加以下配置项:
run_mode = shared_data
cloud_native_meta_port = <meta_port>
cloud_native_storage_type = AZBLOB
# 如 testcontainer/subpath
azure_blob_path = <blob_path>
# 如 https://test.blob.core.windows.net
azure_blob_endpoint = <endpoint_url>
azure_blob_sas_token = <sas_token>
注意
创建 Azure Blob Storage Account 时必须禁用分层命名空间。
-
-
如果您使用 GCP Cloud Storage:
run_mode = shared_data
cloud_native_meta_port = <meta_port>
cloud_native_storage_type = S3
# 如 testbucket/subpath
aws_s3_path = <s3_path>
# 例如:us-east-1
aws_s3_region = <region>
# 例如:https://storage.googleapis.com
aws_s3_endpoint = <endpoint_url>
aws_s3_access_key = <access_key>
aws_s3_secret_key = <secret_key> -
如果您使用阿里云 OSS:
run_mode = shared_data
cloud_native_meta_port = <meta_port>
cloud_native_storage_type = S3
# 如 testbucket/subpath
aws_s3_path = <s3_path>
# 例如:cn-zhangjiakou
aws_s3_region = <region>
# 例如:https://oss-cn-zhangjiakou-internal.aliyuncs.com
aws_s3_endpoint = <endpoint_url>
aws_s3_access_key = <access_key>
aws_s3_secret_key = <secret_key> -
如果您使用华为云 OBS:
run_mode = shared_data
cloud_native_meta_port = <meta_port>
cloud_native_storage_type = S3
# 如 testbucket/subpath
aws_s3_path = <s3_path>
# 例如:cn-north-4
aws_s3_region = <region>
# 例如:https://obs.cn-north-4.myhuaweicloud.com
aws_s3_endpoint = <endpoint_url>
aws_s3_access_key = <access_key>
aws_s3_secret_key = <secret_key> -
如果您使用腾讯云 COS:
run_mode = shared_data
cloud_native_meta_port = <meta_port>
cloud_native_storage_type = S3
# 如 testbucket/subpath
aws_s3_path = <s3_path>
# 例如:ap-beijing
aws_s3_region = <region>
# 例如:https://cos.ap-beijing.myqcloud.com
aws_s3_endpoint = <endpoint_url>
aws_s3_access_key = <access_key>
aws_s3_secret_key = <secret_key> -
如果您使用火山引擎 TOS:
run_mode = shared_data
cloud_native_meta_port = <meta_port>
cloud_native_storage_type = S3
# 如 testbucket/subpath
aws_s3_path = <s3_path>
# 例如:cn-beijing
aws_s3_region = <region>
# 例如:https://tos-s3-cn-beijing.ivolces.com
aws_s3_endpoint = <endpoint_url>
aws_s3_access_key = <access_key>
aws_s3_secret_key = <secret_key> -
如果您使用金山云:
run_mode = shared_data
cloud_native_meta_port = <meta_port>
cloud_native_storage_type = S3
# 如 testbucket/subpath
aws_s3_path = <s3_path>
# 例如:BEIJING
aws_s3_region = <region>
# 注意请使用三级域名, 金山云不支持二级域名
# 例如:jeff-test.ks3-cn-beijing.ksyuncs.com
aws_s3_endpoint = <endpoint_url>
aws_s3_access_key = <access_key>
aws_s3_secret_key = <secret_key> -
如果您使用 MinIO:
run_mode = shared_data
cloud_native_meta_port = <meta_port>
cloud_native_storage_type = S3
# 如 testbucket/subpath
aws_s3_path = <s3_path>
# 例如:us-east-1
aws_s3_region = <region>
# 例如:http://172.26.xx.xxx:39000
aws_s3_endpoint = <endpoint_url>
aws_s3_access_key = <access_key>
aws_s3_secret_key = <secret_key> -
如果您使用 Ceph S3:
run_mode = shared_data
cloud_native_meta_port = <meta_port>
cloud_native_storage_type = S3
# 如 testbucket/subpath
aws_s3_path = <s3_path>
# 例如:http://172.26.xx.xxx:7480
aws_s3_endpoint = <endpoint_url>
aws_s3_access_key = <access_key>
aws_s3_secret_key = <secret_key>
配置存算分离集群 CN 节点
在启动 CN 之前,在 CN 配置文件 cn.conf 中添加以下配置项:
starlet_port = <starlet_port>
storage_root_path = <storage_root_path>
| 配置项 | 描述 |
|---|---|
| starlet_port | 存算分离模式下,用于 CN 心跳服务的端口。默认值:9070。 |
| storage_root_path | 本地缓存数据依赖的存储目录,多块盘配置使用分号(;)隔开。例如:/data1;/data2。默认值:${STARROCKS_HOME}/storage。 |
说明
本地缓存数据将存储在
<storage_root_path>/starlet_cache路径下。
使用 StarRocks 存算分离集群
StarRocks 存算分离集群的使用也类似于 StarRocks 存算一体集群,不同之处在于存算分离集群需要使用存储卷和云原生表才能将数据持久化到 HDFS 或对象存储。
创建默认存储卷
您可以使用 StarRocks 自动创建的内置存储卷,也可以手动创建和设置默认存储卷。本节介绍如何手动创建并设置默认存储卷。
说明
如果您的 StarRocks 存算分离集群是由 v3.0 升级,则无需定义默认存储卷。 StarRocks 会根据您在 FE 配置文件 fe.conf 中指定的相关配置项自动创建默认存储卷。您仍然可以使用其他远程数据存储资源创建新的存储卷或定义其他存储卷为默认。
