Kafka routine load StarRocks using shared-data storage
About Routine Load
Routine Load は、Apache Kafka またはこのラボでは Redpanda を使用して、データを継続的に StarRocks にストリームする方法です。データは Kafka トピックにストリームされ、Routine Load ジョブがそのデータを StarRocks に取り込みます。Routine Load の詳細はラボの最後に提供されています。
About shared-data
ストレージとコンピュートを分離するシステムでは、データは Amazon S3、Google Cloud Storage、Azure Blob Storage、MinIO などの S3 互換ストレージといった低コストで信頼性の高いリモートストレージシステムに保存されます。ホットデータはローカルにキャッシュされ、キャッシュがヒットすると、クエリパフォーマンスはストレージとコンピュートが結合されたアーキテクチャと同等になります。コンピュートノード (CN) は数秒でオンデマンドで追加または削除できます。このアーキテクチャはストレージコストを削減し、より良いリソース分離を保証し、弾力性とスケーラビリティを提供します。
このチュートリアルでは以下をカバーします:
- Docker Compose を使用して StarRocks、Redpanda、MinIO を実行する
- MinIO を StarRocks のストレージレイヤーとして使用する
- StarRocks を共有データ用に設定する
- Redpanda からデータを消費する Routine Load ジョブを追加する
使用されるデータは合成データです。
このドキュメントには多くの情報が含まれており、最初にステップバイステップの内容が提示され、技術的な詳細は最後に示されています。これは以下の目的を順に果たすためです:
- Routine Load を設定する。
- 読者が共有データデプロイメントでデータをロードし、そのデータを分析できるようにする。
- 共有データデプロイメントの設定詳細を提供する。
Prerequisites
Docker
- Docker
- Docker に割り当てられた 4 GB の RAM
- Docker に割り当てられた 10 GB の空きディスクスペース
SQL client
Docker 環境で提供される SQL クライアントを使用するか、システム上のクライアントを使用できます。多くの MySQL 互換クライアントが動作し、このガイドでは DBeaver と MySQL Workbench の設定をカバーしています。
curl
curl は Compose ファイルとデータを生成するスクリプトをダウンロードするために使用されます。OS のプロンプトで curl または curl.exe を実行してインストールされているか確認してください。curl がインストールされていない場合は、こちらから curl を取得してください.
Python
Python 3 と Apache Kafka 用の Python クライアント kafka-python が必要です。
Terminology
FE
フロントエンドノードは、メタデータ管理、クライアント接続管理、クエリプランニング、クエリスケジューリングを担当します。各 FE はメモリ内にメタデータの完全��なコピーを保存および維持し、FEs 間での無差別なサービスを保証します。
CN
コンピュートノードは、共有データデプロイメントにおけるクエリプランの実行を担当します。
BE
バックエンドノードは、共有なしデプロイメントにおけるデータストレージとクエリプランの実行の両方を担当します。
このガイドでは BEs を使用しませんが、BEs と CNs の違いを理解するためにこの情報を含めています。
Launch StarRocks
Object Storage を使用して shared-data で StarRocks を実行するには、以下が必要です:
- フロントエンドエンジン (FE)
- コンピュートノード (CN)
- Object Storage
このガイドでは、S3 互換の Object Storage プロバイダーである MinIO を使用します。MinIO は GNU Affero General Public License の下で提供されています。
Download the lab files
docker-compose.yml
mkdir routineload
cd routineload
curl -O https://raw.githubusercontent.com/StarRocks/demo/master/documentation-samples/routine-load-shared-data/docker-compose.yml
gen.py
gen.py は、Apache Kafka 用の Python クライアントを使用してデータを Kafka トピックに公開(生成)するスクリプトです。このスクリプトは Redpanda コンテナのアドレスとポートで書かれています。
