ローカルファイルシステムからデータをロードする
StarRocks は、ローカルファイルシステムからデータをロードするための2つの方法を提供しています。
- Stream Load を使用した同期ロード
- Broker Load を使用した非同期ロード
それぞれのオプションには独自の利点があります。
- Stream Load は CSV および JSON ファイル形式をサポートしています。この方法は、個々のサイズが 10 GB を超えない少数のファイルからデータをロードしたい場合に推奨されます。
- Broker Load は Parquet、ORC、CSV、および JSON ファイル形式をサポートしています(JSON ファイル形式は v3.2.3 以降でサポートされています)。この方法は、個々のサイズが 10 GB を超える多数のファイルからデータをロードしたい場合、またはファイルがネットワーク接続ストレージ (NAS) デバイスに保存されている場合に推奨されます。ローカルファイルシステムからデータをロードするために Broker Load を使用することは v2.5 以降でサポートされています。
CSV データの場合、次の点に注意してください。
- テキスト区切り文字として、UTF-8 文字列(カンマ (,) 、タブ、またはパイプ (|) など)を使用できます。長さは 50 バイトを超えないようにしてください。
- Null 値は
\Nを使用して示されます。たとえば、データファイルが 3 つの列で構成されており、そのデータファイルのレコードが第 1 列と第 3 列にデータを保持しているが、第 2 列にはデータがない場合、この状況では第 2 列に\Nを使用して Null 値を示す必要があります。つまり、レコードはa,\N,bとしてコンパイルされる必要があり、a,,bではありません。a,,bは、レコードの第 2 列が空の文字列を保持していることを示します。
Stream Load と Broker Load はどちらもデータロード時のデータ変換をサポートし、データロード中に UPSERT および DELETE 操作によって行われたデータの変更をサポートします。詳細については、Transform data at loading および Change data through loading を参照してください。
始める前に
権限を確認する
You can load data into StarRocks tables only as a user who has the INSERT privilege on those StarRocks tables. If you do not have the INSERT privilege, follow the instructions provided in GRANT to grant the INSERT privilege to the user that you use to connect to your StarRocks cluster. The syntax is GRANT INSERT ON TABLE <table_name> IN DATABASE <database_name> TO { ROLE <role_name> | USER <user_identity>}.
ネットワーク設定を確認する
ロードしたいデータが存在するマシンが、StarRocks クラスターの FE および BE ノードに http_port(デフォルト: 8030)および be_http_port(デフォルト: 8040)を介してアクセスできることを確��認してください。
Stream Load を介してローカルファイルシステムからロードする
Stream Load は HTTP PUT ベースの同期ロード方法です。ロードジョブを送信すると、StarRocks はジョブを同期的に実行し、ジョブが終了した後にジョブの結果を返します。ジョブ結果に基づいて、ジョブが成功したかどうかを判断できます。
注意
Stream Load を使用して StarRocks テーブルにデータをロードした後、そのテーブルに作成されたマテリアライズドビューのデータも更新されます。
動作の仕組み
