表概览
表是数据存储单元。理解 StarRocks 中的表结构,以及如何设计合理的表结构,有利于优化数据组织,提高查询效率。相比于传统的数据库,StarRocks 会以列的方式存储 JSON、ARRAY 等复杂的半结构化数据,保证高效查询。 本文由浅入深介绍表结构。
自 v3.3.1 起,StarRocks 支持在 Default Catalog 中创建临时表。
表结构入门
与其他关系型数据库一样,StarRocks 表在逻辑上由行(Row)和列(Column)构成:
- 行:每一行代表一条记录,包含了一组相关联的数据。
- 列:列定义了一条记录所包含的属性。每一列代表了特定属性的数据,例如,一个员工表可能包含姓名、工号、部门、薪水等列,每一列存储对应的数据,每列数据具有相同的数据类型。所有行的列数相同。
StarRocks 中建表操作简单易用,您只需要在 CREATE TABLE 语句中定义列和列的数据类型,即可创建一张表。
CREATE DATABASE example_db;
USE example_db;
CREATE TABLE user_access (
uid int,
name varchar(64),
age int,
phone varchar(16),
last_access datetime,
credits double
)
ORDER BY (uid, name);
上述建表示例创建了明细表,该表中数据不具有任何约束,相同的数据行可能会重复存在。并且指定明细表中前两列为排序列,构成排序键。数据按排序键排序后存储,有助于查询时的快速索引。
自 3.3.0 起,明细表支持使用 ORDER BY 指定排序键,如果同时使用 ORDER BY 和 DUPLICATE KEY,则 DUPLICATE KEY 不生效。
如果测试环境中集群仅包含一个 BE,可以在 PROPERTIES 中将副本数设置为 1,即 PROPERTIES( "replication_num" = "1" )。默认副本数为 3,也是生产集群推荐的副本数。如果您需要使用默认设置,也可以不配置 replication_num 参数。
执行 DESCRIBE 查看表结构。
MySQL [example_db]> DESCRIBE user_access;
+-------------+-------------+------+-------+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------------+-------------+------+-------+---------+-------+
| uid | int | YES | true | NULL | |
| name | varchar(64) | YES | true | NULL | |
| age | int | YES | false | NULL | |
| phone | varchar(16) | YES | false | NULL | |
| last_access | datetime | YES | false | NULL | |
| credits | double | YES | false | NULL | |
+-------------+-------------+------+-------+---------+-------+
6 rows in set (0.00 sec)
执行 SHOW CREATE TABLE 来查看建表语句。
MySQL [example_db]> SHOW CREATE TABLE user_access\G
*************************** 1. row ***************************
Table: user_access
Create Table: CREATE TABLE `user_access` (
`uid` int(11) NULL COMMENT "",
`name` varchar(64) NULL COMMENT "",
`age` int(11) NULL COMMENT "",
`phone` varchar(16) NULL COMMENT "",
`last_access` datetime NULL COMMENT "",
`credits` double NULL COMMENT ""
) ENGINE=OLAP
DUPLICATE KEY(`uid`, `name`)
DISTRIBUTED BY RANDOM
ORDER BY(`uid`, `name`)
PROPERTIES (
"bucket_size" = "4294967296",
"compression" = "LZ4",
"fast_schema_evolution" = "true",
"replicated_storage" = "true",
"replication_num" = "3"