curl -O https://raw.githubusercontent.com/StarRocks/demo/master/documentation-samples/routine-load-shared-data/gen.py
Start StarRocks, MinIO, and Redpanda
docker compose up --detach --wait --wait-timeout 120
サービスの進行状況を確認します。コンテナが正常になるまで 30 秒以上かかる場合があります。routineload-minio_mc-1 コンテナは健康状態のインジケータを表示せず、StarRocks が使用するアクセスキーで MinIO を設定し終えると終了します。routineload-minio_mc-1 が 0 コードで終了し、他のサービスが Healthy になるのを待ちます。
サービスが正常になるまで docker compose ps を実行します:
docker compose ps
WARN[0000] /Users/droscign/routineload/docker-compose.yml: `version` is obsolete
[+] Running 6/7
✔ Network routineload_default Crea... 0.0s
✔ Container minio Healthy 5.6s
✔ Container redpanda Healthy 3.6s
✔ Container redpanda-console Healt... 1.1s
⠧ Container routineload-minio_mc-1 Waiting 23.1s
✔ Container starrocks-fe Healthy 11.1s
✔ Container starrocks-cn Healthy 23.0s
container routineload-minio_mc-1 exited (0)
Examine MinIO credentials
StarRocks で Object Storage として MinIO を使用するには、StarRocks に MinIO のアクセスキーが必要です。アクセスキーは Docker サービスの起動時に生成されました。StarRocks が MinIO に接続する方法をよりよく理解するために、キーが存在することを確認してください。
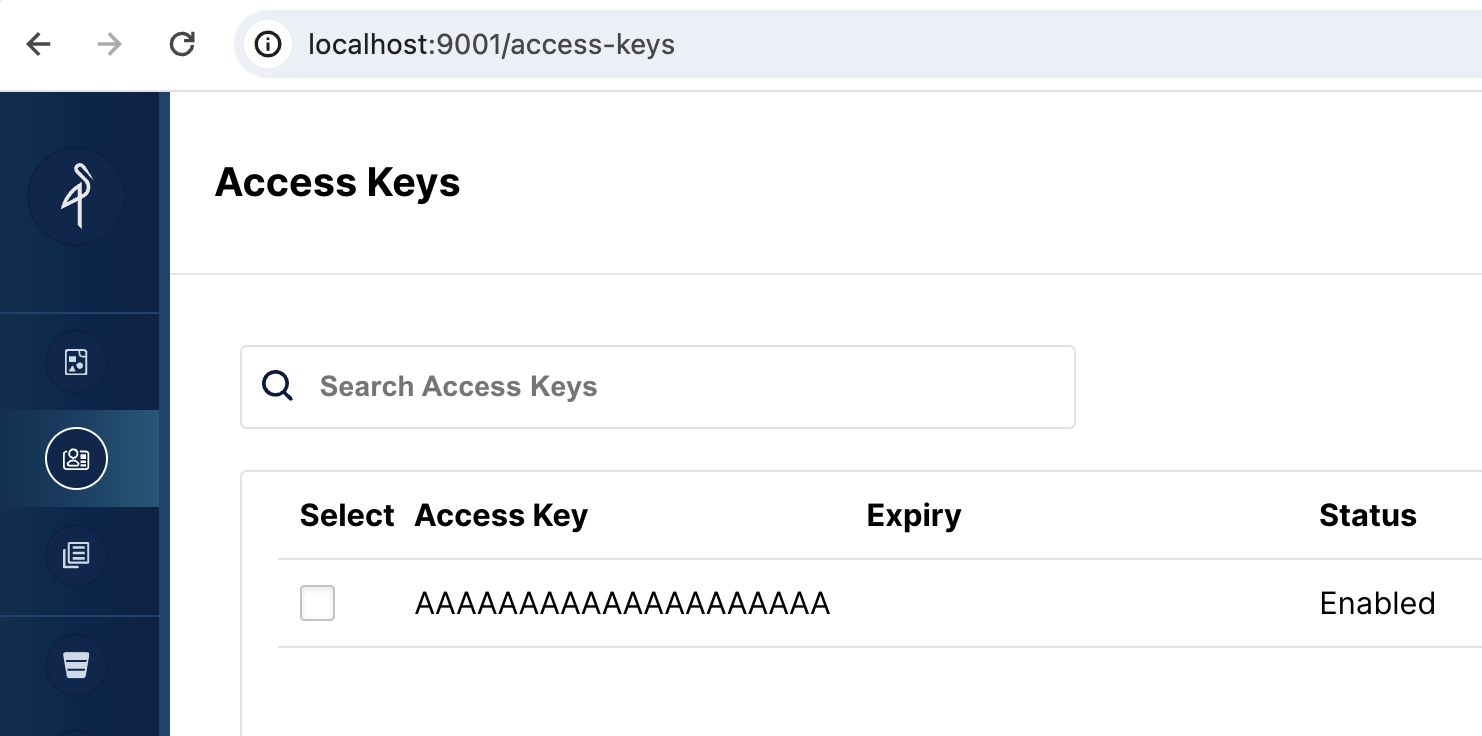
Open the MinIO web UI
http://localhost:9001/access-keys にアクセスします。ユーザー名とパスワードは Docker compose ファイルに指定されており、miniouser と miniopassword です。1 つのアクセスキーがあることが確認できます。キーは AAAAAAAAAAAAAAAAAAAA で、MinIO コンソールではシークレットは表示されませんが、Docker compose ファイルには BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB と記載されています。
Create a bucket for your data
StarRocks でストレージボリュームを作成する際に、データの LOCATION を指定します:
LOCATIONS = ("s3://my-starrocks-bucket/")
http://localhost:9001/buckets を開き、ストレージボリューム用のバケットを追加します。バケット名は my-starrocks-bucket にします。3 つのリストされたオプションのデフォルトを受け入れます。
SQL Clients
これらの3つのクライアントはこのチュートリアルでテストされていますが、1つだけ使用すれば大丈夫です。
- mysql CLI: Docker 環境またはあなたのマシンから実行できます。
- DBeaver は、コミュニティ版と Pro 版があります。
- MySQL Workbench
クライアントの設定
- mysql CLI
- DBeaver
- MySQL Workbench
mysql CLI を使用する最も簡単な方法は、StarRocks コンテナ starrocks-fe から実行することです。
docker compose exec starrocks-fe \
mysql -P 9030 -h 127.0.0.1 -u root --prompt="StarRocks > "
すべての docker compose コマンドは、docker-compose.yml ファイルを含むディレクトリから実行する必要があります。
mysql CLI をインストールしたい場合は、以下の mysql client install を展開してください。
mysql client install
- macOS: Homebrew を使用していて MySQL Server が不要な場合、
