表聚簇
精心设计的排序键(聚簇)是 StarRocks 中杠杆效应最高的物理设计“旋钮”。本文解释排序键的底层机制、它带来的系统性收益,以及为您的工作负载选择有效排序键的实操指南。
示例
假设您运行一个遥测系统,每天接收数十亿行数据,每行数据都标记有 device_id 和 ts(时间戳)。在您的事实表上定义 ORDER BY (device_id, ts) 可以确保:
- 对
device_id的点查询能在毫秒内返回。 - 仪表板过滤每个设备的最近时间窗口,从而裁剪大部分数据。
- 像
GROUP BY device_id这样的聚合受益于流式聚合。 - 由于每个设备的时间戳相邻,压缩效果得到改善。
这个简单的两列表达式 ORDER BY (device_id, ts),在数十亿行规模下也能带来显著的 I/O 减少、CPU 节省和更稳定的查询性能。
CREATE TABLE telemetry (
device_id VARCHAR,
ts DATETIME,
value DOUBLE
)
ENGINE=OLAP
PRIMARY KEY(device_id, ts)
PARTITION BY date_trunc('day', ts)
DISTRIBUTED BY HASH(device_id) BUCKETS 16
ORDER BY (device_id, ts);
收益详解
-
大规模 I/O 消除—Segment 和页面裁剪
工作原理:
每个 Segment 和 64 KB 页面都会为所有列保存最小/最大��值。若谓词超出该范围,StarRocks 会直接跳过该块,根本不触盘。
示例:
SELECT count(*)
FROM events
WHERE tenant_id = 42
AND ts BETWEEN '2025-05-01' AND '2025-05-07';使用
ORDER BY (tenant_id, ts)时,只会考虑第一个键等于 42 的 Segment;在这些 Segment 中,也仅扫描 ts 落在那 7 天窗口内的页面。对于 1000 亿行(100 B)级别的表,可能只需扫描不到 100 亿行(1 B),即可将分钟级查询压缩到秒级。
-
毫秒级点查—短键(前缀)索引
工作原理:
短键(前缀)索引以稀疏方式记录每约 1000 个排序键值。通过二分搜索先定位到正确页面,再通过一次磁盘读取(通常已缓存)返回目标行。
示例:
SELECT *
FROM orders
WHERE order_id = 982347234;使用
