Docker で StarRocks をデプロイ
このチュートリアルでは以下をカバーします:
- 単一の Docker コンテナで StarRocks を実行する
- 基本的なデータ変換を含む2つの公開データセットをロードする
- SELECT と JOIN を使用してデータを分析する
- 基本的なデータ変換(ETL の T)
使用するデータは、NYC OpenData と National Centers for Environmental Information によって提供されています。
これらのデータセットは非常に大きいため、このチュートリアルは StarRocks を使用するための入門として設計されています。過去120年分のデータをロードすることはしません。Docker に 4 GB の RAM を割り当てたマシンで Docker イメージを実行し、このデータをロードできます。より大規模でフォールトトレラントなスケーラブルなデプロイメントについては、他のドキュメントを用意しており、後ほど提供します。
このドキュメントには多くの情報が含まれており、最初にステップバイステップの内容が提示され、最後に技術的な詳細が記載されています。これは次の目的を順に果たすためです:
- 読者が StarRocks にデータをロードし、そのデータを分析できるようにする。
- ロード中のデータ変換の基本を説明する。
前提条件
Docker
- Docker
- Docker に割り当てられた 4 GB の RAM
- Docker に割り当てられた 10 GB の空きディスクスペース
SQL クライアント
Docker 環境で提供される SQL クライアントを使用するか、システム上のクライアントを使用できます。多くの MySQL 互換クライアントが動作し、このガイドでは DBeaver と MySQL Workbench の設定をカバーしています。
curl
curl は StarRocks にデータロードジョブを発行し、データセットをダウンロードするために使用されます。OS のプロンプトで curl または curl.exe を実行して、インストールされているか確認してください。curl がインストールされていない場合は、こちらから curl を取得してください。
用語
FE
フロントエンドノードは、メタデータ管理、クライアント接続管理、クエリプランニング、クエリスケジューリングを担当します。各 FE はメモリ内にメタデータの完全なコピーを保存し、維持します。これにより、FEs 間でのサービスの無差別性が保証されます。
BE
バックエンドノードは、データストレージとクエリプランの実行の両方を担当します。
StarRocks を起動する
docker run -p 9030:9030 -p 8030:8030 -p 8040:8040 -itd \
--name quickstart starrocks/allin1-ubuntu
SQL クライアント
これらの3つのクライアントはこのチュートリアルでテストされていますが、1つだけ使用すれば大丈夫です。
- mysql CLI: Docker環境またはあなたのマシンから実行できます。
- DBeaver はコミュニティ版とPro版があります。
- MySQL Workbench
クライアントの設定
- mysql CLI
- DBeaver
- MySQL Workbench
mysql CLIを使用する最も簡単な方法は、StarRocksコンテナ starrocks-fe から実行することです。
docker exec -it quickstart \
mysql -P 9030 -h 127.0.0.1 -u root --prompt="StarRocks > "
mysql CLIをインストールしたい場合は、以下の mysql client install を展開してください。
mysql client install
- macOS: Homebrewを使用していてMySQL Serverが不要な場合、
brew install mysql-client@8.0を実行してCLIをインストールします。 - Linux:
mysqlクライアントのためにリポジトリシステムを確認してください。例えば、yum install mariadb。 - Microsoft Windows: MySQL Community Server をインストールし、提供されているクライアントを実行するか、WSLから