brew install mysql-client@8.0を実行して CLI をインストールします。 - Linux:
mysqlクライアントをリポジトリシステムで確認します。例えば、yum install mariadb。 - Microsoft Windows: MySQL Community Server をインストールして提供されたクライアントを実行するか、WSL から
mysqlを実行します。
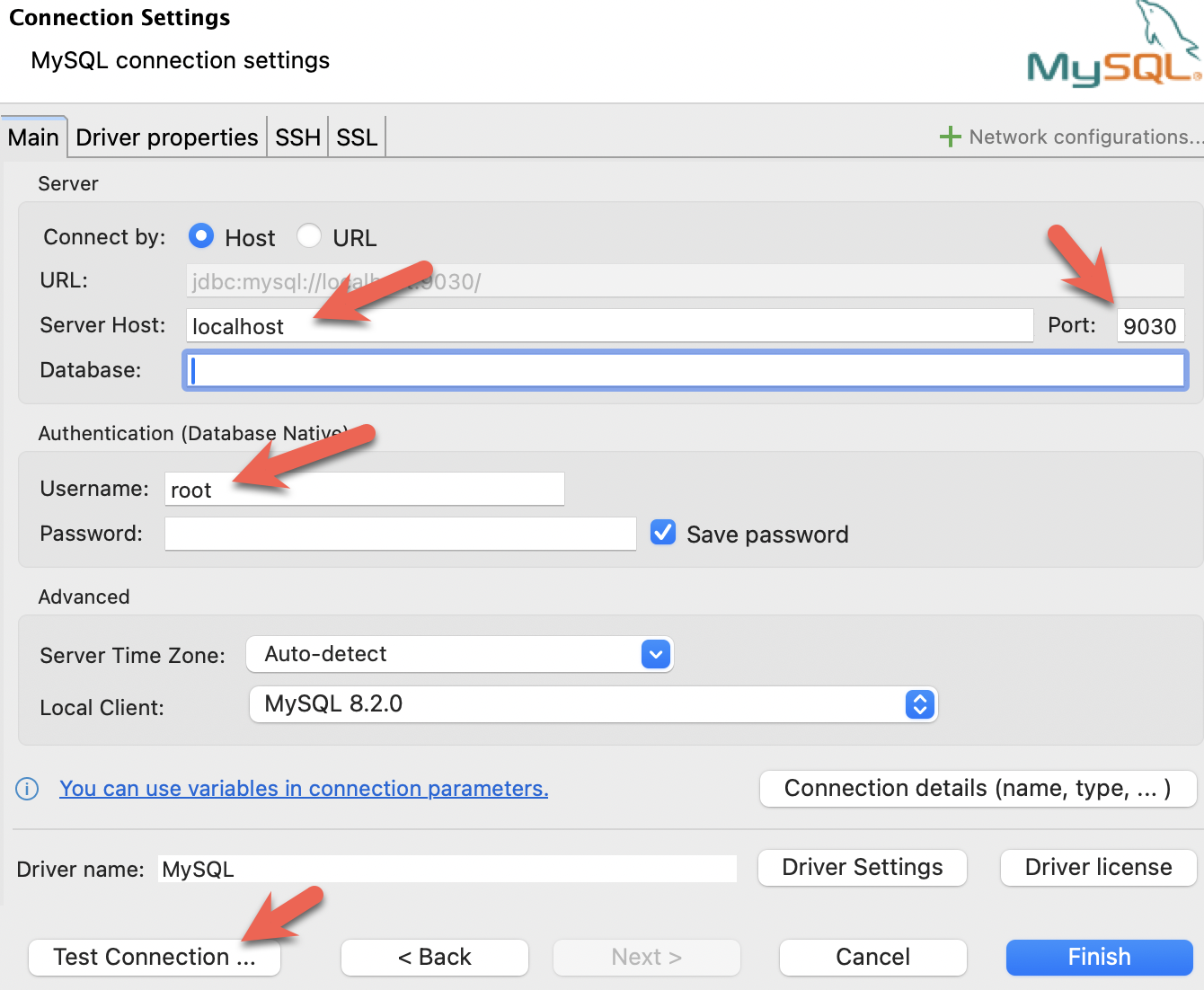
- DBeaver をインストールし、接続を追加します。

- ポート、IP、ユーザー名を設定します。接続をテストし、テストが成功したら Finish をクリックします。
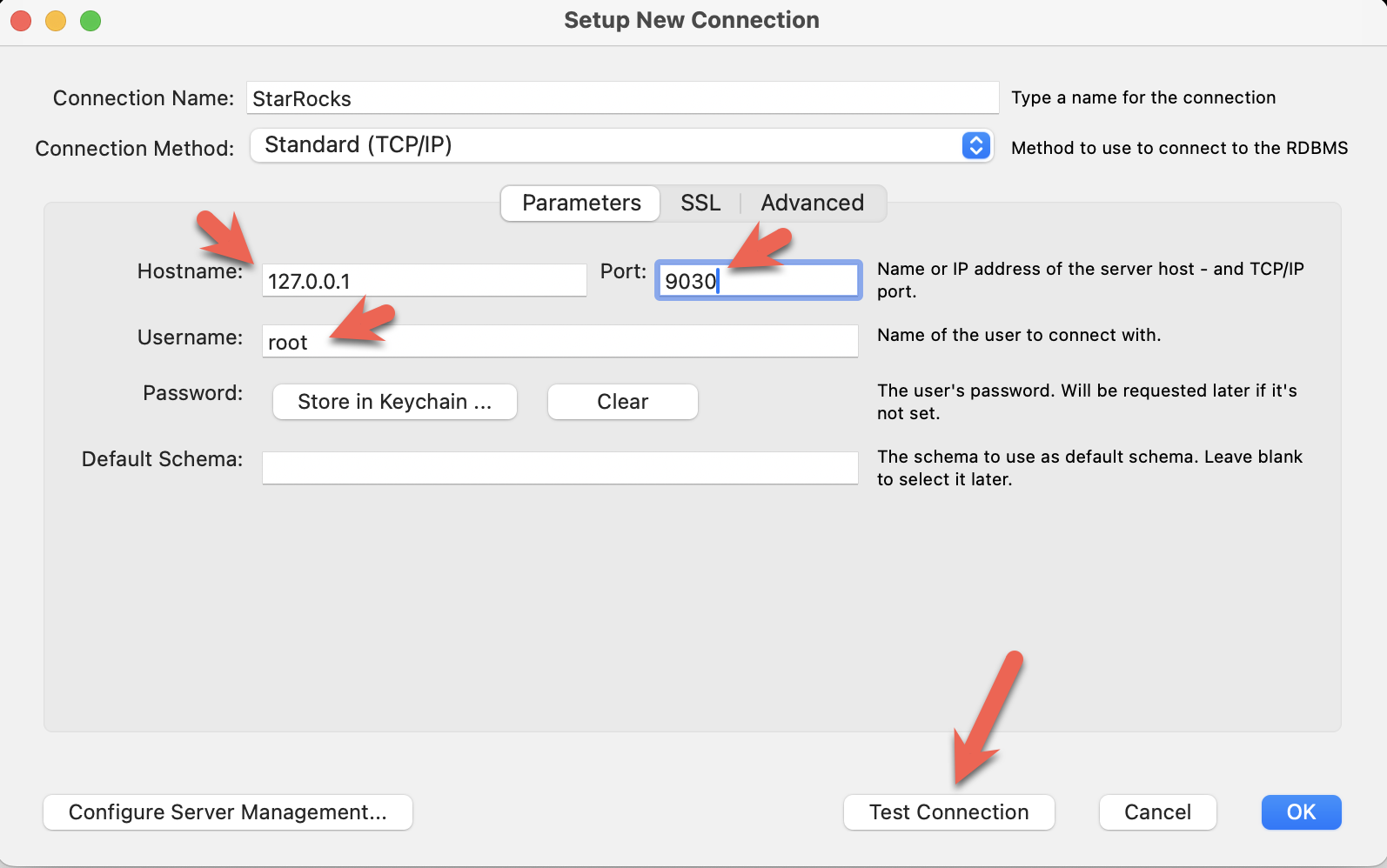
- MySQL Workbench をインストールし、接続を追加します。
- ポート、IP、ユーザー名を設定し、接続をテストします。
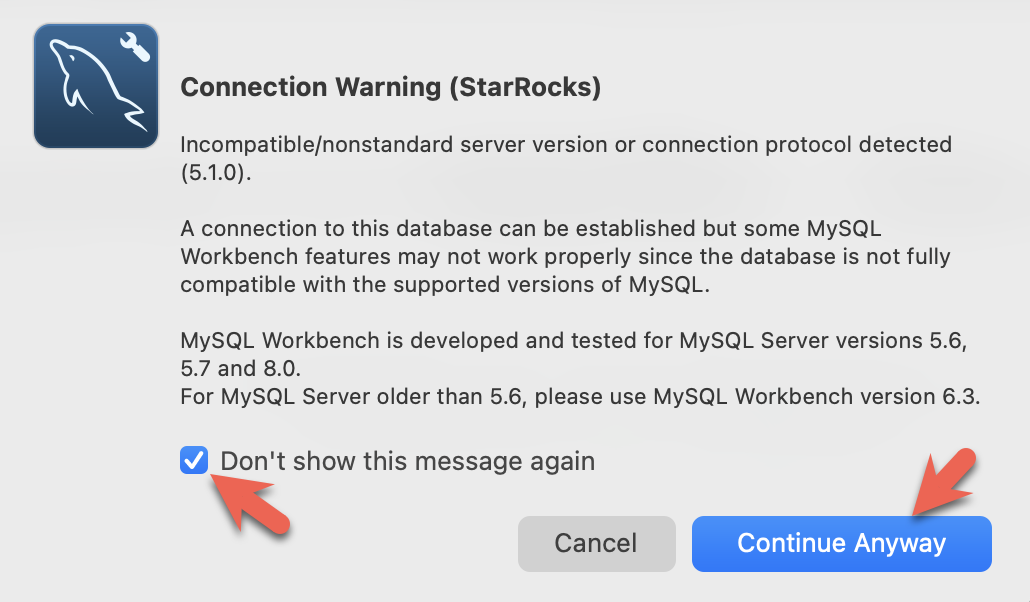
- Workbench は特定の MySQL バージョンをチェックするため、警告が表示されます。警告を無視し、プロンプトが表示されたら、Workbench が警告を表示しないように設定できます。
StarRocks configuration for shared-data
この時点で StarRocks が実行されており、MinIO も実行されています。MinIO アクセスキーは StarRocks と MinIO を接続するために使用されます。
これは StarRocks デプロイメントが共有データを使用することを指定する FE 設定の一部です。これは Docker Compose がデプロイメントを作成したときにファイル fe.conf に追加されました。
# enable the shared data run mode
run_mode = shared_data
cloud_native_storage_type = S3
これらの設定を確認するには、quickstart ディレクトリからこのコマンドを実行し、ファイルの最後を確認してください:
docker compose exec starrocks-fe \
cat /opt/starrocks/fe/conf/fe.conf
:::
Connect to StarRocks with a SQL client
docker-compose.yml ファイルを含むディレクトリからこのコマンドを実行します。
mysql CLI 以外のクライアントを使用している場合は、今すぐ開いてください。
docker compose exec starrocks-fe \
mysql -P9030 -h127.0.0.1 -uroot --prompt="StarRocks > "
Examine the storage volumes
SHOW STORAGE VOLUMES;
ストレージボリュームは存在しないはずです。次に作成します。
Empty set (0.04 sec)
Create a shared-data storage volume
以前に MinIO に my-starrocks-volume という名前のバケットを作成し、MinIO に AAAAAAAAAAAAAAAAAAAA というアクセスキーがあることを確認しました。次の SQL は、アクセスキーとシークレットを使用して MionIO バケットにストレージボリュームを作成します。
CREATE STORAGE VOLUME s3_volume
TYPE = S3
LOCATIONS = ("s3://my-starrocks-bucket/")
PROPERTIES
(
"enabled" = "true",
"aws.s3.endpoint" = "minio:9000",
"aws.s3.access_key" = "AAAAAAAAAAAAAAAAAAAA",
"aws.s3.secret_key" = "BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB",
"aws.s3.use_instance_profile" = "false",
"aws.s3.use_aws_sdk_default_behavior" = "false"
);
今度はストレージボリュームがリストされているはずです。以前は空のセットでした:
SHOW STORAGE VOLUMES;
+----------------+
| Storage Volume |
+----------------+
| s3_volume |
+----------------+
1 row in set (0.02 sec)
ストレージボリュームの詳細を表示し、これがまだデフォルトボリュームではないこと、およびバケットを使用するように設定されていることを確認します:
DESC STORAGE VOLUME s3_volume\G
このドキュメントの一部の SQL および StarRocks ドキュメントの多くの他のドキュメントは、セミコロンの代わりに \G で終わります。\G は mysql CLI にクエリ結果を縦に表示させます。