クライアントで HTTP に従って FE にロードリクエストを送信できます。FE は HTTP リダイレクトを使用して、ロードリクエストを特定の BE または CN に転送します。また、クライアントで直接 BE または CN にロードリクエストを送信することもできます。
FE にロードリクエストを送信する場合、FE はポーリングメカニズムを使用して、どの BE または CN がコーディネーターとしてロードリクエストを受信および処理するかを決定します。ポーリングメカニズムは、StarRocks クラスター内での負荷分散を達成するのに役立ちます。したがって、FE にロードリクエストを送信することをお勧めします。
ロードリクエストを受信した BE または CN は、コーディネーター BE または CN として動作し、使用されるスキーマに基づいてデータを分割し、データの各部分を他の関与する BE または CN に割り当てます。ロードが終了すると、コーディネーター BE または CN はロードジョブの結果をクライアントに返します。ロード中にコーディネーター BE または CN を停止すると、ロードジョブは失敗します。
次の図は、Stream Load ジョブのワークフローを示しています。
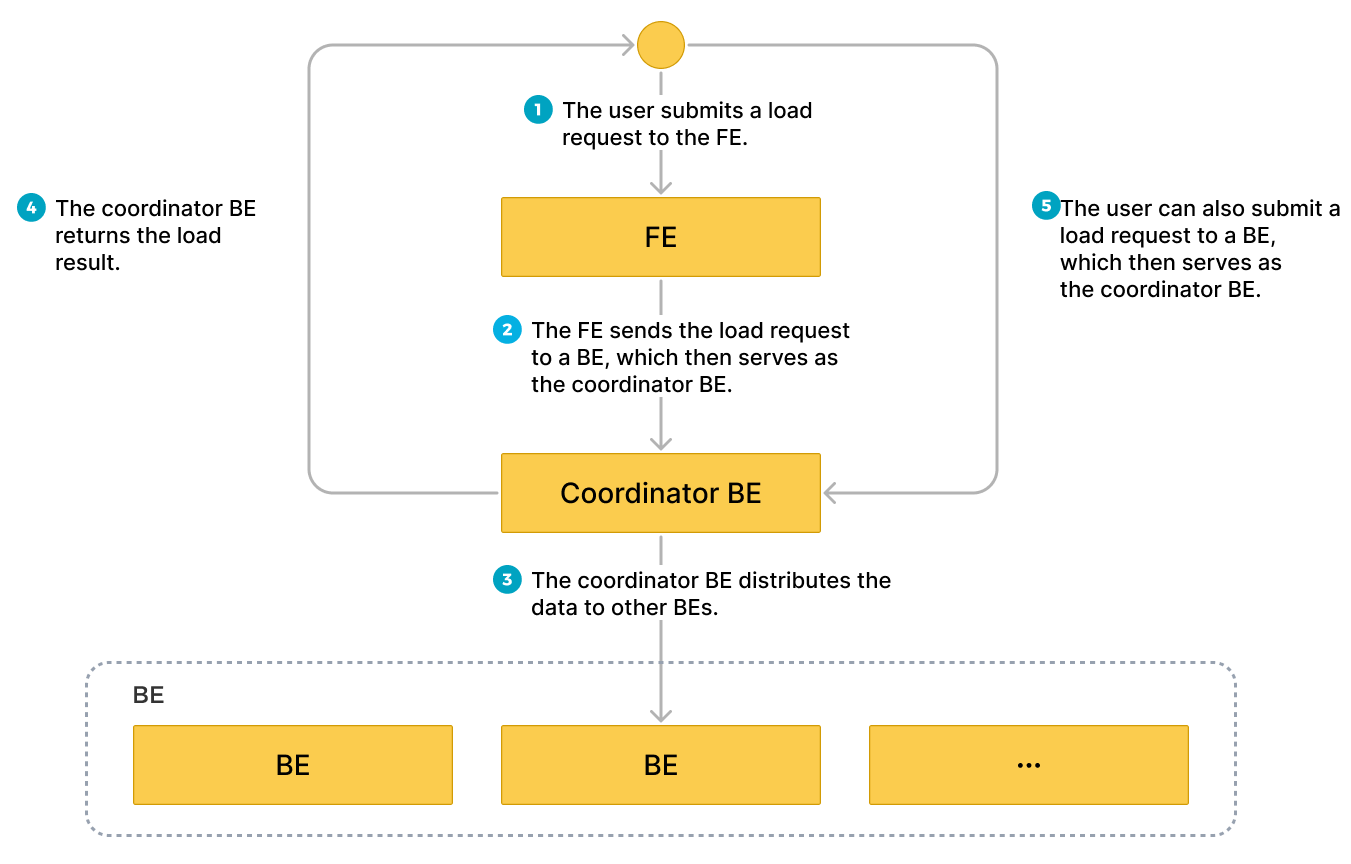
制限
Stream Load は、JSON 形式の列を含む CSV ファイルのデータをロードすることをサポートしていません。
典型的な例
このセクションでは、curl を例にして、ローカルファイルシステムから StarRocks に CSV または JSON ファイルのデータをロードする方法を説明します。詳細な構文とパラメーターの説明については、STREAM LOAD を参照してください。
StarRocks では、いくつかのリテラルが SQL 言語によって予約キーワードとして使用されます。これらのキーワードを SQL ステートメントで直接使用しないでください。このようなキーワードを SQL ステートメントで使用する場合は、バッククォート (`) で囲んでください。Keywords を参照してください。
CSV データをロードする
データセットを準備する
ローカルファイルシステムに example1.csv とい�う名前の CSV ファイルを作成します。このファイルは、ユーザー ID、ユーザー名、ユーザースコアを順に表す 3 つの列で構成されています。
1,Lily,23
2,Rose,23
3,Alice,24
4,Julia,25
データベースとテーブルを作成する
データベースを作成し、切り替えます。
CREATE DATABASE IF NOT EXISTS mydatabase;
USE mydatabase;
table1 という名前の主キーテーブルを作成します。このテーブルは、id、name、score の 3 つの列で構成され、id が主キーです。
CREATE TABLE `table1`
(
`id` int(11) NOT NULL COMMENT "user ID",
`name` varchar(65533) NULL COMMENT "user name",
`score` int(11) NOT NULL COMMENT "user score"
)
ENGINE=OLAP
PRIMARY KEY(`id`)
DISTRIBUTED BY HASH(`id`);
v2.5.7 以降、StarRocks はテーブルを作成する際やパーティションを追加する際に、バケット数 (BUCKETS) を自動的に設定できます。バケット数を手動で設定する必要はありません。詳細については、set the number of buckets を参照してください。
Stream Load を開始する
次のコマンドを実行して、example1.csv のデータを table1 にロードします。
curl --location-trusted -u <username>:<password> -H "label:123" \
-H "Expect:100-continue" \
-H "column_separator:," \
-H "columns: id, name, score" \