mysqlを実行します。
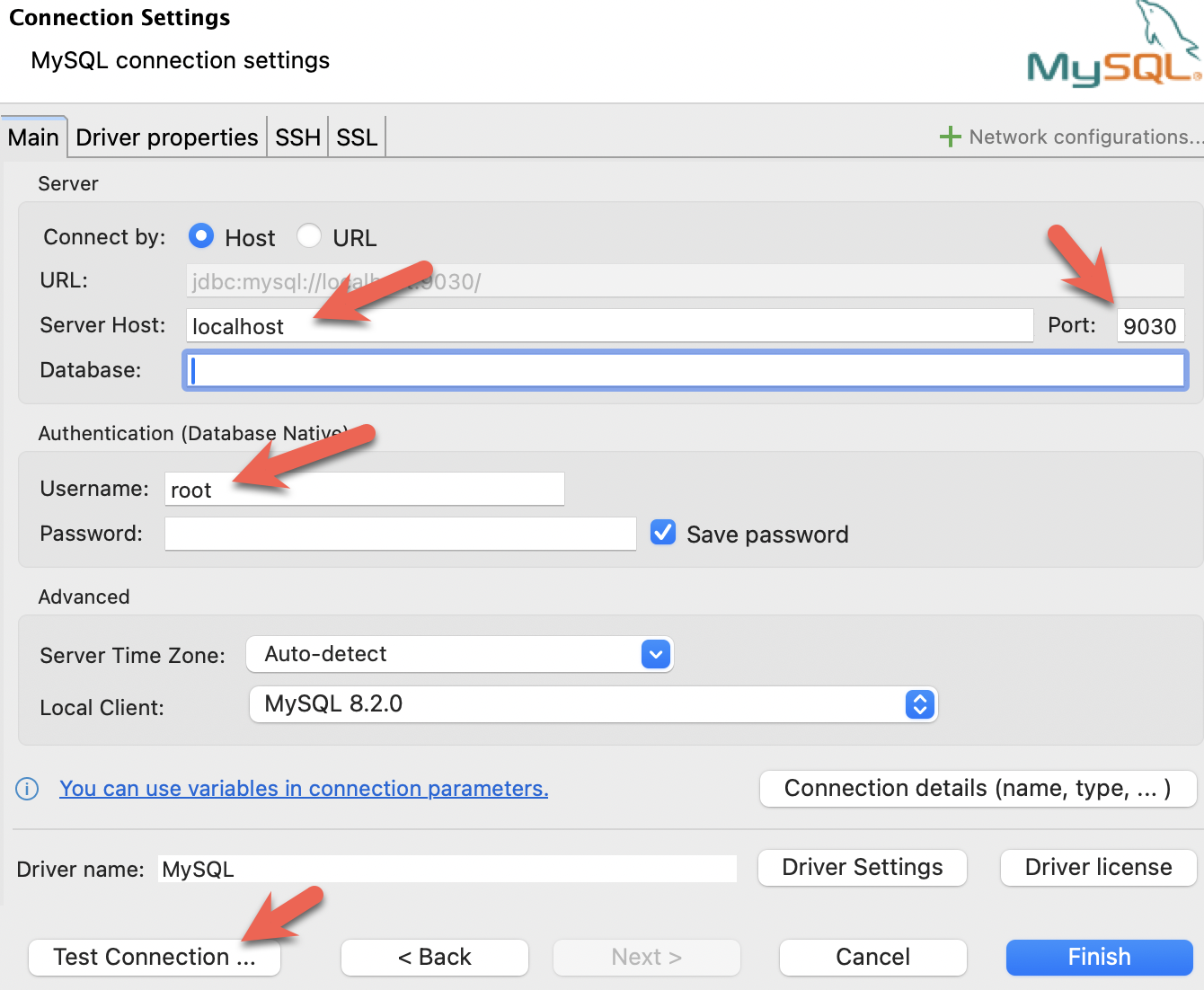
- DBeaver をインストールし、接続を追加します。

- ポート、IP、ユーザー名を設定します。接続をテストし、テストが成功したら完了をクリックします。
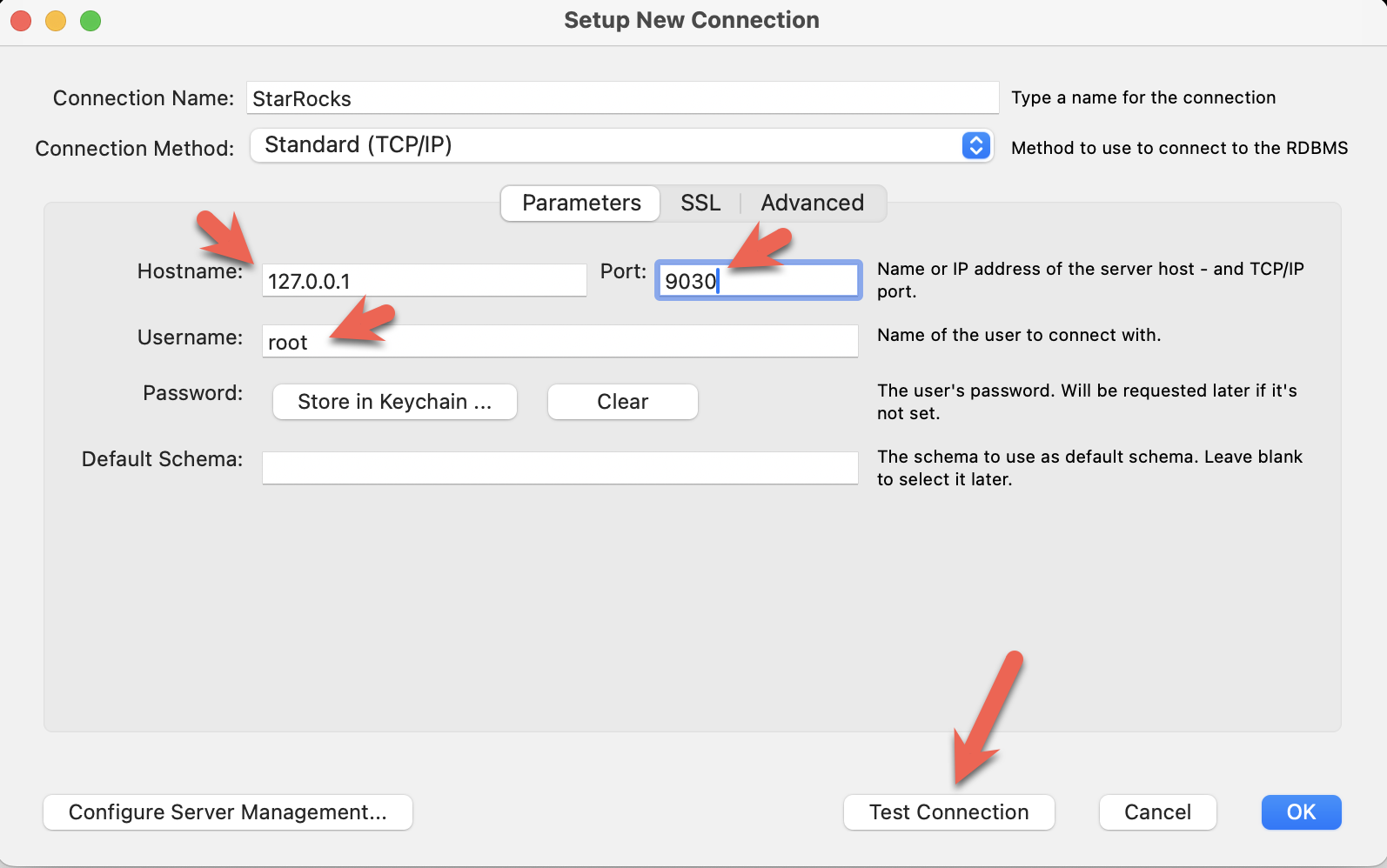
- MySQL Workbench をインストールし、接続を追加します。
- ポート、IP、ユーザー名を設定し、接続をテストします。
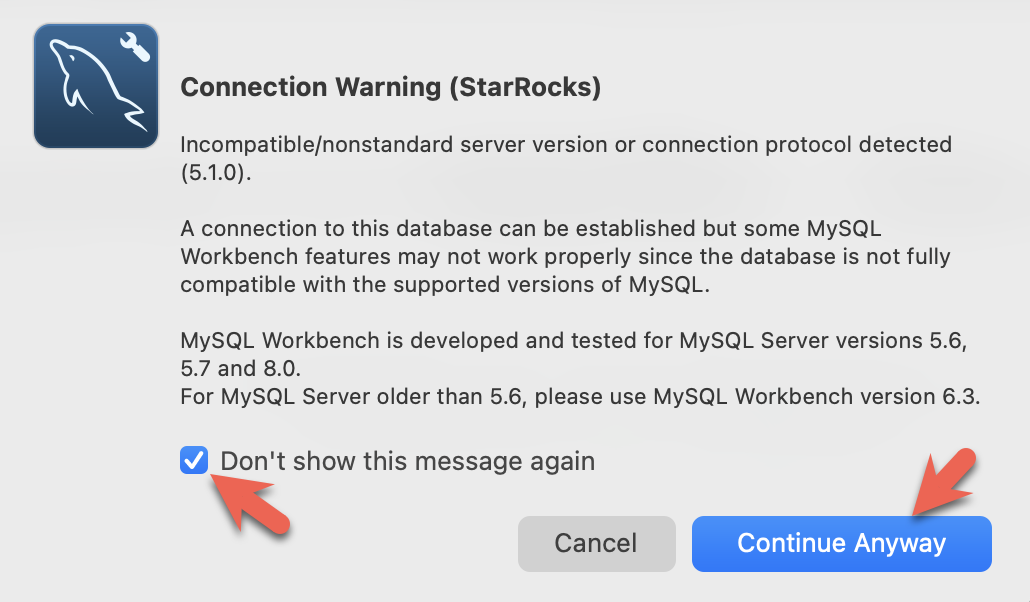
- Workbenchは特定のMySQLバージョンをチェックするため警告を表示します。警告を無視し、プロンプトが表示されたら、Workbenchが警告を表示しないように設定できます。
データをダウンロードする
これらの2つのデータセットをマシンにダウンロードします。Docker を実行しているホストマシンにダウンロードできます。コンテナ内にダウンロードする必要はありません。
ニューヨーク市のクラッシュデータ
curl -O https://raw.githubusercontent.com/StarRocks/demo/master/documentation-samples/quickstart/datasets/NYPD_Crash_Data.csv
気象データ
curl -O https://raw.githubusercontent.com/StarRocks/demo/master/documentation-samples/quickstart/datasets/72505394728.csv
SQL クライアントで StarRocks に接続する
mysql CLI 以外のクライアントを使用している場合は、今すぐ開いてください。
このコマンドは Docker コンテナ内で mysql コマンドを実行します:
docker exec -it quickstart \
mysql -P 9030 -h 127.0.0.1 -u root --prompt="StarRocks > "
テーブルを作成する
データベースの作成
StarRocks > プロンプトで次の2行を入力し、それぞれの後にエンターキーを押します。
CREATE DATABASE IF NOT EXISTS quickstart;
USE quickstart;
2つのテーブルを作成
Crashdata
クラッシュデータセットにはこれより多くのフィールドが含まれていますが、スキーマは天候が運転条件に与える影響に関する質問に答えるために役立つ可能性のあるフィールドのみを含むように縮小されています。
CREATE TABLE IF NOT EXISTS crashdata (
CRASH_DATE DATETIME,
BOROUGH STRING,
ZIP_CODE STRING,
LATITUDE INT,
LONGITUDE INT,
LOCATION STRING,
ON_STREET_NAME STRING,
CROSS_STREET_NAME STRING,
OFF_STREET_NAME STRING,
CONTRIBUTING_FACTOR_VEHICLE_1 STRING,
CONTRIBUTING_FACTOR_VEHICLE_2 STRING,
COLLISION_ID INT,
VEHICLE_TYPE_CODE_1 STRING,
VEHICLE_TYPE_CODE_2 STRING
);
Weatherdata
クラッシュデータと同様に、天候データセットにはさらに多くの列(合計125列)があり、質問に答えると予想されるもののみがデータベースに含まれています。
CREATE TABLE IF NOT EXISTS weatherdata (
DATE DATETIME,
NAME STRING,
HourlyDewPointTemperature STRING,
HourlyDryBulbTemperature STRING,
HourlyPrecipitation STRING,
HourlyPresentWeatherType STRING,
HourlyPressureChange STRING,
HourlyPressureTendency STRING,
HourlyRelativeHumidity STRING,
HourlySkyConditions STRING,