多くの SQL クライアントは縦のフォーマット出力を解釈しないため、\G を ; に置き換える必要があります。
*************************** 1. row ***************************
Name: s3_volume
Type: S3
IsDefault: false
Location: s3://my-starrocks-bucket/
Params: {"aws.s3.access_key":"******","aws.s3.secret_key":"******","aws.s3.endpoint":"minio:9000","aws.s3.region":"us-east-1","aws.s3.use_instance_profile":"false","aws.s3.use_web_identity_token_file":"false","aws.s3.use_aws_sdk_default_behavior":"false"}
Enabled: true
Comment:
1 row in set (0.02 sec)
Set the default storage volume
SET s3_volume AS DEFAULT STORAGE VOLUME;
DESC STORAGE VOLUME s3_volume\G
*************************** 1. row ***************************
Name: s3_volume
Type: S3
IsDefault: true
Location: s3://my-starrocks-bucket/
Params: {"aws.s3.access_key":"******","aws.s3.secret_key":"******","aws.s3.endpoint":"minio:9000","aws.s3.region":"us-east-1","aws.s3.use_instance_profile":"false","aws.s3.use_web_identity_token_file":"false","aws.s3.use_aws_sdk_default_behavior":"false"}
Enabled: true
Comment:
1 row in set (0.02 sec)
Create a table
これらの SQL コマンドは、SQL クライアントで実行されます。
CREATE DATABASE IF NOT EXISTS quickstart;
データベース quickstart がストレージボリューム s3_volume を使用していることを確認します:
SHOW CREATE DATABASE quickstart \G
*************************** 1. row ***************************
Database: quickstart
Create Database: CREATE DATABASE `quickstart`
PROPERTIES ("storage_volume" = "s3_volume")
USE quickstart;
CREATE TABLE site_clicks (
`uid` bigint NOT NULL COMMENT "uid",
`site` string NOT NULL COMMENT "site url",
`vtime` bigint NOT NULL COMMENT "vtime"
)
DISTRIBUTED BY HASH(`uid`)
PROPERTIES("replication_num"="1");
Open the Redpanda Console
まだトピックはありませんが、次のステップでトピックが作成されます。
http://localhost:8080/overview
Publish data to a Redpanda topic
routineload/ フォルダ内のコマンドシェルからこのコマンドを実行してデータを生成します:
python gen.py 5
システムによっては、コマンドで python の代わりに python3 を使用する必要があるかもしれません。
kafka-python が不足している場合は、次を試してください:
pip install kafka-python
または
pip3 install kafka-python
b'{ "uid": 6926, "site": "https://docs.starrocks.io/", "vtime": 1718034793 } '
b'{ "uid": 3303, "site": "https://www.starrocks.io/product/community", "vtime": 1718034793 } '
b'{ "uid": 227, "site": "https://docs.starrocks.io/", "vtime": 1718034243 } '