-T example1.csv -XPUT \
http://<fe_host>:<fe_http_port>/api/mydatabase/table1/_stream_load
- パスワードが設定されていないアカウントを使用する場合は、
<username>:のみを入力する必要があります。 - FE ノードの IP アドレスと HTTP ポートを表示するには、SHOW FRONTENDS を使用できます。
example1.csv は 3 つの列で構成されており、カンマ (,) で区切られ、table1 の id、name、score 列に順番にマッピングされます。したがって、column_separator パラメーターを使用してカンマ (,) を列区切り文字として指定する必要があります。また、columns パラメーターを使用して、example1.csv の 3 つの列を一時的に id、name、score と名付け、それらを table1 の 3 つの列に順番にマッピングする必要があります。
ロードが完了したら、table1 をクエリしてロードが成功したことを確認できます。
SELECT * FROM table1;
+------+-------+-------+
| id | name | score |
+------+-------+-------+
| 1 | Lily | 23 |
| 2 | Rose | 23 |
| 3 | Alice | 24 |
| 4 | Julia | 25 |
+------+-------+-------+
4 rows in set (0.00 sec)
JSON データをロードする
v3.2.7 以降、Stream Load は送信中に JSON データを圧縮することをサポートしており、ネットワーク帯域幅のオーバーヘッドを削減します。ユーザーは、compression および Content-Encoding パラメーターを使用して異なる圧縮アルゴリズムを指定できます。サポートされている圧縮アルゴリズムには、GZIP、BZIP2、LZ4_FRAME、および ZSTD があります。構文については、STREAM LOAD を参照してください。
データセットを準備する
ローカルファイルシステムに example2.json という名前の JSON ファイルを作成します。このファイルは、都市 ID と都市名を順に表す 2 つの列で構成されています。
{"name": "Beijing", "code": 2}
データベースとテーブルを作成する
データベースを作成し、切り替えます。
CREATE DATABASE IF NOT EXISTS mydatabase;
USE mydatabase;
table2 という名前の主キーテーブルを作成します。このテーブルは、id と city の 2 つの列で構成され、id が主キーです。
CREATE TABLE `table2`
(
`id` int(11) NOT NULL COMMENT "city ID",
`city` varchar(65533) NULL COMMENT "city name"
)
ENGINE=OLAP
PRIMARY KEY(`id`)
DISTRIBUTED BY HASH(`id`);
v2.5.7 以降、StarRocks はテーブルを作成する際やパーティションを追加する際に、バケット数 (BUCKETS) を自動的に設定できます。バケット数を手動で設定する必要はありません。詳細については、set the number of buckets を参照してください。
Stream Load を開始する
次のコマンドを実行して、example2.json のデータを table2 にロードします。
curl -v --location-trusted -u <username>:<password> -H "strict_mode: true" \
-H "Expect:100-continue" \
-H "format: json" -H "jsonpaths: [\"$.name\", \"$.code\"]" \
-H "columns: city,tmp_id, id = tmp_id * 100" \