);
1 row in set (0.01 sec)
全面了解表结构
本节详细介绍 StarRocks 表结构,帮助您深入了解表结构,根据场景设计高效的数据管理结构。
表类型
StarRocks 提供四种类型的表,包括明细表、主键表、聚合表和更新表,适用于存储多种业务数据,例如原始数据、实时频繁更新的数据和聚合数据。
- 明细表简单易用,表中数据不具有任何约束,相同的数据行可以重复存在。该表适用于存储不需要约束和预聚合的原始数据,例如日志等。
- 主键表能力强大,具有唯一性非空约束。该表能够在支撑实时更新、部分列更新等场景的同时,保证查询性能,适用于实时查询。
- 聚合表适用于存储预聚合后的数据,可以降低聚合查询时所需扫描和计算的数据量,极大提高聚合查询的效率。
- 更新表适用于实时更新的业务场景,目前已逐渐被主键表取代。
数据分布
StarRocks 采用分区+分桶的两级数据分布策略,将数据均匀分布各个 BE 节点。查询时能够有效裁剪数据扫描量,最大限度地利用集群的并发性能,从而提升查询性能。
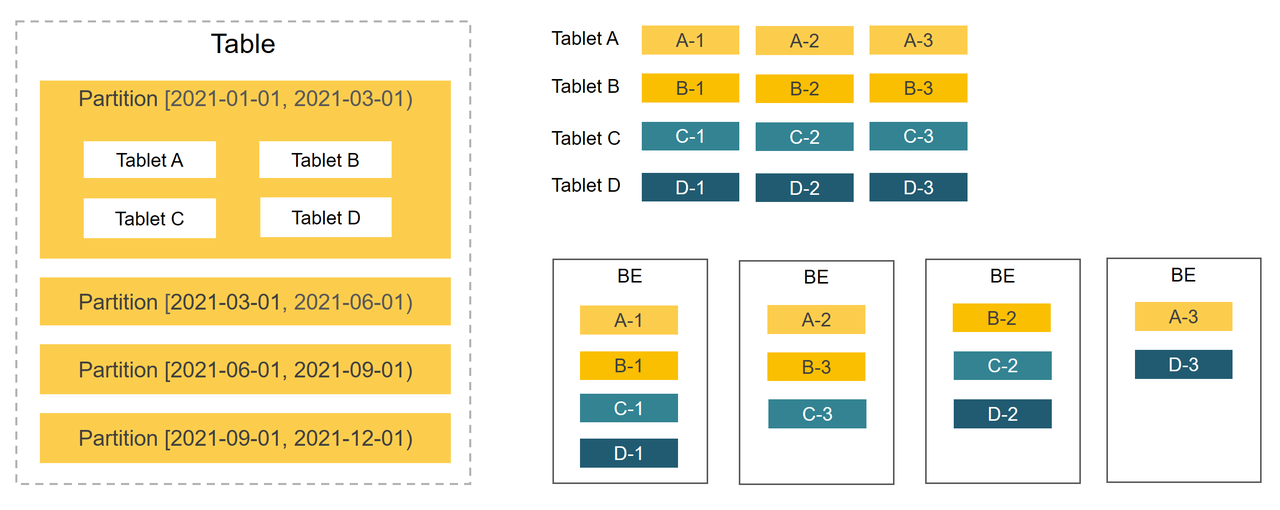
分区
第一层级为分区。表中数据可以根据分区列(通常是时间和日期)分成一个个更小的数据管理单元。查询时,通过分区裁剪,可以减少扫描的数据量,显著优化查询性能。
StarRocks 提供简单易用的分区方式,即表达式分区。此外还提供较灵活的分区方式,即 Range 分区和 List 分区。
分桶
第二层级为分桶。同一个分区中的数据通过分桶,划分成更小的数据管理单元。并且分桶以多副本形式(默认为3)均匀分布在 BE 节点上,保证数据的高可用。
StarRocks 提供两种分桶方式:
- 哈希分桶:根据数据的分桶键值,将数据划分至分桶。选择查询时经常使用的条件列组成分桶键,能有效提高查询效率。
- 随机分桶:随机划分数据至分桶。这种分桶方式更加简单易用。
数据类型
除了基本的数据类型,如数值、日期和字符串类型,StarRocks 还支持复杂的半结构化数据类型,包括 ARRAY、JSON、MAP、STRUCT。
索引
索引是一种特殊的数据结构,相当于数据的目录。查询条件命中索引列时,StarRocks 能够快速定位到满足条件的数据的位置。
StarRocks 提供内置索引,包括前缀索引、Ordinal 索引和 ZoneMap 索引。也支持用户手动创建索引,以提高查询效率,包括 Bitmap 和 Bloom Filter 索引。
约束
约束用于确保数据的完整性、一致性和准确性。主键表的 Primary Key 列具有唯一非空约束,聚合表的 Aggregate Key 列和更新表的 Unique Key 列具有唯一约束。
临时表
在处理数据时,您可能需要保存中间计算结果以便后续复用。先前版本中,StarRocks 仅支持在单个查询内利用 CTE(公用表表达式)来定义临时计算结果。然而,CTE 仅是逻辑概念,不会在物理上存储计算结果,且无法在不同查询间共享,存在一定局限性。如果您选择自行创建表来保存中间结果,需要自行维护表的生命周期,使用成本较高。
为了解决上述问题,StarRocks 在 v3.3.1 中引入了临时表。临时表允许您将临时数据暂存在表中(例如 ETL 计算的中间结果),其生命周期与 Session 绑定,并由 StarRocks 管理。Session 结束时,临时表会被自动清除。临时表仅在当前 Session 内可见,不同的 Session 内可以创建同名的临时表。
使用临时表
您可以在以下 SQL 语句中添加 TEMPORARY 关键字创建或删除临时表:
与其他类型的内表类似,临时表必须在属于在 Default Catalog 内的特定 Database 下创建。但由于临时表基于 Session,因此命名时不受唯一性约束。您可以在不同 Session 中创建同名临时表,或创建与其他内表同名的临时表。
如果同一 Database 中同时存在同名的临时表和非临时表,临时表具有最高访问优先级。在该 Session 内,所有针对同名表的查询和操作仅对临时表生效。
限制
临时表的使用方式与普通内表基本相同,但存在一些限制和差异:
- 临时表必须创建在 Default Catalog 中。
- 不支持设置 Colocate Group,若建表时显式指定了
colocate_with属性,该属性将被忽略。 - 建表时
ENGINE必须指定为olap。 - 不支持 ALTER TABLE 语句。
- 不支持基于临时表创建视图和物化视图。
- 不支持 EXPORT 语句导出。
- 不支持通过异步任务创建临时表或向其中导入/导出数据(通过 SUBMIT TASK 语句)。
更多特性
除了上述常用的特性之外,您还可以根据业务需求使用更多的特性,设计更加健壮的表结构,例如通过 Bitmap 和 HLL 列来加速去重计数,指定生成列或者自增列来加速部分查询,配置灵活的数据自动降冷策略来降低运维成本,配置 Colocate Join 来加速多表 JOIN 查询。