b'{ "uid": 7273, "site": "https://docs.starrocks.io/", "vtime": 1718034794 } '
b'{ "uid": 4666, "site": "https://www.starrocks.io/", "vtime": 1718034794 } '
Verify in the Redpanda Console
Redpanda コンソールで http://localhost:8080/topics に移動すると、test2 という名前のトピックが 1 つ表示されます。そのトピックを選択し、Messages タブを選択すると、gen.py の出力に一致する 5 つのメッセージが表示されます。
Consume the messages
StarRocks では、Routine Load ジョブを作成して以下を行います:
- Redpanda トピック
test2からメッセージを消費する - そのメッセージをテーブル
site_clicksにロードする
StarRocks は MinIO をストレージとして使用するように構成されているため、site_clicks テーブルに挿入されたデータは MinIO に保存されます。
Create a Routine Load job
SQL クライアントでこのコマンドを実行して Routine Load ジョブを作成します。このコマンドはラボの最後で詳しく説明されます。
CREATE ROUTINE LOAD quickstart.clicks ON site_clicks
PROPERTIES
(
"format" = "JSON",
"jsonpaths" ="[\"$.uid\",\"$.site\",\"$.vtime\"]"
)
FROM KAFKA
(
"kafka_broker_list" = "redpanda:29092",
"kafka_topic" = "test2",
"kafka_partitions" = "0",
"kafka_offsets" = "OFFSET_BEGINNING"
);
Verify the Routine Load job
SHOW ROUTINE LOAD\G
3 つのハイライトされた行を確認します:
- 状態は
RUNNINGであるべきです - トピックは
test2で、ブローカーはredpanda:2092であるべきです - 統計は、
SHOW ROUTINE LOADコマンドを実行したタイミングによって、0 または 5 のロードされた行を示すべきです。0 のロードされた行がある場合は、再度実行してください。
*************************** 1. row ***************************
Id: 10078
Name: clicks
CreateTime: 2024-06-12 15:51:12
PauseTime: NULL
EndTime: NULL
DbName: quickstart
TableName: site_clicks
State: RUNNING
DataSourceType: KAFKA
CurrentTaskNum: 1
JobProperties: {"partitions":"*","partial_update":"false","columnToColumnExpr":"*","maxBatchIntervalS":"10","partial_update_mode":"null","whereExpr":"*","dataFormat":"json","timezone":"Etc/UTC","format":"json","log_rejected_record_num":"0","taskTimeoutSecond":"60","json_root":"","maxFilterRatio":"1.0","strict_mode":"false","jsonpaths":"[\"$.uid\",\"$.site\",\"$.vtime\"]","taskConsumeSecond":"15","desireTaskConcurrentNum":"5","maxErrorNum":"0","strip_outer_array":"false","currentTaskConcurrentNum":"1","maxBatchRows":"200000"}
DataSourceProperties: {"topic":"test2","currentKafkaPartitions":"0","brokerList":"redpanda:29092"}
CustomProperties: {"group.id":"clicks_ea38a713-5a0f-4abe-9b11-ff4a241ccbbd"}
Statistic: {"receivedBytes":0,"errorRows":0,"committedTaskNum":0,"loadedRows":0,"loadRowsRate":0,"abortedTaskNum":0,"totalRows":0,"unselectedRows":0,"receivedBytesRate":0,"taskExecuteTimeMs":1}