HourlyVisibility STRING,
HourlyWetBulbTemperature STRING,
HourlyWindDirection STRING,
HourlyWindGustSpeed STRING,
HourlyWindSpeed STRING
);
2つのデータセットをロードする
StarRocks にデータをロードする方法は多数あります。このチュートリアルでは、最も簡単な方法として curl と StarRocks Stream Load を使用します。
これらの curl コマンドはオペレーティングシステムのプロンプトで実行されるため、新しいシェルを開いてください。mysql クライアントではありません。コマンドはダウンロードしたデータセットを参照しているので、ファイルをダウンロードしたディレクトリから実行してください。
パスワードを求められます。MySQL の root ユーザーにパスワードを設定していない場合は、Enter キーを押してください。
curl コマンドは複雑に見えますが、チュートリアルの最後で詳細に説明��されています。今はコマンドを実行し、データを分析するためにいくつかの SQL を実行し、その後でデータロードの詳細を読むことをお勧めします。
ニューヨーク市の衝突データ - クラッシュ
curl --location-trusted -u root \
-T ./NYPD_Crash_Data.csv \
-H "label:crashdata-0" \
-H "column_separator:," \
-H "skip_header:1" \
-H "enclose:\"" \
-H "max_filter_ratio:1" \
-H "columns:tmp_CRASH_DATE, tmp_CRASH_TIME, CRASH_DATE=str_to_date(concat_ws(' ', tmp_CRASH_DATE, tmp_CRASH_TIME), '%m/%d/%Y %H:%i'),BOROUGH,ZIP_CODE,LATITUDE,LONGITUDE,LOCATION,ON_STREET_NAME,CROSS_STREET_NAME,OFF_STREET_NAME,NUMBER_OF_PERSONS_INJURED,NUMBER_OF_PERSONS_KILLED,NUMBER_OF_PEDESTRIANS_INJURED,NUMBER_OF_PEDESTRIANS_KILLED,NUMBER_OF_CYCLIST_INJURED,NUMBER_OF_CYCLIST_KILLED,NUMBER_OF_MOTORIST_INJURED,NUMBER_OF_MOTORIST_KILLED,CONTRIBUTING_FACTOR_VEHICLE_1,CONTRIBUTING_FACTOR_VEHICLE_2,CONTRIBUTING_FACTOR_VEHICLE_3,CONTRIBUTING_FACTOR_VEHICLE_4,CONTRIBUTING_FACTOR_VEHICLE_5,COLLISION_ID,VEHICLE_TYPE_CODE_1,VEHICLE_TYPE_CODE_2,VEHICLE_TYPE_CODE_3,VEHICLE_TYPE_CODE_4,VEHICLE_TYPE_CODE_5" \
-XPUT http://localhost:8030/api/quickstart/crashdata/_stream_load
上記のコマンドの出力です。最初のハイライトされたセクションは、期待される出力(OK と1行を除くすべての行が挿入されたこと)を示しています。1行は正しい列数を含んでいないためフィルタリングされました。
Enter host password for user 'root':
{
"TxnId": 2,
"Label": "crashdata-0",
"Status": "Success",
"Message": "OK",
"NumberTotalRows": 423726,
"NumberLoadedRows": 423725,
"NumberFilteredRows": 1,
"NumberUnselectedRows": 0,
"LoadBytes": 96227746,
"LoadTimeMs": 1013,
"BeginTxnTimeMs": 21,
"StreamLoadPlanTimeMs": 63,