-T example2.json -XPUT \
http://<fe_host>:<fe_http_port>/api/mydatabase/table2/_stream_load
- パスワードが設定されていないアカウントを使用する場合は、
<username>:のみを入力する必要があります。 - FE ノードの IP アドレスと HTTP ポートを表示するには、SHOW FRONTENDS を使用できます。
example2.json は name と code の 2 つのキーで構成されており、table2 の id と city 列にマッピングされています。以下の図に示されています。
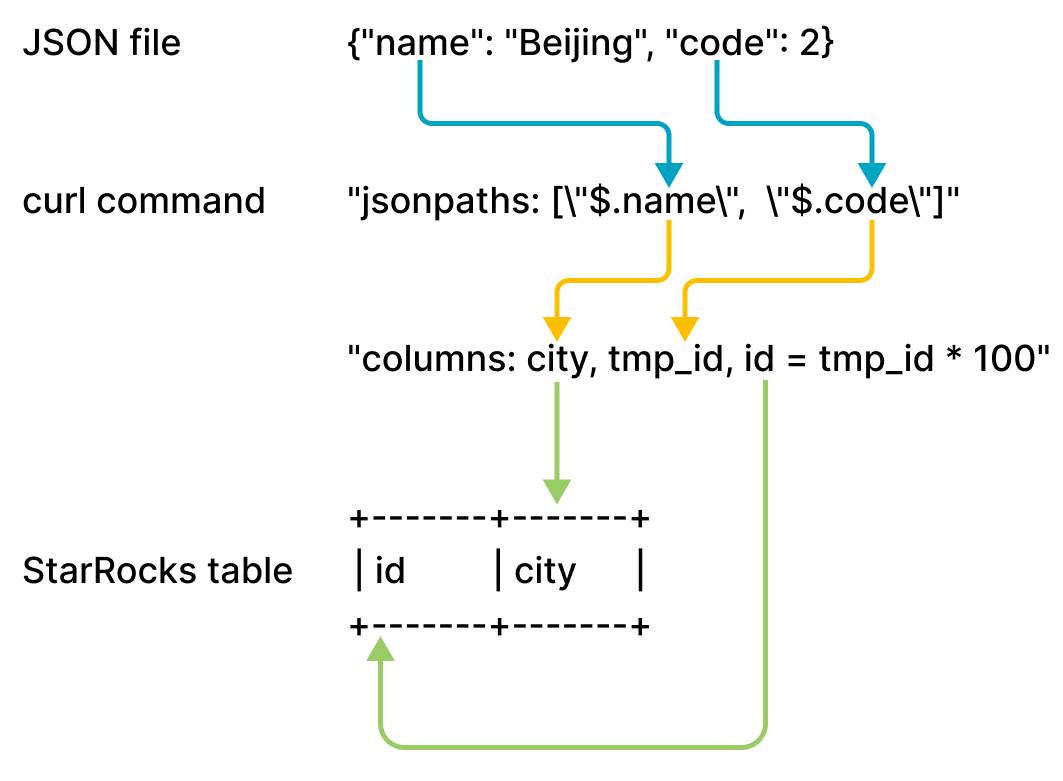
前述の図に示されているマッピングは次のように説明されます。
-
StarRocks は
example2.jsonのnameとcodeキーを抽出し、それらをjsonpathsパラメーターで宣言されたnameとcodeフィールドにマッピングします。 -
StarRocks は
jsonpathsパラメーターで宣言されたnameとcodeフィールドを抽出し、それらをcolumnsパラメーターで宣言されたcityとtmp_idフィールドに順番にマッピングします。 -
StarRocks は
columnsパラメーターで宣言されたcityとtmp_idフィールドを抽出し、それらをtable2のcityとid列に名前でマッピングします。
前述の例では、example2.json の code の値は、table2 の id 列にロードされる前に 100 倍されます。
jsonpaths、columns、および StarRocks テーブルの列間の詳細なマッピングについては、STREAM LOAD の「Column mappings」セクションを参照してください。
ロードが完了したら、table2 をクエリしてロードが成功したことを確認できます。
SELECT * FROM table2;
+------+--------+
| id | city |
+------+--------+
| 200 | Beijing|
+------+--------+
4 rows in set (0.01 sec)
Stream Load の進捗を確認する
ロードジョブが完了すると、StarRocks はジョブの結果を JSON 形式で返します。詳細については、STREAM LOAD の「Return value」セクションを参照してください。
Stream Load では、SHOW LOAD ステートメントを使用��してロードジョブの結果をクエリすることはできません。
Stream Load ジョブをキャンセルする
Stream Load では、ロードジョブをキャンセルすることはできません。ロードジョブがタイムアウトしたりエラーが発生した場合、StarRocks は自動的にジョブをキャンセルします。
パラメーター設定
このセクションでは、Stream Load を選択した場合に設定する必要があるいくつかのシステムパラメーターについて説明します。これらのパラメーター設定は、すべての Stream Load ジョブに適用されます。
-
streaming_load_max_mb: ロードしたい各データファイルの最大サイズ。デフォルトの最大サイズは 10 GB です。詳細については、Configure BE or CN dynamic parameters を参照してください。一度に 10 GB を超えるデータをロードしないことをお勧めします。データファイルのサイズが 10 GB を超える場合は、データファイルを 10 GB 未満の小さなファイルに分割し、それらのファイルを一つずつロードすることをお勧めします。10 GB を超えるデータファイルを分割できない場合は、�ファイルサイズに基づいてこのパラメーターの値を増やすことができます。
このパラメーターの値を増やした後、新しい値は StarRocks クラスターの BEs または CNs を再起動した後にのみ有効になります。さらに、システムパフォーマンスが低下し、ロード失敗時のリトライのコストも増加します。