Progress: {"0":"OFFSET_ZERO"}
TimestampProgress: {}
ReasonOfStateChanged:
ErrorLogUrls:
TrackingSQL:
OtherMsg:
LatestSourcePosition: {}
1 row in set (0.00 sec)
SHOW ROUTINE LOAD\G
*************************** 1. row ***************************
Id: 10076
Name: clicks
CreateTime: 2024-06-12 18:40:53
PauseTime: NULL
EndTime: NULL
DbName: quickstart
TableName: site_clicks
State: RUNNING
DataSourceType: KAFKA
CurrentTaskNum: 1
JobProperties: {"partitions":"*","partial_update":"false","columnToColumnExpr":"*","maxBatchIntervalS":"10","partial_update_mode":"null","whereExpr":"*","dataFormat":"json","timezone":"Etc/UTC","format":"json","log_rejected_record_num":"0","taskTimeoutSecond":"60","json_root":"","maxFilterRatio":"1.0","strict_mode":"false","jsonpaths":"[\"$.uid\",\"$.site\",\"$.vtime\"]","taskConsumeSecond":"15","desireTaskConcurrentNum":"5","maxErrorNum":"0","strip_outer_array":"false","currentTaskConcurrentNum":"1","maxBatchRows":"200000"}
DataSourceProperties: {"topic":"test2","currentKafkaPartitions":"0","brokerList":"redpanda:29092"}
CustomProperties: {"group.id":"clicks_a9426fee-45bb-403a-a1a3-b3bc6c7aa685"}
Statistic: {"receivedBytes":372,"errorRows":0,"committedTaskNum":1,"loadedRows":5,"loadRowsRate":0,"abortedTaskNum":0,"totalRows":5,"unselectedRows":0,"receivedBytesRate":0,"taskExecuteTimeMs":519}
Progress: {"0":"4"}
TimestampProgress: {"0":"1718217035111"}
ReasonOfStateChanged:
ErrorLogUrls:
TrackingSQL:
OtherMsg:
LatestSourcePosition: {"0":"5"}
1 row in set (0.00 sec)
Verify that data is stored in MinIO
MinIO を開き、http://localhost:9001/browser/ で my-starrocks-bucket の下にオブジェクトが保存されていることを確認します。
Query the data from StarRocks
USE quickstart;
SELECT * FROM site_clicks;
+------+--------------------------------------------+------------+
| uid | site | vtime |
+------+--------------------------------------------+------------+
| 4607 | https://www.starrocks.io/blog | 1718031441 |
| 1575 | https://www.starrocks.io/ | 1718031523 |
| 2398 | https://docs.starrocks.io/ | 1718033630 |
| 3741 | https://www.starrocks.io/product/community | 1718030845 |
| 4792 | https://www.starrocks.io/ | 1718033413 |
+------+--------------------------------------------+------------+
5 rows in set (0.07 sec)
Publish additional data
