テーブル概要
テーブルはデータストレージの単位です。StarRocks のテーブル構造を理解し、効率的なテーブル構造を設計することで、データの組織化を最適化し、クエリ効率を向上させることができます。また、従来のデータベースと比較して、StarRocks は JSON や ARRAY などの複雑な半構造化データをカラム形式で保存し、クエリパフォーマンスを向上させることができます。
このトピックでは、StarRocks のテーブル構造を基本的かつ一般的な視点から紹介します。
v3.3.1 以降、StarRocks は Default Catalog で一時テーブルの作成をサポートしています。
基本的なテーブル構造の入門
他のリレーショナルデータベースと同様に、テーブルは論理的に行と列で構成されています。
- 行: 各行はレコードを保持します。各行には関連するデータ値のセットが含まれています。
- 列: 列は各レコードの属性を定義します。各列は特定の属性のデータを保持します。たとえば、従業員テーブルには、名前、従業員 ID、部署、給与などの列が含まれる場合があります。各列は対応するデータを保存します。各列のデータは同じデータ型です。テーブル内のすべての行は同じ数の列を持ちます。
StarRocks でテーブルを作成するのは簡単です。CREATE TABLE ステートメントで列とそのデータ型を定義するだけでテーブルを作成できます。例:
CREATE DATABASE example_db;
USE example_db;
CREATE TABLE user_access (
uid int,
name varchar(64),
age int,
phone varchar(16),
last_access datetime,
credits double
)
ORDER BY (uid, name);
上記の CREATE TABLE の例は、重複キーテーブルを作成しています。このタイプのテーブルには列に制約が追加されないため、重複したデータ行がテーブル内に存在することができます。重複キーテーブルの最初の2つの列はソート列として指定され、ソートキーを形成します。データはソートキーに基づいてソートされた後に保存され、クエリ中のインデックス作成を加速することができます。
v3.3.0 以降、重複キーテーブルは ORDER BY を使用してソートキーを指定することをサポートしています。ORDER BY と DUPLICATE KEY の両方が使用される場合、DUPLICATE KEY は効果を持ちません。
ステージング環境の StarRocks クラスターに BE が 1 つしか含まれていない場合、PROPERTIES 句でレプリカ数を 1 に設定できます。例えば、PROPERTIES( "replication_num" = "1" ) のようにします。デフォルトのレプリカ数は 3 であり、これは本番環境の StarRocks クラスターに推奨される数でもあります。デフォルトの数を使用したい場合は、replication_num パラメータを設定する必要はありません。
DESCRIBE を実行してテーブルスキーマを表示します。
MySQL [test]> DESCRIBE user_access;
+-------------+-------------+------+-------+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------------+-------------+------+-------+---------+-------+
| uid | int | YES | true | NULL | |
| name | varchar(64) | YES | true | NULL | |
| age | int | YES | false | NULL | |
| phone | varchar(16) | YES | false | NULL | |
| last_access | datetime | YES | false | NULL | |
| credits | double | YES | false | NULL | |
+-------------+-------------+------+-------+---------+-------+
6 rows in set (0.00 sec)
SHOW CREATE TABLE を実行して CREATE TABLE ステートメントを表示します。