注記JSON ファイルのデータをロードする際には、次の点に注意してください。
-
ファイル内の各 JSON オブジェクトのサイズは 4 GB を超えてはなりません。ファイル内の JSON オブジェクトが 4 GB を超える場合、StarRocks は "This parser can't support a document that big." というエラーをスローします。
-
デフォルトでは、HTTP リクエスト内の JSON ボディは 100 MB を超えてはなりません。JSON ボディが 100 MB を超える場合、StarRocks は "The size of this batch exceed the max size [104857600] of json type data data [8617627793]. Set ignore_json_size to skip check, although it may lead huge memory consuming." というエラーをスローします。��このエラーを防ぐために、HTTP リクエストヘッダーに
"ignore_json_size:true"を追加して JSON ボディサイズのチェックを無視することができます。
-
-
stream_load_default_timeout_second: 各ロードジョブのタイムアウト期間。デフォルトのタイムアウト期間は 600 秒です。詳細については、Configure FE dynamic parameters を参照してください。作成したロードジョブの多くがタイムアウトする場合は、次の式から得られる計算結果に基づいてこのパラメーターの値を増やすことができます。
各ロードジョブのタイムアウト期間 > ロードするデータ量/平均ロード速度
たとえば、ロードしたいデータファイルのサイズが 10 GB で、StarRocks クラスターの平均ロード速度が 100 MB/s の場合、タイムアウト期間を 100 秒以上に設定します。
注記前述の式における 平均ロード速度 は、StarRocks クラスターの平均ロード速度です。これは、ディスク I/O や StarRocks クラスター内の BEs または CNs の数によって異なります。
Stream Load では、個々のロードジョブのタイムアウト期間を指定できる
timeoutパラメーターも提供しています。詳細については、STREAM LOAD を参照してください。
使用上の注意
ロードしたいデータファイルのレコードにフィールドが欠けており、StarRocks テーブルのマッピング列が NOT NULL として定義されている場合、StarRocks はレコードのロード中にマッピング列に NULL 値を自動的に埋め込みます。また、ifnull() 関数を使用して埋め込みたいデフォルト値を指定することもできます。
たとえば、前述の example2.json ファイルで都市 ID を表すフィールドが欠けており、table2 のマッピング列に x 値を埋め込みたい場合、"columns: city, tmp_id, id = ifnull(tmp_id, 'x')" を指定できます。
Broker Load を介してローカルファイルシステムからロードする
Stream Load に加えて、Broker Load を使用してローカルファイルシステムからデータをロードすることもできます。この機能は v2.5 以降でサポートされています。
Broker Load は非同期ロード方法です。ロードジョブを送信すると、StarRocks はジョブを非同期に実行し、ジョブ結果をすぐには返しません。ジョブ結果を手動でクエリする必要があります。Check Broker Load progress を参照してください。
制限
- 現在、Broker Load は v2.5 以降の単一のブローカーを介してのみローカルファイルシステムからのロードをサポートしています。
- 単一のブローカーに対する高い並行クエリは、タイムアウトや OOM などの問題を引き起こす可能性があります。影響を軽減するために、