ORDER BY (order_id),在 500 亿行(50 B)级别的表上,探测大约只需 50 次键比较—��—即使数据处于冷缓存,也可实现小于 10 ms 延迟。
-
更快的排序聚合
工作原理:
当排序键与 GROUP BY 子句对齐时,StarRocks 在扫描过程中执行流式聚合——无需额外排序或构建哈希表。
该计划按排序键顺序扫描行,并实时产出分组,充分利用 CPU 缓存局部性,同时跳过中间物化。
示例:
SELECT device_id, COUNT(*)
FROM telemetry
WHERE ts BETWEEN '2025-01-01' AND '2025-01-31'
GROUP BY device_id;如果表是
ORDER BY (device_id, ts),引擎会在数据流入时直接分组——无需构建哈希表或重新排序。对于 device_id 这类高基数键,CPU 与内存占用都能显著下降。在高分组基数场景下,基于有序输入的流式聚合常比哈希聚合吞吐量提升 2–3 倍。
-
更高压缩,更热缓存
工作原理:
有序数据通常呈现较小的增量或较长的连续段,有利于字典、RLE、参考帧等编码方式,页面也能更紧凑地顺序流经 CPU 缓存。
示例:
某按 (device_id, ts) 排序的遥测表,相比未排序导入,同等 LZ4 下压缩率提升约 1.8×,CPU/扫描开销下降约 25%。
排序键的工作原理
排序键的影响从写入一刻开始,并贯穿每次读时优化。本节按生命周期梳理:写入路径 ➜ 存储层次 ➜ Segment 内部 ➜ 读取路径,展示各层如何叠加排序带来的价值。
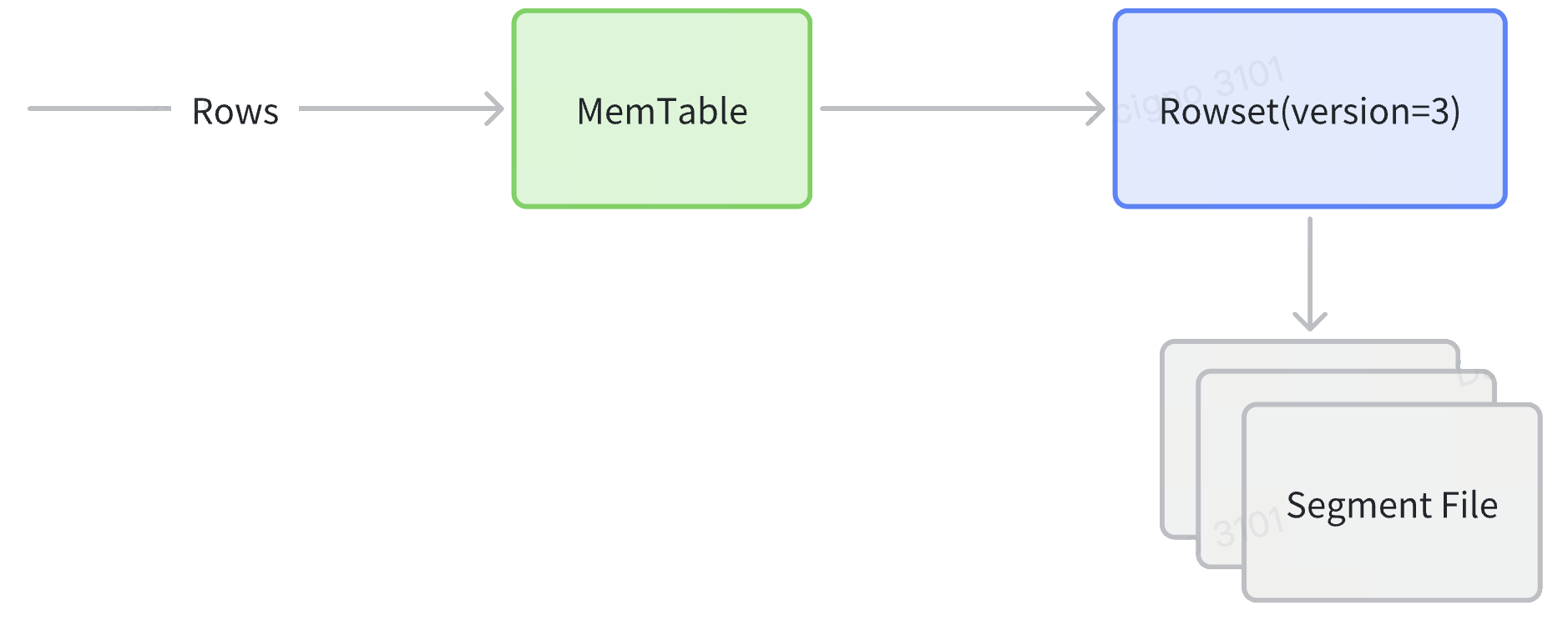
- 写入路径
- 采集:行进入 MemTable,按声明的排序键排序,随后以一个或多个有序 Segment 形成新的 Rowset 刷新到磁盘。
- Compaction:后台的累积/基础合并把多个小 Rowset 合并为更大的 Rowset,回收删除、降低 Segment 数量且无需重排顺序,因为源 Rowset 彼此共享相同的顺序。
- 复制:每个 Tablet(拥有 Rowset 的分片)会同步复制到对等 BE 节点,保证副本间的有序性一致。
- 存储层次
| 对象 | 定义 | 与排序键的关系 |
|---|---|---|
| Partition | 表的粗粒度逻辑切片(如日期、tenant_id)。 | 便于在计划阶段做分区裁剪,并隔离生命周期操作(TTL、批量导入)。 |