"ReadDataTimeMs": 563,
"WriteDataTimeMs": 870,
"CommitAndPublishTimeMs": 57,
"ErrorURL": "http://127.0.0.1:8040/api/_load_error_log?file=error_log_da41dd88276a7bfc_739087c94262ae9f"
}%
エラーが発生した場合、出力にはエラーメッセージを確認するための URL が提供されます。ブラウザで開いて、何が起こったかを確認してください。詳細を展開してエラーメッセージを確認します:
ブラウザ�でエラーメッセージを読む
Error: Value count does not match column count. Expect 29, but got 32.
Column delimiter: 44,Row delimiter: 10.. Row: 09/06/2015,14:15,,,40.6722269,-74.0110059,"(40.6722269, -74.0110059)",,,"R/O 1 BEARD ST. ( IKEA'S
09/14/2015,5:30,BRONX,10473,40.814551,-73.8490955,"(40.814551, -73.8490955)",TORRY AVENUE ,NORTON AVENUE ,,0,0,0,0,0,0,0,0,Driver Inattention/Distraction,Unspecified,,,,3297457,PASSENGER VEHICLE,PASSENGER VEHICLE,,,
気象データ
クラッシュデータをロードしたのと同じ方法で、気象データセットをロードします。
curl --location-trusted -u root \
-T ./72505394728.csv \
-H "label:weather-0" \
-H "column_separator:," \
-H "skip_header:1" \
-H "enclose:\"" \
-H "max_filter_ratio:1" \
-H "columns: STATION, DATE, LATITUDE, LONGITUDE, ELEVATION, NAME, REPORT_TYPE, SOURCE, HourlyAltimeterSetting, HourlyDewPointTemperature, HourlyDryBulbTemperature, HourlyPrecipitation, HourlyPresentWeatherType, HourlyPressureChange, HourlyPressureTendency, HourlyRelativeHumidity, HourlySkyConditions, HourlySeaLevelPressure, HourlyStationPressure, HourlyVisibility, HourlyWetBulbTemperature, HourlyWindDirection, HourlyWindGustSpeed, HourlyWindSpeed, Sunrise, Sunset, DailyAverageDewPointTemperature, DailyAverageDryBulbTemperature, DailyAverageRelativeHumidity, DailyAverageSeaLevelPressure, DailyAverageStationPressure, DailyAverageWetBulbTemperature, DailyAverageWindSpeed, DailyCoolingDegreeDays, DailyDepartureFromNormalAverageTemperature, DailyHeatingDegreeDays, DailyMaximumDryBulbTemperature, DailyMinimumDryBulbTemperature, DailyPeakWindDirection, DailyPeakWindSpeed, DailyPrecipitation, DailySnowDepth, DailySnowfall, DailySustainedWindDirection, DailySustainedWindSpeed, DailyWeather, MonthlyAverageRH, MonthlyDaysWithGT001Precip, MonthlyDaysWithGT010Precip, MonthlyDaysWithGT32Temp, MonthlyDaysWithGT90Temp, MonthlyDaysWithLT0Temp, MonthlyDaysWithLT32Temp, MonthlyDepartureFromNormalAverageTemperature, MonthlyDepartureFromNormalCoolingDegreeDays, MonthlyDepartureFromNormalHeatingDegreeDays, MonthlyDepartureFromNormalMaximumTemperature, MonthlyDepartureFromNormalMinimumTemperature, MonthlyDepartureFromNormalPrecipitation, MonthlyDewpointTemperature, MonthlyGreatestPrecip, MonthlyGreatestPrecipDate, MonthlyGreatestSnowDepth, MonthlyGreatestSnowDepthDate, MonthlyGreatestSnowfall, MonthlyGreatestSnowfallDate, MonthlyMaxSeaLevelPressureValue, MonthlyMaxSeaLevelPressureValueDate, MonthlyMaxSeaLevelPressureValueTime, MonthlyMaximumTemperature, MonthlyMeanTemperature, MonthlyMinSeaLevelPressureValue, MonthlyMinSeaLevelPressureValueDate, MonthlyMinSeaLevelPressureValueTime, MonthlyMinimumTemperature, MonthlySeaLevelPressure, MonthlyStationPressure, MonthlyTotalLiquidPrecipitation, MonthlyTotalSnowfall, MonthlyWetBulb, AWND, CDSD, CLDD, DSNW, HDSD, HTDD, NormalsCoolingDegreeDay, NormalsHeatingDegreeDay, ShortDurationEndDate005, ShortDurationEndDate010, ShortDurationEndDate015, ShortDurationEndDate020, ShortDurationEndDate030, ShortDurationEndDate045, ShortDurationEndDate060, ShortDurationEndDate080, ShortDurationEndDate100, ShortDurationEndDate120, ShortDurationEndDate150, ShortDurationEndDate180, ShortDurationPrecipitationValue005, ShortDurationPrecipitationValue010, ShortDurationPrecipitationValue015, ShortDurationPrecipitationValue020, ShortDurationPrecipitationValue030, ShortDurationPrecipitationValue045, ShortDurationPrecipitationValue060, ShortDurationPrecipitationValue080, ShortDurationPrecipitationValue100, ShortDurationPrecipitationValue120, ShortDurationPrecipitationValue150, ShortDurationPrecipitationValue180, REM, BackupDirection, BackupDistance, BackupDistanceUnit, BackupElements, BackupElevation, BackupEquipment, BackupLatitude, BackupLongitude, BackupName, WindEquipmentChangeDate" \
