数据湖分析
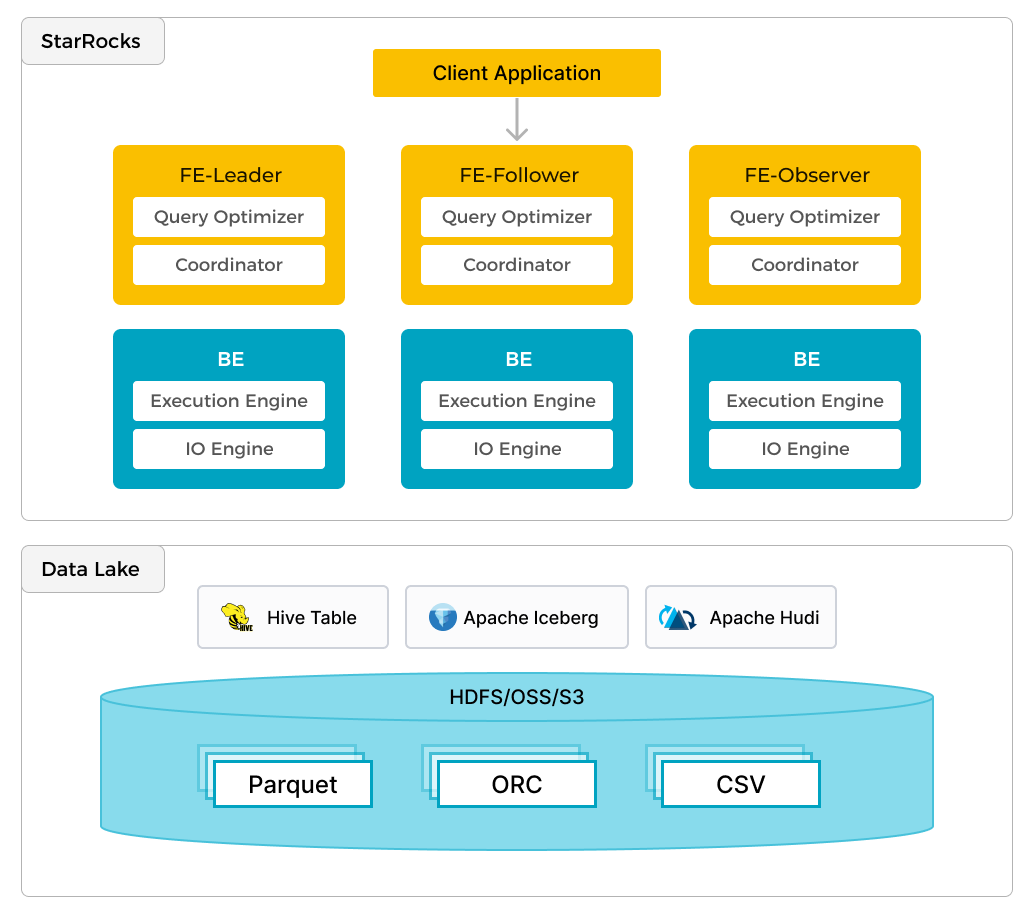
StarRocks 不仅能高效的分析本地存储的数据,也可以作为计算引擎直接分析数据湖中的数据。用户可以通过 StarRocks 提供的 External Catalog,轻松查询存储在 Apache Hive、Apache Iceberg、Apache Hudi、Delta Lake 等数据湖上的数据,无需进行数据迁移。支持的存储系统包括 HDFS、S3、OSS,支持的文件格式包括 Parquet、ORC、CSV。
如上图所示,在数据湖分析场景中,StarRocks 主要负责数据的计算分析,而数据湖则主要负责数据的存储、组织和维护。使用数据湖的优势在于可以使用开放的存储格式和灵活多变的 schema 定义方式,可以让 BI/AI/Adhoc/报表等业务有统一的 single source of truth。而 StarRocks 作为数据湖的计算引擎,可以充分发挥向量化引擎和 CBO 的优势,大大提升了数据湖分析的性能。
重点概念
-
开放的文件格式
支持各种常见的开源文件格式,如 JSON、Parquet、Avro 等,便于结构化和非结构化数据的存储与处理。
-
元数据管理
提供共享的元数据层,通常利用 Iceberg 表等格式,实现数据的高效组织和管理。
-
安全管理
内置强大有效的安全管理机制,全面管控数据安全、隐私与合规性,确保数据的完整性和可信度。
湖仓一体架构的优势
-
灵活性和可扩展性
支持无缝管理各种文件格式的数据,并能根据实际业务场景需求灵活扩展计算和存储能力。
-
成本效益
与传统方案相比,数据存储和处理更为经济有效。
-
数据治理能力增强
提升数据控制、管理和完整性,确保数据处理的可靠性和安全性。
-
AI 和分析场景适配性
完美契合机器学习和基于AI 的数据处理等各种涉及复杂的分析任务的用例场景。
StarRocks 湖仓一体
StarRocks 湖仓一体方案重点在于:
- 规范的 Catalog 及元数据服务集成
- 弹性可扩展的计算节点(简称 CN)
- 灵活的缓存机制
Catalog
StarRocks 提供两种类型的 Catalog:Internal Catalog 和 External Catalog。Internal Catalog 用于管理 StarRocks 数据库中存储的数据的元数据。External Catalog 用于连接存储在 Hive、Iceberg、Hudi、Delta Lake 等各种外部数据源中的数据。
计算节点
在存算分离架构下,存储和计算的分离降低了扩展的复杂度。StarRocks 计算节点仅存储本地缓存,方便您根据负载情况灵活地添加或移除计算节点。
Data cache
您可以根据实际情况选择打开或者关闭本地缓存。在计算节点因为负载变化过快而频繁启动和关闭、或者是查询大多集中在近期数据等场景下,数据缓存意义不大,可以无需开启缓存。
学习实践
基于 Docker 创建湖仓一体。具体操作参见教程 基于 Apache Iceberg 的数据湖分析。该教程中创建了一个对接 Iceberg 数据源和 MinIO 存储的数据湖,并对接 StarRocks 容器作为查询引擎。您可以直接导入教程中提供的数据集,也可以创建您自己的数据集。