MySQL [example_db]> SHOW CREATE TABLE user_access\G
*************************** 1. row ***************************
Table: user_access
Create Table: CREATE TABLE `user_access` (
`uid` int(11) NULL COMMENT "",
`name` varchar(64) NULL COMMENT "",
`age` int(11) NULL COMMENT "",
`phone` varchar(16) NULL COMMENT "",
`last_access` datetime NULL COMMENT "",
`credits` double NULL COMMENT ""
) ENGINE=OLAP
DUPLICATE KEY(`uid`, `name`)
DISTRIBUTED BY RANDOM
ORDER BY(`uid`, `name`)
PROPERTIES (
"bucket_size" = "4294967296",
"compression" = "LZ4",
"fast_schema_evolution" = "true",
"replicated_storage" = "true",
"replication_num" = "3"
);
1 row in set (0.01 sec)
包括的なテーブル構造の理解
StarRocks のテーブル構造を深く理解することで、ビジネスニーズに合わせた効率的なデータ管理構造を設計することができます。
テーブルタイプ
StarRocks は、重複キーテーブル、主キーテーブル、集計テーブル、ユニークキーテーブルの4種類のテーブルを提供しており、生データ、頻繁に更新されるリアルタイムデータ、集計データなど、さまざまなビジネスシナリオに対応しています。
- 重複キーテーブルはシンプルで使いやすいです。このタイプのテーブルには列に制約が追加されないため、重複したデータ行がテーブル内に存在することができます。重複キーテーブルは、制約や事前集計を必要としないログなどの生データを保存するのに適しています。
- 主キーテーブルは強力です。主キー列には一意性と非 NULL 制約が追加されます。主キーテーブルはリアルタイムの頻繁な更新と部分的な列の更新をサポートし、高いクエリパフォーマンスを保証するため、リアルタイムクエリのシナリオに適しています。
- 集計テーブルは事前集計されたデータを保存するのに適しており、スキャンおよび計算されるデータ量を削減し、集計クエリの効率を向上させます。
- ユニークテーブルも頻繁に更新されるリアルタイムデータを保存するのに適しています。ただし、このタイプのテーブルは、より強力な主キーテーブルに置き換えられつつあります。
データ分散
StarRocks は、パーティション化 + バケッティングの2層データ分散戦略を使用して、データを BEs に均等に分散します。よく設計されたデータ分散戦略は、スキャンされるデータ量を効果的に削減し、StarRocks の同時処理能力を最大化し、クエリパフォーマンスを向上させます。
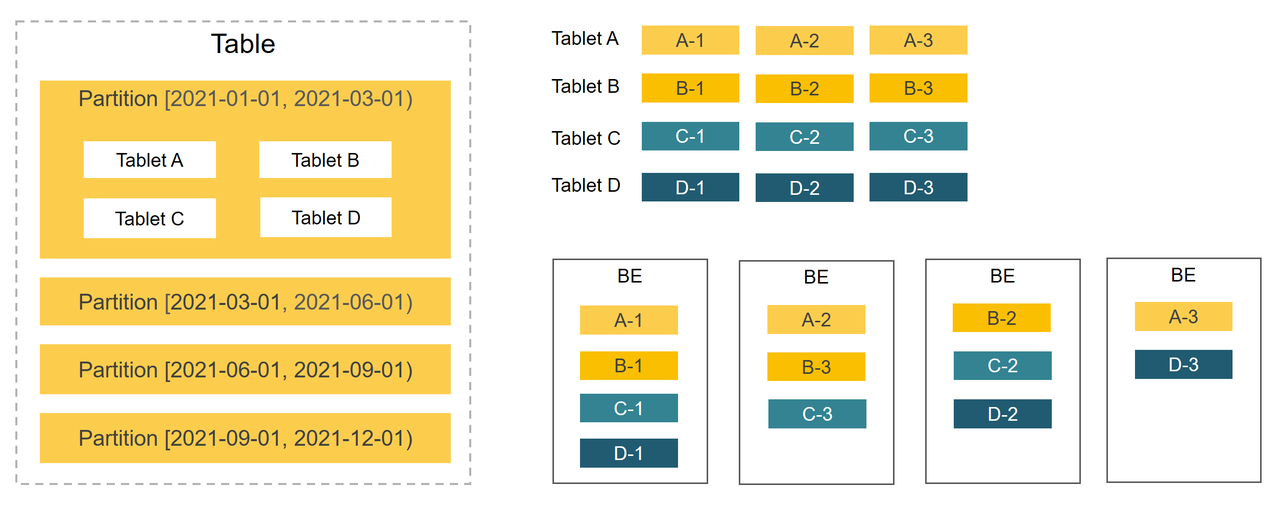
パーティション化
最初のレベルはパーティション化です。テーブル内のデータは、通常、日付や時間を保持するパーティション列に基づいて小さなデータ管理単位に分割できます。クエリ中に、パーティションプルーニングはスキャンする必要のあるデータ量を削減し、クエリパフォーマンスを効果的に最適化します。
StarRocks は、使いやすいパーティション化の手法である式に基づくパーティション化を提供し、範囲やリストパーティション化のような柔軟な方法も提供しています。
バケッティング
2番目のレベルはバケッティングです。パーティション内のデータは、バケッティングを通じてさらに小さなデータ管理単位に分割されます。各バケットのレプリカは BEs に均等に分散され、高いデータ可用性を確保します。
StarRocks は2つのバケッティング方法を提供しています。
- ハッシュバケッティング: バケッティングキーのハッシュ値に基づいてデータをバケットに分配します。クエリで条件列として頻繁に使用される列をバケッティング列として選択することで、クエリ効率を向上させることができます。
- ランダムバケッティング: データをランダムにバケットに分配します。このバケッティング方法はよりシンプルで使いやすいです。