-XPUT http://localhost:8030/api/quickstart/weatherdata/_stream_load
質問に答える
これらのクエリは、SQL クライアントで実行できます。すべてのクエリは quickstart データベースを使用します。
USE quickstart;
NYC での時間ごとの事故件数は?
SELECT COUNT(*),
date_trunc("hour", crashdata.CRASH_DATE) AS Time
FROM crashdata
GROUP BY Time
ORDER BY Time ASC
LIMIT 200;
以下は出力の一部です。1月6日と7日を詳しく見ていることに注意してください。これは祝日ではない週の月曜日と火曜日です。元旦を見ても、通常のラッシュアワーの朝を示しているとは言えないでしょう。
| 14 | 2014-01-06 06:00:00 |
| 16 | 2014-01-06 07:00:00 |
| 43 | 2014-01-06 08:00:00 |
| 44 | 2014-01-06 09:00:00 |
| 21 | 2014-01-06 10:00:00 |
| 28 | 2014-01-06 11:00:00 |
| 34 | 2014-01-06 12:00:00 |
| 31 | 2014-01-06 13:00:00 |
| 35 | 2014-01-06 14:00:00 |
| 36 | 2014-01-06 15:00:00 |
| 33 | 2014-01-06 16:00:00 |
| 40 | 2014-01-06 17:00:00 |
| 35 | 2014-01-06 18:00:00 |
| 23 | 2014-01-06 19:00:00 |
| 16 | 2014-01-06 20:00:00 |
| 12 | 2014-01-06 21:00:00 |
| 17 | 2014-01-06 22:00:00 |
| 14 | 2014-01-06 23:00:00 |
| 10 | 2014-01-07 00:00:00 |
| 4 | 2014-01-07 01:00:00 |
| 1 | 2014-01-07 02:00:00 |
| 3 | 2014-01-07 03:00:00 |
| 2 | 2014-01-07 04:00:00 |
| 6 | 2014-01-07 06:00:00 |
| 16 | 2014-01-07 07:00:00 |
| 41 | 2014-01-07 08:00:00 |
| 37 | 2014-01-07 09:00:00 |
| 33 | 2014-01-07 10:00:00 |
月曜日や火曜日の朝のラッシュアワーでは約40件の事故が発生しており、17:00 時にも同様の件数が見られます。
NYC の平均気温は?
SELECT avg(HourlyDryBulbTemperature),
date_trunc("hour", weatherdata.DATE) AS Time
FROM weatherdata
GROUP BY Time
ORDER BY Time ASC
LIMIT 100;
出力:
これは2014年のデータであり、最近のNYCはこれほど寒くありません。
+-------------------------------+---------------------+
| avg(HourlyDryBulbTemperature) | Time |
+-------------------------------+---------------------+
| 25 | 2014-01-01 00:00:00 |
| 25 | 2014-01-01 01:00:00 |
| 24 | 2014-01-01 02:00:00 |
| 24 | 2014-01-01 03:00:00 |
| 24 | 2014-01-01 04:00:00 |
| 24 | 2014-01-01 05:00:00 |
| 25 | 2014-01-01 06:00:00 |
| 26 | 2014-01-01 07:00:00 |
視界が悪いときにNYCで運転するのは安全ですか?
