Apache Hudi レイクハウス
概要
- Docker compose を使用して、オブジェクトストレージ、Apache Spark、Hudi、および StarRocks をデプロイ
- Apache Spark を使用して Hudi に小さなデータセットをロード
- StarRocks を設定して、external catalog を使用して Hive Metastore にアクセス
- データが存在する場所で StarRocks を使用してデータをクエリ
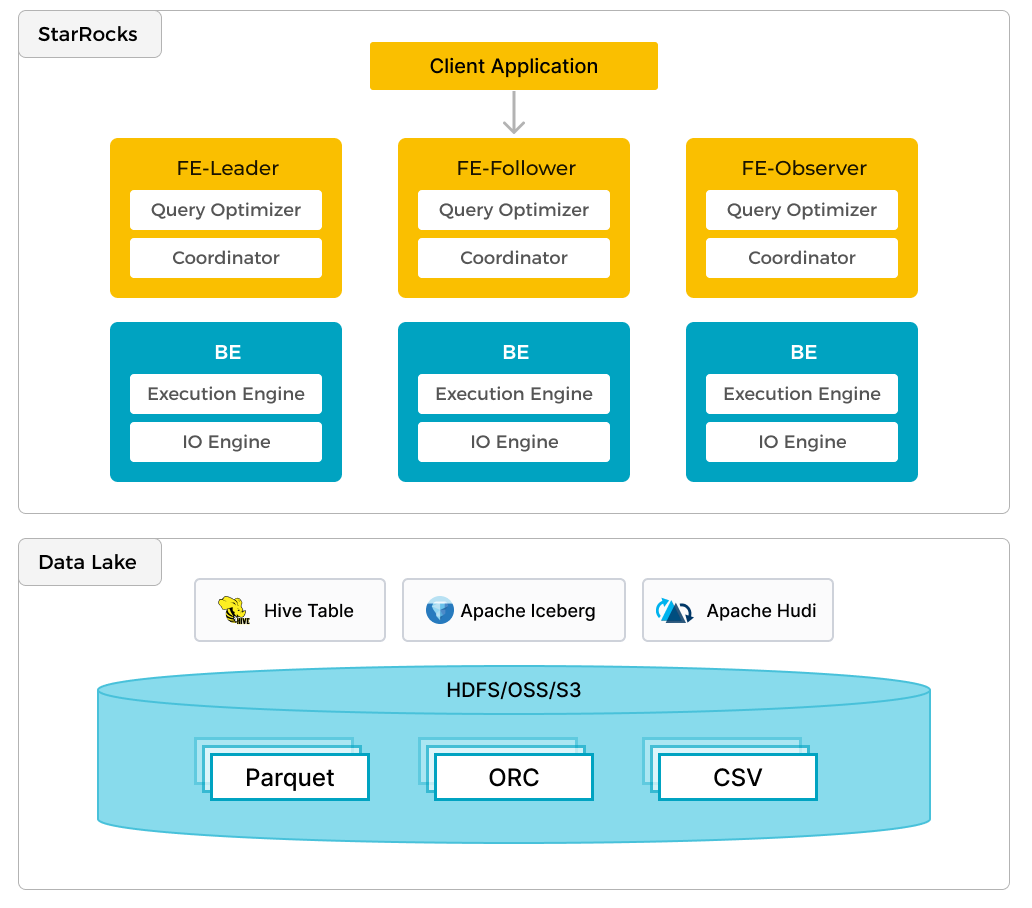
StarRocks は、ローカルデータの効率的な分析に加えて、データレイクに保存されたデータを分析するためのコンピュートエンジンとしても機能します。Apache Hudi、Apache Iceberg、Delta Lake などが含まれます。StarRocks の主要な機能の一つは、外部で管理されているメタストアへのリンクとして機能する external catalog です。この機能により、データ移行の必要なく、外部データソースをシームレスにクエリすることができます。そのため、ユーザーは HDFS や Amazon S3 などの異なるシステムから、Parquet、ORC、CSV などのさまざまなファイル形式でデータを分析できます。
前述の図は、StarRocks がデータの計算と分析を担当し、データレイクがデータの保存、組織化、メンテナンスを担当するデータレイク分析のシナリオを示しています。データレイクは、ユーザーがオープンストレージ形式でデータを保存し、柔軟なスキーマを使用して、さまざまな BI、AI、アドホッ��ク、およびレポート用途の「単一の真実の源」に基づくレポートを作成することを可能にします。StarRocks は、そのベクトル化エンジンと CBO の利点を十分に活用し、データレイク分析のパフォーマンスを大幅に向上させます。
前提条件
StarRocks demo リポジトリ
StarRocks demo リポジトリ をローカルマシンにクローンします。
このガイドのすべての手順は、クローンした demo GitHub リポジトリの demo/documentation-samples/hudi/ ディレクトリから実行されます。
Docker
- Docker セットアップ: Mac の場合は、Install Docker Desktop on Mac に定義されている手順に従ってください。Spark-SQL クエリを実行するには、少なくとも 5 GB のメモリと 4 つの CPU を Docker に割り当ててください (Docker → Preferences → Advanced を参照)。そうしないと、メモリの問題で Spark-SQL クエリが終了される可能性があり�ます。
- Docker に割り当てられた 20 GB の空きディスクスペース
SQL クライアント
Docker 環境で提供される SQL クライアントを使用するか、システム上のものを使用できます。多くの MySQL 互換クライアントが動作します。
設定
demo/documentation-samples/hudi ディレクトリに移動し、ファイルを確認します。これは Hudi のチュートリアルではないため、すべての設定ファイルについて説明するわけではありませんが、どのように設定されているかを確認するためにどこを見ればよいかを知っておくことが重要です。hudi/ ディレクトリには、Docker でサービスを起動および設定するために使用される docker-compose.yml ファイルがあります。これらのサービスとその簡単な説明のリストを以下に示します。
Docker サービス
| サービス | 責任 |
|---|---|
starrocks-fe | メタデータ管理、クライアント接続、クエリプランとスケジューリング |
starrocks-be | ��クエリプランの実行 |
metastore_db | Hive メタデータを保存するために使用される Postgres DB |
hive_metastore | Apache Hive メタストアを提供 |
minio と mc | MinIO オブジェクトストレージと MinIO コマンドラインクライアント |
spark-hudi | 分散コンピューティングとトランザクショナルデータレイクプラットフォーム |
設定ファイル
hudi/conf/ ディレクトリには、spark-hudi コンテナにマウントされる設定ファイルがあります。
core-site.xml
このファイルには、オブジェクトストレージに関連する設定が含まれています。詳細はこのドキュメントの最後にあります。