データ型
NUMERIC、DATE、STRING などの基本的なデータ型に加えて、StarRocks は ARRAY、JSON、MAP、STRUCT などの複雑な半構造化データ型をサポートしています。
インデックス
インデックスは特別なデータ構造であり、テーブル内のデータへのポインタとして使用されます。クエリの条件列がインデックス列である場合、StarRocks は条件を満たすデータを迅速に特定できます。
StarRocks は組み込みのインデックスを提供しています。プレフィックスインデックス、オーディナルインデックス、ZoneMap インデックスです。また、ユーザーがインデックスを作成することも可能で、ビットマップインデックスやブルームフィルターインデックスを使用してクエリ効率をさらに向上させることができます。
制約
制約はデータの整合性、一貫性、正確性を保証するのに役立ちます。主キーテーブルの主キー列は一意で NULL でない値を持たなければなりません。集計テーブルの集計キー列とユニークキーテーブルのユニークキー列は一意の値を持たなければなりません。
一時テーブル
データを処理する際、将来の再利用のために中間結果を保存する必要があるかもしれません。初期のバージョンでは、StarRocks は単一のクエリ内で一時的な結果を定義するために CTE (共通テーブル式) の使用のみをサポートしていました。しかし、CTE は単なる論理構造であり、結果を物理的に保存せず、異なるクエリ間で使用することができないため、一定の制限があります。中間結果を保存するためにテーブルを作成することを選択した場合、これらのテーブルのライフサイクルを管理する必要があり、コストがかかります。
この問題に対処するために、StarRocks は v3.3.1 で一時テーブルを導入しました。一時テーブルを使用すると、ETL プロセスからの中間結果などのデータを一時的にテーブルに保存でき、そのライフサイクルはセッションに結び付けられ、StarRocks によって管理されます。セッションが終了すると、一時テーブルは自動的にクリアされます。一時テーブルは現在のセッション内でのみ表示され、異なるセッションで同じ名前の一時テーブルを作成することができます。
使用法
次の SQL ステートメントで TEMPORARY キーワードを使用して、一時テーブルを作成および削除できます。
他のタイプの内部テーブルと同様に、一時テーブルは Default Catalog のデータベースの下に作成する必要があります。ただし、一時テーブルはセッションベースであるため、一意の名前制約を受けません。異なるセッションで同じ名前の一時テーブルを作成したり、他の非一時的な内部テーブルと同じ名前の一時テーブルを作成することができます。
データベース内に同じ名前の一時テーブルと非一時テーブルがある場合、一時テーブルが優先されます。セッション内では、同じ名前のテーブルに対するすべてのクエリと操作は一時テーブルにのみ影響を与えます。
制限事項
一時テーブルの使用法は内部テーブルと似ていますが、いくつかの制約と違いがあります。
- 一時テーブルは Default Catalog に作成する必要があります。
- コロケートグループの設定はサポートされていません。テーブル作成時に
colocate_withプロパティが明示的に指定されている場合、それは無視されます。 - テーブル作成時に
ENGINEはolapと指定する必要があります。 - ALTER TABLE ステートメントはサポートされていません。
- 一時テーブルに基づくビューとマテリアライズドビューの作成はサポートされていません。
- EXPORT ステートメントはサポートされていません。
- SUBMIT TASK を使用した非同期タスクによる一時テーブルの作成、またはそれらからのデータ読み込み/書き込みはサポートされていません。
その他の機能
上記の機能に加えて、ビジネス要件に基づいて、より堅牢なテーブル構造を設計するために、さらに多くの機能を採用することができます。たとえば、ビットマップや HLL 列を使用して重複排除カウントを加速したり、生成列や自動インクリメント列を指定して一部のクエリを高速化したり、柔軟で自動的なストレージクールダウン方法を設定してメンテナンスコストを削減したり、Colocate Join を設定してマルチテーブルの JOIN クエリを高速化したりすることができます。詳細については、CREATE TABLE を参照してください。