視界が悪いとき(0から1.0マイルの間)の事故件数を見てみましょう。この質問に答えるために、2つのテーブルを DATETIME 列で ジョイン します。
SELECT COUNT(DISTINCT c.COLLISION_ID) AS Crashes,
truncate(avg(w.HourlyDryBulbTemperature), 1) AS Temp_F,
truncate(avg(w.HourlyVisibility), 2) AS Visibility,
max(w.HourlyPrecipitation) AS Precipitation,
date_format((date_trunc("hour", c.CRASH_DATE)), '%d %b %Y %H:%i') AS Hour
FROM crashdata c
LEFT JOIN weatherdata w
ON date_trunc("hour", c.CRASH_DATE)=date_trunc("hour", w.DATE)
WHERE w.HourlyVisibility BETWEEN 0.0 AND 1.0
GROUP BY Hour
ORDER BY Crashes DESC
LIMIT 100;
視界が悪いときの1時間あたりの事故件数の最高は129件です。考慮すべき点はいくつかあります:
- 2014年2月3日は月曜日
- 午前8時はラッシュアワー
- 雨が降っていた(その時間の降水量は0.12インチ)
- 気温は32度F(水の氷点)
- 視界は0.25マイルで、NYCの通常は10マイル
+---------+--------+------------+---------------+-------------------+
| Crashes | Temp_F | Visibility | Precipitation | Hour |
+---------+--------+------------+---------------+-------------------+
| 129 | 32 | 0.25 | 0.12 | 03 Feb 2014 08:00 |
| 114 | 32 | 0.25 | 0.12 | 03 Feb 2014 09:00 |
| 104 | 23 | 0.33 | 0.03 | 09 Jan 2015 08:00 |
| 96 | 26.3 | 0.33 | 0.07 | 01 Mar 2015 14:00 |
| 95 | 26 | 0.37 | 0.12 | 01 Mar 2015 15:00 |
| 93 | 35 | 0.75 | 0.09 | 18 Jan 2015 09:00 |
| 92 | 31 | 0.25 | 0.12 | 03 Feb 2014 10:00 |
| 87 | 26.8 | 0.5 | 0.09 | 01 Mar 2015 16:00 |
| 85 | 55 | 0.75 | 0.20 | 23 Dec 2015 17:00 |
| 85 | 20 | 0.62 | 0.01 | 06 Jan 2015 11:00 |
| 83 | 19.6 | 0.41 | 0.04 | 05 Mar 2015 13:00 |
| 80 | 20 | 0.37 | 0.02 | 06 Jan 2015 10:00 |
| 76 | 26.5 | 0.25 | 0.06 | 05 Mar 2015 09:00 |
| 71 | 26 | 0.25 | 0.09 | 05 Mar 2015 10:00 |
| 71 | 24.2 | 0.25 | 0.04 | 05 Mar 2015 11:00 |
氷点下の条件での運転はどうでしょうか?
水蒸気は40度Fで氷に昇華することがあります。このクエリは0から40度Fの間の気温を調べます。
SELECT COUNT(DISTINCT c.COLLISION_ID) AS Crashes,
truncate(avg(w.HourlyDryBulbTemperature), 1) AS Temp_F,
truncate(avg(w.HourlyVisibility), 2) AS Visibility,
max(w.HourlyPrecipitation) AS Precipitation,
date_format((date_trunc("hour", c.CRASH_DATE)), '%d %b %Y %H:%i') AS Hour
FROM crashdata c
LEFT JOIN weatherdata w
ON date_trunc("hour", c.CRASH_DATE)=date_trunc("hour", w.DATE)
WHERE w.HourlyDryBulbTemperature BETWEEN 0.0 AND 40.5
GROUP BY Hour
ORDER BY Crashes DESC
LIMIT 100;
氷点下の気温に関する結果は少し驚きました。寒い1月の日曜日の朝に市内であまり交通がないと思っていました。weather.com をざっと見たところ、その日は多くの事故が発生した大き��な嵐があったことがわかりました。データにもその様子が見られます。
+---------+--------+------------+---------------+-------------------+
| Crashes | Temp_F | Visibility | Precipitation | Hour |
+---------+--------+------------+---------------+-------------------+
| 192 | 34 | 1.5 | 0.09 | 18 Jan 2015 08:00 |
| 170 | 21 | NULL | | 21 Jan 2014 10:00 |
| 145 | 19 | NULL | | 21 Jan 2014 11:00 |
| 138 | 33.5 | 5 | 0.02 | 18 Jan 2015 07:00 |
| 137 | 21 | NULL | | 21 Jan 2014 09:00 |
| 129 | 32 | 0.25 | 0.12 | 03 Feb 2014 08:00 |
| 114 | 32 | 0.25 | 0.12 | 03 Feb 2014 09:00 |
| 104 | 23 | 0.7 | 0.04 | 09 Jan 2015 08:00 |
| 98 | 16 | 8 | 0.00 | 06 Mar 2015 08:00 |
| 96 | 26.3 | 0.33 | 0.07 | 01 Mar 2015 14:00 |
安全運転を心がけましょう!