| Tablet | 分区内的哈希/随机分桶,独立复制到 BE。 | 行在此单元按排序键物理有序;分区内的裁剪从这里开始。 |
| MemTable | 内存写缓冲区(约 96 MB),刷新到磁盘前按声明键排序。 | 保证落盘的每个 Segment 已经有序,无需后续外排。 |
| Rowset | 由刷新、流式导入或 Compaction 产生的一个或多个 Segment 的不可变集合。 | 追加式设计使导入与读取互不干扰,读取侧保持无锁。 |
| Segment | Rowset 内部的自包含列式文件(通常约 512 MB),包含数据页与裁剪索引。 | Segment 级的裁剪(如 Zone Map、短键索引)依赖于 MemTable 阶段形成的顺序。 |
- Segment 文件内部
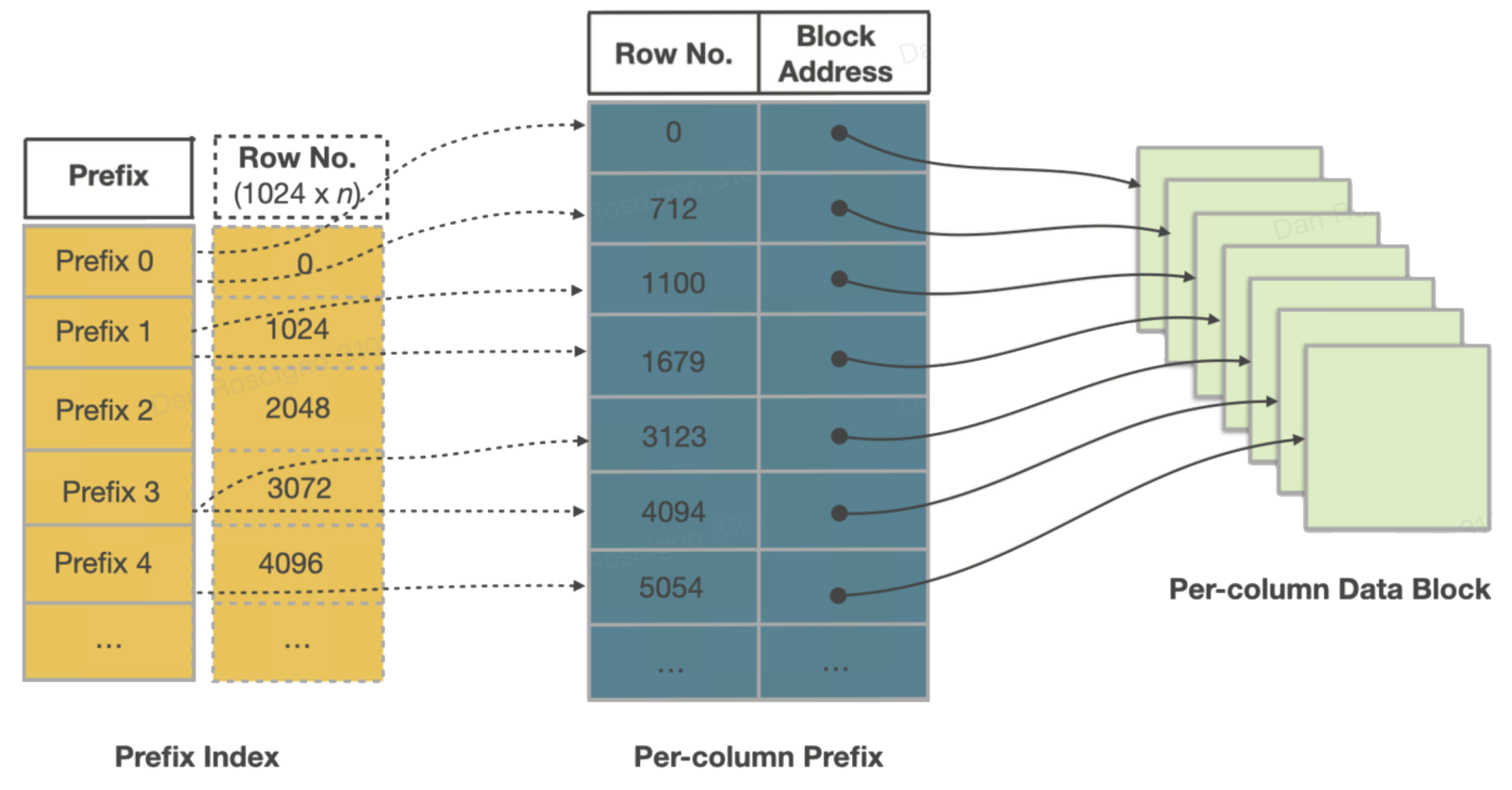
每个 Segment 都是自描述的。从上到下包含:
- 列数据页面:64 KB 块,采用字��典、RLE、Delta 等编码,并使用 LZ4(默认)压缩。
- 序号索引:将行序号映射到页面偏移,便于引擎直跳到第 n 页。
- Zone Map(区域映射)索引:记录每页及整个 Segment 的最小值、最大值和是否包含 NULL,是裁剪的第一道防线。
- 短键(前缀)索引:每约 1000 行记录一次排序键前 36 字节的稀疏二分搜索表,用于毫秒级点/范围定位。
- 页脚与魔术数:各索引的偏移及校验信息;StarRocks 可仅内存映射尾部即可发现其余结构。
由于页面已按键有序,这些索引虽小却极其高效。
-
读取路径
- 分区裁剪(计划时):当 WHERE 子句收敛到分区键(如
dt BETWEEN '2025‑05‑01' AND '2025‑05‑07')时,仅打开匹配的分区目录。 - Tablet 裁剪(计划时):当等值过滤包含哈希分布列时,StarRocks 计算目标 Tablet ID,仅调度这些 Tablet。
- 短键索引定位:基于前导排序列上的稀疏短键索引,直接命中目标 Segment 或页面。
- Zone Map 裁剪:利用 Segment 及页面级最小/最大元数据,丢弃不在谓词窗口内的块。
- 向量化扫描与延迟物化:保留下来的列页面顺序流经 CPU 缓存;仅物化所需的行与列,内存占用更紧凑。
由于每次刷新都按键顺序提交,读时各层裁剪彼此叠加,即便在数十亿行表上也能实现亚秒级扫描。
- 分区裁剪(计划时):当 WHERE 子句收敛到分区键(如
如何选择有效的排序键
-
从工作负载情报开始
先分析 Top‑N 查询模式:
- 等值谓词(
=/IN):几乎总是被等值过滤的列,是理想的前导候选。 - 范围谓词:时间戳和数值范围通常紧随等值列之后出现在排序键中。
- 聚合键:若某范围列也常出现在
GROUP BY中,将其(在高选择性过滤列之后)靠前放置,可启用有序聚合。 - 连接/分组键:若此类键常见,也可考虑前置。
评估列基数:高基数列(数百万级不同值)往往带来更强的裁剪效果。
- 等值谓词(
-
经验法则与注意事项
- 顺序规则: (高选择性等值列) → (主要范围列) → (辅助聚簇列)。
- 基数排序:将低基数列放在高基数列之前有助于增强压缩。
- 宽度:尽量控制在 3‑5 列。过宽的键会拖慢导入,并可能超出 36 字节的前缀索引限制。
- 字符串列:很长的前导字符串列可能占据前缀索引的多数甚至全部 36 字节,导致排序键中后续列无法被有效索引,从而削弱前缀索引的裁剪能力并降低点查性能。
-
与其他设计“旋钮”协同
- 分区:选择比前导排序列更粗粒度的分区键(如
PARTITION BY date且ORDER BY (tenant_id, ts))。先用分区裁剪剔除整段日期,再用排序裁剪做细化。 - 分桶:分桶与排序(聚簇)用途不同。分桶负责在集群内均匀分布数据;排序负责实现高效 I/O 裁剪。
- 表模型:主键表默认以主键作为排序键,也可追加其他列以进一步细化物理顺序、增强裁剪。聚合表与重复表可遵循前述基于分析谓词的排序键策略。
- 分区:选择比前导排序列更粗粒度的分区键(如
- 参考模板
| 场景 | 分区 | 排序键 | 理由 |
|---|---|---|---|
| B2C 订单 | date_trunc('day', order_ts) | (user_id, order_ts) | 大多数查询首先按用户过滤,然后按最近时间范围过滤。 |
| 物联网遥测 | date_trunc('day', ts) | (device_id, ts) | 设备范围的时间序列读取占主导地位。 |
| SaaS 多租户 | tenant_id | (dt, event_id) | 通过分区实现租户隔离;按天聚簇便于仪表盘展示。 |
| 维度查找 | 无 | (dim_id) | 小表,纯点查询——单列即可。 |
结论
一个设计良好的排序键,用小而可预期的导入开销,换来扫描时延、存储效率与 CPU 利用率的显著提升。基于真实工作负载做选择、尊重基数特性,并通过 EXPLAIN 验证计划,能帮助 StarRocks 在数据量与用户数增长 10× 乃至更多时依旧高效运行。