gen.py を再度実行すると、Redpanda にさらに 5 レコードが公開されます。
python gen.py 5
Verify that data is added
Routine Load ジョブはスケジュールに従って実行されるため(デフォルトでは 10 秒ごと)、データは数秒以内にロードされます。
SELECT * FROM site_clicks;
+------+--------------------------------------------+------------+
| uid | site | vtime |
+------+--------------------------------------------+------------+
| 6648 | https://www.starrocks.io/blog | 1718205970 |
| 7914 | https://www.starrocks.io/ | 1718206760 |
| 9854 | https://www.starrocks.io/blog | 1718205676 |
| 1186 | https://www.starrocks.io/ | 1718209083 |
| 3305 | https://docs.starrocks.io/ | 1718209083 |
| 2288 | https://www.starrocks.io/blog | 1718206759 |
| 7879 | https://www.starrocks.io/product/community | 1718204280 |
| 2666 | https://www.starrocks.io/ | 1718208842 |
| 5801 | https://www.starrocks.io/ | 1718208783 |
| 8409 | https://www.starrocks.io/ | 1718206889 |
+------+--------------------------------------------+------------+
10 rows in set (0.02 sec)
Configuration details
StarRocks を shared-data で使用する経験をした今、設定を理解することが重要です。
CN configuration
ここで使用されている CN 設定はデフォルトであり、CN は shared-data 用に設計されています。デフォルトの設定は以下の通りです。変更を加える必要はありません。
sys_log_level = INFO
# ports for admin, web, heartbeat service
be_port = 9060
be_http_port = 8040
heartbeat_service_port = 9050
brpc_port = 8060
starlet_port = 9070
FE configuration
FE 設定は、デフォルトとは若干異なり、FE はデータが BE ノードのローカルディスクではなく Object Storage に保存されることを期待するように設定されている必要があります。
docker-compose.yml ファイルは command で FE 設定を生成します。
# enable shared data, set storage type, set endpoint
run_mode = shared_data
cloud_native_storage_type = S3
この設定ファイルには FE のデフォルトエントリは含まれておらず、shared-data 設定のみが示されています。
デフォルトではない FE 設定:
多くの設定パラメータは s3_ で始まります。このプレフィックスは、すべての Amazon S3 互換ストレージタイプ(例:S3、GCS、MinIO)に使用されます。Azure Blob Storage を使用する場合、プレフィックスは azure_ です。
run_mode=shared_data
これは shared-data の使用を有効にします。
cloud_native_storage_type=S3
これは S3 互換ストレージまたは Azure Blob Storage が使用されるかどうかを指定します。MinIO の場合、常に S3 です。
Details of CREATE storage volume
CREATE STORAGE VOLUME s3_volume
TYPE = S3
LOCATIONS = ("s3://my-starrocks-bucket/")
PROPERTIES
(
"enabled" = "true",
"aws.s3.endpoint" = "minio:9000",
"aws.s3.access_key" = "AAAAAAAAAAAAAAAAAAAA",
"aws.s3.secret_key" = "BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB",