まとめ
このチュートリアルであなたは:
- Docker で StarRocks をデプロイしました
- ニューヨーク市が提供するクラッシュデータと NOAA が提供する気象データをロードしました
- SQL JOIN を使用してデータを分析し、視界が悪い状態や凍結した道路での運転が悪い考えであることを発見しました
学ぶべきことはまだあります。Stream Load 中に行われたデータ変換については意図的に詳しく説明していません。curl コマンドの詳細は以下のノートに記載されています。
curl コマンドのノート
StarRocks Stream Load と curl は多くの引数を取ります。このチュートリアルで使用されるものだけがここで説明されており、残りは詳細情報セクションでリンクされます。
--location-trusted
これは、curl がリダイレクトされた URL に資格情報を渡すように設定します。
-u root
StarRocks にログインするために使用されるユーザー名です。
-T filename
T は転送を意味し、転送するファイル名です。
label:name-num
この Stream Load ジョブに関連付けるラベルです。ラベルは一意である必要があるため、ジョブを複数回実行する場合は、番号を追加してインクリメントし続けることができます。
column_separator:,
ファイルが単一の , を使用している場合は、上記のように設定します。異なる区切り文字を使用する場合は、その区切り文字をここに設定します。一般的な選択肢は \t、,、| です。
skip_header:1
一部の CSV ファイルには、すべての列名が記載された単一のヘッダー行があり、データ型を含む2行目を追加するものもあります。ヘッダー行が1行または2行ある場合は skip_header を 1 または 2 に設定し、ない場合は 0 に設定します。
enclose:\"
埋め込みカンマを含む文字列をダブルクォートで囲むことが一般的です。このチュートリアルで使用されるサンプルデータセットにはカンマを含む地理的位置があるため、enclose 設定は \" に設定されています。" を \ でエスケープすることを忘れないでください。
max_filter_ratio:1
これはデータ内のいくつかのエラーを許可します。理想的には 0 に設定し、エラーがある場合はジョブが失敗するようにします。デバッグ中にすべての行が失敗することを許可するために 1 に設定されています。
columns:
CSV ファイルの列を StarRocks テーブルの列にマッピングします。CSV ファイルにはテーブルの列よりも多くの列があることに気付くでしょう。テーブルに含まれていない列はスキップされます。
また、クラッシュデータセットの columns: 行にデータの変換が含まれていることにも気付くでしょう。CSV ファイルには標準に準拠していない日付や時刻が含まれていることが非常に一般的です。これは、クラッシュの日時を DATETIME 型に変換するためのロジックです。
The columns line
これは1つのデータレコードの始まりです。日付は MM/DD/YYYY 形式で、時刻は HH:MI です。DATETIME は通常 YYYY-MM-DD HH:MI:SS であるため、このデータを変換する必要があります。
08/05/2014,9:10,BRONX,10469,40.8733019,-73.8536375,"(40.8733019, -73.8536375)",
これは columns: パラメータの始まりです。
-H "columns:tmp_CRASH_DATE, tmp_CRASH_TIME, CRASH_DATE=str_to_date(concat_ws(' ', tmp_CRASH_DATE, tmp_CRASH_TIME), '%m/%d/%Y %H:%i')
これは StarRocks に次のことを指示します:
- CSV ファイルの最初の列の内容を
tmp_CRASH_DATEに割り当てる - CSV ファイルの2番目の列の内容を
tmp_CRASH_TIMEに割り当てる concat_ws()はtmp_CRASH_DATEとtmp_CRASH_TIMEをスペースで連結するstr_to_date()は連結された文字列から DATETIME を作成する- 結果の DATETIME を
CRASH_DATE列に格納する
詳細情報
Motor Vehicle Collisions - Crashes データセットは、ニューヨーク市によって提供され、利用規約 および プライバシーポリシー に従います。
Local Climatological Data(LCD) は NOAA によって提供され、免責事項 および プライバシーポリシー に従います。