pipeline_dop変数(System variable を参照)を使用して Broker Load のクエリ並行性を設定できます。単一のブローカーに対するクエリの場合、pipeline_dopを16未満の値に設定することをお勧めします。
典型的な例
Broker Load は、単一のデータファイルから単一のテーブルへのロード、複数のデータファイルから単一のテーブルへのロード、および複数のデータファイルから複数のテーブルへのロードをサポートしています。このセクションでは、複数のデータファイルから単一のテーブルへのロードを例として使用します。
StarRocks では、いくつかのリテラルが SQL 言語によって予約キーワードとして使用されます。これらのキーワードを SQL ステートメントで直接使用しないでください。このようなキーワードを SQL ステートメントで使用する場合は、バッククォート (`) で囲んでください。Keywords を参照してください。
データセットを準備する
CSV ファイル形式を例として使用します。ローカルファイルシステムにログインし、特定のストレージ場所(たとえば、/home/disk1/business/)に file1.csv と file2.csv の 2 つの CSV ファイルを作成します。両方のファイルは、ユーザー ID、ユーザー名、ユーザースコアを順に表す 3 つの列で構成されています。
-
file1.csv1,Lily,21
2,Rose,22
3,Alice,23
4,Julia,24 -
file2.csv5,Tony,25
6,Adam,26
7,Allen,27
8,Jacky,28
データベースとテーブルを作成する
データベースを作成し、切り替えます。
CREATE DATABASE IF NOT EXISTS mydatabase;
USE mydatabase;
mytable という名前の主キーテーブルを作成します。このテーブルは、id、name、score の 3 つの列で構成され、id が主キーです。
CREATE TABLE `mytable`
(
`id` int(11) NOT NULL COMMENT "User ID",
`name` varchar(65533) NULL DEFAULT "" COMMENT "User name",
`score` int(11) NOT NULL DEFAULT "0" COMMENT "User score"
)
ENGINE=OLAP
PRIMARY KEY(`id`)
DISTRIBUTED BY HASH(`id`)
PROPERTIES("replication_num"="1");
Broker Load を開始する
次のコマンド��を実行して、ローカルファイルシステムの /home/disk1/business/ パスに保存されているすべてのデータファイル(file1.csv および file2.csv)から StarRocks テーブル mytable にデータをロードする Broker Load ジョブを開始します。
LOAD LABEL mydatabase.label_local
(
DATA INFILE("file:///home/disk1/business/csv/*")
INTO TABLE mytable
COLUMNS TERMINATED BY ","
(id, name, score)
)
WITH BROKER "sole_broker"
PROPERTIES
(
"timeout" = "3600"
);
このジョブには 4 つの主要なセクションがあります。
LABEL: ロードジョブの状態をクエリする際に使用される文字列。LOAD宣言: ソース URI、ソースデータ形式、および宛先テーブル名。PROPERTIES: タイムアウト値およびロードジョブに適用するその他のプロパティ。
詳細な構文とパラメーターの説明については、BROKER LOAD を参照してください。
Broker Load の進捗を確認する
v3.0 以前では、SHOW LOAD ステートメントまたは curl コマンドを使用して Broker Load ジョブの進捗を表示します。
v3.1 以降では、information_schema.loads ビューから Broker Load ジョブの進捗を表示できます。