spark-defaults.conf
Hive、MinIO、および Spark SQL の設定。
hudi-defaults.conf
spark-shell の警告を抑制するために使用されるデフォルトファイル。
hadoop-metrics2-hbase.properties
spark-shell の警告を抑制するために使用される空のファイル。
hadoop-metrics2-s3a-file-system.properties
spark-shell の警告を抑制するために使用される空のファイル。
デモクラスターの起動
このデモシステムは、StarRocks、Hudi、MinIO、および Spark サービスで構成されています。Docker compose を実行してクラスターを起動します。
docker compose up --detach --wait --wait-timeout 60
[+] Running 8/8
✔ Network hudi Created 0.0s
✔ Container hudi-starrocks-fe-1 Healthy 0.1s
✔ Container hudi-minio-1 Healthy 0.1s
✔ Container hudi-metastore_db-1 Healthy 0.1s
✔ Container hudi-starrocks-be-1 Healthy 0.0s
✔ Container hudi-mc-1 Healthy 0.0s
✔ Container hudi-hive-metastore-1 Healthy 0.0s
✔ Container hudi-spark-hudi-1 Healthy 0.1s
多くのコンテナが実行されている場合、docker compose ps の出力は jq にパイプすると読みやすくなります。
docker compose ps --format json | \
jq '{Service: .Service, State: .State, Status: .Status}'
{
"Service": "hive-metastore",
"State": "running",
"Status": "Up About a minute (healthy)"
}
{
"Service": "mc",
"State": "running",
"Status": "Up About a minute"
}
{
"Service": "metastore_db",
"State": "running",
"Status": "Up About a minute"
}
{
"Service": "minio",
"State": "running",
"Status": "Up About a minute"
}
{
"Service": "spark-hudi",
"State": "running",
"Status": "Up 33 seconds (healthy)"
}
{
"Service": "starrocks-be",
"State": "running",
"Status": "Up About a minute (healthy)"
}
{
"Service": "starrocks-fe",
"State": "running",
"Status": "Up About a minute (healthy)"
}
MinIO の設定
Spark コマンドを実行するときに、作成されるテーブルのベースパスを s3a URI に設定します。
val basePath = "s3a://huditest/hudi_coders"
このステップでは、MinIO にバケット huditest を作成します。MinIO コンソールはポート 9000 で実行されています。
MinIO に認証
ブラウザを開いて http://localhost:9000/ にアクセスし、認証します。ユーザー名とパスワードは docker-compose.yml に指定されており、それぞれ admin と password です。
バケットの作成
左側のナビゲーションで Buckets を選択し、次に Create Bucket + を選択します。�バケット名を huditest とし、Create Bucket を選択します。
テーブルを作成してデータを投入し、Hive に同期
このコマンドおよび他の docker compose コマンドは、docker-compose.yml ファイルを含むディレクトリから実行してください。
spark-hudi サービスで spark-shell を開きます。
docker compose exec spark-hudi spark-shell