"aws.s3.use_instance_profile" = "false",
"aws.s3.use_aws_sdk_default_behavior" = "false"
);
aws_s3_endpoint=minio:9000
ポート番号を含む MinIO エンドポイント。
aws_s3_path=starrocks
バケット名。
aws_s3_access_key=AAAAAAAAAAAAAAAAAAAA
MinIO アクセスキー。
aws_s3_secret_key=BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB
MinIO アクセスキーシークレット。
aws_s3_use_instance_profile=false
MinIO を使用する場合、アクセスキーが使用されるため、インスタンスプロファイルは MinIO では使用されません。
aws_s3_use_aws_sdk_default_behavior=false
MinIO を使用する場合、このパラメータは常に false に設定されます。
Notes on the Routine Load command
StarRocks Routine Load は多くの引数を取ります。このチュートリアルで使用されているものだけがここで説明され、残りは詳細情報セクションでリンクされます。
CREATE ROUTINE LOAD quickstart.clicks ON site_clicks
PROPERTIES
(
"format" = "JSON",
"jsonpaths" ="[\"$.uid\",\"$.site\",\"$.vtime\"]"
)
FROM KAFKA
(
"kafka_broker_list" = "redpanda:29092",
"kafka_topic" = "test2",
"kafka_partitions" = "0",
"kafka_offsets" = "OFFSET_BEGINNING"
);
Parameters
CREATE ROUTINE LOAD quickstart.clicks ON site_clicks
CREATE ROUTINE LOAD ON のパラメータは:
- database_name.job_name
- table_name
database_name はオプションです。このラボでは quickstart で指定されています。
job_name は必須で、clicks です。
table_name は必須で、site_clicks です。
Job properties
Property format
"format" = "JSON",
この場合、データは JSON 形式であるため、プロパティは JSON に設定されます。他の有効な形式は:CSV、JSON、Avro です。デフォルトは CSV です。
Property jsonpaths
"jsonpaths" ="[\"$.uid\",\"$.site\",\"$.vtime\"]"
JSON 形式のデータからロードしたいフィールドの名前。このパラメータの値は有効な JsonPath 式です。詳細情報はこのページの最後で提供されています。
Data source properties
kafka_broker_list
"kafka_broker_list" = "redpanda:29092",
Kafka のブローカー接続情報。形式は <kafka_broker_name_or_ip>:<broker_ port> です。複数のブローカーはカンマで区切ります。
kafka_topic
"kafka_topic" = "test2",
消費する Kafka トピック。
kafka_partitions and kafka_offsets
"kafka_partitions" = "0",
"kafka_offsets" = "OFFSET_BEGINNING"
これらのプロパティは一緒に提示されます。kafka_partitions の各エントリに対して 1 つの kafka_offset が必要です。
kafka_partitions は消費する 1 つ以上のパーティションのリストです。このプロパティが設定されていない場合、すべてのパーティションが消費されます。
kafka_offsets は kafka_partitions にリストされた各パーティ�ションのオフセットのリストです。この場合、値は OFFSET_BEGINNING で、すべてのデータが消費されます。デフォルトは新しいデータのみを消費することです。
Summary
このチュートリアルでは:
- Docker で StarRocks、Reedpanda、Minio をデプロイしました
- Kafka トピックからデータを消費する Routine Load ジョブを作成しました
- MinIO を使用する StarRocks ストレージボリュームの設定方法を学びました
More information
このラボで使用されたサンプルは非常にシンプルです。Routine Load には多くのオプションと機能があります。詳細はこちら.