SELECT * FROM information_schema.loads;
複数のロードジョブを送信した場合は、ジョブに関連付けられた LABEL でフィルタリングできます。例:
SELECT * FROM information_schema.loads WHERE LABEL = 'label_local';
ロードジョブが完了したことを確認した後、テーブルをクエリしてデータが正常にロードさ�れたかどうかを確認できます。例:
SELECT * FROM mytable;
+------+-------+-------+
| id | name | score |
+------+-------+-------+
| 3 | Alice | 23 |
| 5 | Tony | 25 |
| 6 | Adam | 26 |
| 1 | Lily | 21 |
| 2 | Rose | 22 |
| 4 | Julia | 24 |
| 7 | Allen | 27 |
| 8 | Jacky | 28 |
+------+-------+-------+
8 rows in set (0.07 sec)
Broker Load ジョブをキャンセルする
ロードジョブが CANCELLED または FINISHED ステージにない場合、CANCEL LOAD ステートメントを使用してジョブをキャンセルできます。
たとえば、次のステートメントを実行して、データベース mydatabase 内のラベルが label_local のロードジョブをキャンセルできます。
CANCEL LOAD
FROM mydatabase
WHERE LABEL = "label_local";
NAS から Broker Load を介してロードする
Broker Load を使用して NAS からデータをロードする方法は 2 つあります。
- NAS をローカルファイルシステムとして考慮し、ブローカーを使用してロードジョブを実行します。前のセクション「Loading from a local system via Broker Load」を参照してください。
- (推奨) NAS をクラウドストレージシステムとして考慮し、ブローカーなしでロードジョブを実行します。
このセクションでは、2 番目の方法を紹介します。詳細な操作は次のとおりです。
-
NAS デバイスを StarRocks クラスターのすべての BE または CN ノードおよび FE ノードに同じパスにマウントします。このようにして、すべての BE または CN は、NAS デバイスに自分のローカルに保存されたファイルにアクセスするようにアクセスできます。
-
Broker Load を使用して NAS デバイスから宛先 StarRocks テーブルにデータをロードします。例:
LOAD LABEL test_db.label_nas
(
DATA INFILE("file:///home/disk1/sr/*")
INTO TABLE mytable
COLUMNS TERMINATED BY ","
)
WITH BROKER
PROPERTIES
(
"timeout" = "3600"
);このジョブには 4 つの主要なセクションがあります。
LABEL: ロードジョブの状態をクエリする際に使用される文字列。LOAD宣言: ソース URI、ソースデータ形式、および宛先テーブル名。宣言内のDATA INFILEは、NAS デバイスのマウントポイントフォルダパスを指定するために使用されます。上記の例では、file:///がプレフィックスであり、/home/disk1/srがマウントポイントフォルダパスです。BROKER: ブローカー名を指定する必要はありません。PROPERTIES: タイムアウト値およびロードジョブに適用するその他のプロパティ。
詳細な構文とパラメーターの説明については、BROKER LOAD を参照してください。
ジョブを送信した後、必要に応じてロードの進捗を表示したり、ジョブをキャンセルしたりできます。詳細な操作については、このトピックの「Check Broker Load progress」および「Cancel a Broker Load job」を参照してください。