为了确保 StarRocks 存算分离集群有权限在远程数据源中存储数据,您必须在创建数据库或云原生表时引用存储卷。存储卷由远程数据存储系统的属性和凭证信息组成。在部署新 StarRocks 存算分离集群时,如果您禁止了 StarRocks 创建内置存储卷 (将 enable_load_volume_from_conf 设置为 false),则启动后必须先创建和设置默认存储卷,然后才能在集群中创建数据库和表。
以下示例使用 IAM user-based 认证为 AWS S3 存储空间 defaultbucket 创建存储卷 def_volume,激活并将其设置为默认存储卷:
CREATE STORAGE VOLUME def_volume
TYPE = S3
LOCATIONS = ("s3://defaultbucket/test/")
PROPERTIES
(
"enabled" = "true",
"aws.s3.region" = "us-west-2",
"aws.s3.endpoint" = "https://s3.us-west-2.amazonaws.com",
"aws.s3.use_aws_sdk_default_behavior" = "false",
"aws.s3.use_instance_profile" = "false",
"aws.s3.access_key" = "xxxxxxxxxx",
"aws.s3.secret_key" = "yyyyyyyyyy"
);
SET def_volume AS DEFAULT STORAGE VOLUME;
有关如何为其他远程存储创建存储卷和设置默认存储卷的更多信息,请参阅 CREATE STORAGE VOLUME 和 SET DEFAULT STORAGE VOLUME。
创建数据库和云原生表
创建默认存储卷后,您可以使用该存储卷创建数据库和云原生表。
目前,StarRocks 存算分离集群支持以下数据模型:
- 明细模型(Duplicate Key)
- 聚合模型(Aggregate Key)
- 更新模型(Unique Key)
- 主键模型(Primary Key)(当前暂不支持持久化主键索引)
以下示例创建数据库 cloud_db,并基于明细模型创建表 detail_demo,启用本地磁盘缓存,将热数据有效期设置为一个月,并禁用异步数据导入:
CREATE DATABASE cloud_db;
USE cloud_db;
CREATE TABLE IF NOT EXISTS detail_demo (
recruit_date DATE NOT NULL COMMENT "YYYY-MM-DD",
region_num TINYINT COMMENT "range [-128, 127]",
num_plate SMALLINT COMMENT "range [-32768, 32767] ",
tel INT COMMENT "range [-2147483648, 2147483647]",
id BIGINT COMMENT "range [-2^63 + 1 ~ 2^63 - 1]",
password LARGEINT COMMENT "range [-2^127 + 1 ~ 2^127 - 1]",
name CHAR(20) NOT NULL COMMENT "range char(m),m in (1-255) ",
profile VARCHAR(500) NOT NULL COMMENT "upper limit value 65533 bytes",
ispass BOOLEAN COMMENT "true/false")
DUPLICATE KEY(recruit_date, region_num)
DISTRIBUTED BY HASH(recruit_date, region_num)
PROPERTIES (
"storage_volume" = "def_volume",
"datacache.enable" = "true",
"datacache.partition_duration" = "1 MONTH",
"enable_async_write_back" = "false"
);
说明
当您在 StarRocks 存算分离集群中创建数据库或云原生表时,如果未指定存储卷,StarRocks 将使用默认存储卷。
除了常规表 PROPERTIES 之外,您还需要在创建表时指定以下 PROPERTIES:
| 属性 | 描述 |
|---|---|
| datacache.enable | 是否启用本地磁盘缓存。默认值:true。
如需启用本地磁盘缓存,必须在 CN 配置项 storage_root_path 中指定磁盘目录。 |
| datacache.partition_duration | 热数据的有效期。当启用本地磁盘缓存时,所有数据都会导入至本地磁盘缓存中。当缓存满时,StarRocks 会从缓存中删除最近较少使用(Less recently used)的数据。当有查询需要扫描已删除的数据时,StarRocks 会检查该数据是否在有效期内。如果数据在有效期内,StarRocks 会再次将数据导入至缓存中。如果数据不在有效期内,StarRocks 不会将其导入至缓存中。该属性为字符串,您可以使用以下单位指定:YEAR、MONTH、DAY 和 HOUR,例如,7 DAY 和 12 HOUR。如果不指定,StarRocks 将所有数据都作为热数据进行缓存。说明 仅当 datacache.enable 设置为 true 时,此属性可用。 |
| enable_async_write_back | 是否允许数据异步写入对象存储。默认值:false。
|
查看表信息
您可以通过 SHOW PROC "/dbs/<db_id>" 查看特定数据库中的表的信息。详细信息,请参阅 SHOW PROC。
示例:
mysql> SHOW PROC "/dbs/xxxxx";
+---------+-------------+----------+---------------------+--------------+--------+--------------+--------------------------+--------------+---------------+------------------------------+
| TableId | TableName | IndexNum | PartitionColumnName | PartitionNum | State | Type | LastConsistencyCheckTime | ReplicaCount | PartitionType | StoragePath |
+---------+-------------+----------+---------------------+--------------+--------+--------------+--------------------------+--------------+---------------+------------------------------+
| 12003 | detail_demo | 1 | NULL | 1 | NORMAL | CLOUD_NATIVE | NULL | 8 | UNPARTITIONED | s3://xxxxxxxxxxxxxx/1/12003/ |
+---------+-------------+----------+---------------------+--------------+--------+--------------+--------------------------+--------------+---------------+------------------------------+
StarRocks 存算分离集群中表的 Type 为 CLOUD_NATIVE。StoragePath 字段为表在对象存储中的路径。
向 StarRocks 存算分离集群导入数据
StarRocks 存算分离集群支持 StarRocks 提供的所有导入方式。详细信息,请参阅 导入总览。
在 StarRocks 存算分离集群查询
StarRocks 存算分离集群支持 StarRocks 提供的所有查询方式。详细信息,请参阅 SELECT。