spark-shell の起動時に不正なリフレクティブアクセスに関する警告が表示されますが、これらの警告は無視して構いません。
scala> プロンプトで次のコマンドを実行して、以下を行います。
- この Spark セッションを設定してデータをロード、処理、書き込み
- データフレームを作成し、それを Hudi テーブルに書き込み
- Hive Metastore に同期
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types._
import org.apache.spark.sql.Row
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
import scala.collection.JavaConversions._
val schema = StructType( Array(
StructField("language", StringType, true),
StructField("users", StringType, true),
StructField("id", StringType, true)
))
val rowData= Seq(Row("Java", "20000", "a"),
Row("Python", "100000", "b"),
Row("Scala", "3000", "c"))
val df = spark.createDataFrame(rowData,schema)
val databaseName = "hudi_sample"
val tableName = "hudi_coders_hive"
val basePath = "s3a://huditest/hudi_coders"
df.write.format("hudi").
option(org.apache.hudi.config.HoodieWriteConfig.TABLE_NAME, tableName).
option(RECORDKEY_FIELD_OPT_KEY, "id").
option(PARTITIONPATH_FIELD_OPT_KEY, "language").
option(PRECOMBINE_FIELD_OPT_KEY, "users").
option("hoodie.datasource.write.hive_style_partitioning", "true").
option("hoodie.datasource.hive_sync.enable", "true").
option("hoodie.datasource.hive_sync.mode", "hms").
option("hoodie.datasource.hive_sync.database", databaseName).
option("hoodie.datasource.hive_sync.table", tableName).
option("hoodie.datasource.hive_sync.partition_fields", "language").
option("hoodie.datasource.hive_sync.partition_extractor_class", "org.apache.hudi.hive.MultiPartKeysValueExtractor").
option("hoodie.datasource.hive_sync.metastore.uris", "thrift://hive-metastore:9083").
mode(Overwrite).
save(basePath)
System.exit(0)
次の警告が表示されます。
WARN
org.apache.hudi.metadata.HoodieBackedTableMetadata -
Metadata table was not found at path
s3a://huditest/hudi_coders/.hoodie/metadata
これは無視して構いません。このファイルは、この spark-shell セッション中に自動的に作成されます。
また、次の警告も表示されます。
78184 [main] WARN org.apache.hadoop.fs.s3a.S3ABlockOutputStream -
Application invoked the Syncable API against stream writing to
hudi_coders/.hoodie/metadata/files/.files-0000_00000000000000.log.1_0-0-0.
This is unsupported
この警告は、オブジェクトストレージを使用している場合、書き込み中のログファイルの同期がサポートされていないことを示しています。ファイルは閉じられたときにのみ同期されます。詳細は Stack Overflow を参照してください。
上記の spark-shell セッションの最後のコマンドはコンテナを終了するはずで�すが、終了しない場合は Enter キーを押すと終了します。
StarRocks の設定
StarRocks に接続
提供された starrocks-fe サービスの MySQL クライアントを使用して StarRocks に接続するか、お気に入りの SQL クライアントを使用して、MySQL プロトコルを使用して localhost:9030 に接続するように設定します。
docker compose exec starrocks-fe \
mysql -P 9030 -h 127.0.0.1 -u root --prompt="StarRocks > "
StarRocks と Hudi のリンクを作成
external catalog に関する詳細情報は、このガイドの最後にリンクがあります。このステップで作成される external catalog は、Docker で実行されている Hive Metastore (HMS) へのリンクとして機能します。
CREATE EXTERNAL CATALOG hudi_catalog_hms
PROPERTIES
(
"type" = "hudi",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://hive-metastore:9083",
"aws.s3.use_instance_profile" = "false",
"aws.s3.access_key" = "admin",
"aws.s3.secret_key" = "password",
"aws.s3.enable_ssl" = "false",
"aws.s3.enable_path_style_access" = "true",
"aws.s3.endpoint" = "http://minio:9000"
);
Query OK, 0 rows affected (0.59 sec)
新しいカタログを使用
SET CATALOG hudi_catalog_hms;
Query OK, 0 rows affected (0.01 sec)
Spark で挿入されたデータに移動
SHOW DATABASES;
+--------------------+
| Database |
+--------------------+
| default |
| hudi_sample |
| information_schema |
+--------------------+
2 rows in set (0.40 sec)
USE hudi_sample;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
SHOW TABLES;
+-----------------------+
| Tables_in_hudi_sample |
+-----------------------+
| hudi_coders_hive |
+-----------------------+
1 row in set (0.07 sec)
StarRocks で Hudi のデータをクエリ
このクエリを 2 回実行します。最初のクエリは、StarRocks にデータがまだキャッシュされていないため、完了するのに約 5 秒��かかる場合があります。2 回目のクエリは非常に迅速に完了します。
SELECT * from hudi_coders_hive\G
StarRocks のドキュメントにある一部の SQL クエリは、セミコロンの代わりに \G で終わります。\G は、mysql CLI にクエリ結果を縦に表示させます。
多くの SQL クライアントは縦のフォーマット出力を解釈しないため、mysql CLI を使用していない場合は \G を ; に置き換える必要があります。
*************************** 1. row ***************************
_hoodie_commit_time: 20240208165522561
_hoodie_commit_seqno: 20240208165522561_0_0
_hoodie_record_key: c
_hoodie_partition_path: language=Scala
_hoodie_file_name: bb29249a-b69d-4c32-843b-b7142d8dc51c-0_0-27-1221_20240208165522561.parquet
language: Scala
users: 3000
id: c
*************************** 2. row ***************************
_hoodie_commit_time: 20240208165522561
_hoodie_commit_seqno: 20240208165522561_2_0
_hoodie_record_key: a
_hoodie_partition_path: language=Java
_hoodie_file_name: 12fc14aa-7dc4-454c-b710-1ad0556c9386-0_2-27-1223_20240208165522561.parquet
language: Java
users: 20000
id: a
*************************** 3. row ***************************
_hoodie_commit_time: 20240208165522561
_hoodie_commit_seqno: 20240208165522561_1_0
_hoodie_record_key: b
_hoodie_partition_path: language=Python
_hoodie_file_name: 51977039-d71e-4dd6-90d4-0c93656dafcf-0_1-27-1222_20240208165522561.parquet
language: Python
users: 100000
id: b
3 rows in set (0.15 sec)
まとめ
このチュートリアルでは、StarRocks external catalog を使用して、Hudi external catalog を使用してデータをその場でクエリできることを示しました。Iceberg、Delta Lake、JDBC カタログを使用した他の多くの統合が利用可能です。
このチュートリアルで行ったこと:
- Docker で StarRocks と Hudi/Spark/MinIO 環境をデプロイ
- Apache Spark を使用して Hudi に小さなデータセットをロード
- Hudi カタログへのアクセスを提供するために StarRocks external catalog を設定
- データレイクからデータをコピーせずに StarRocks で SQL を使用してデータをクエリ
詳細情報
Apache Hudi quickstart (Spark を含む)
