Separate storage and compute
在存储与计算分离的系统中,数据存储在低成本、可靠的远端存储系统中,如 Amazon S3、Google Cloud Storage、Azure Blob Storage 和其他兼容 S3 的存储如 MinIO。热数据会被本地缓存,当缓存命中时,查询性能可与存储计算耦合架构相媲美。计算节点(CN)可以根据需求在几秒内添加或移除。这种架构降低了存储成本,确保了更好的资源隔离,并提供了弹性和可扩展性。
本教程涵盖:
- 在 Docker 容器中运行 StarRocks
- 使用 MinIO 作为对象存储
- 配置 StarRocks 以实现共享数据
- 导入两个公共数据集
- 使用 SELECT 和 JOIN 分析数据
- 基本数据转换(ETL 中的 T)
使用的数据由纽约市开放数据和 NOAA 的国家环境信息中心提供。
这两个数据集都非常大,因为本教程旨在帮助您接触 StarRocks 的使用,我们不会导入过去 120 年的数据。您可以在分配了 4 GB RAM 的机器上运行 Docker 镜像并导入这些数据。对于更大规模的容错和可扩展部署,我们有其他文档,并将在后续提供。
本文档包含大量信息,内容以步骤为主,技术细节在后面。这是为了按以下顺序实现这些目的:
- 允许读者在共享数据部署中导入数据并分析这些数据。
- 提供共享数据部署的配置细节。
- 解释数据导入过程中的基本数据转换。
前提条件
Docker
- Docker
- 分配给 Docker 的 4 GB RAM
- 分配给 Docker 的 10 GB 可用磁盘空间
SQL 客户端
您可以使用 Docker 环境中提供的 SQL 客户端,或使用您系统上的客�户端。许多兼容 MySQL 的客户端都可以使用,本指南涵盖了 DBeaver 和 MySQL Workbench 的配置。
curl
curl 用于向 StarRocks 发起数据导入任务,并下载数据集。通过在操作系统提示符下运行 curl 或 curl.exe 来检查是否已安装 curl。如果未安装 curl,请在此获取 curl。
/etc/hosts
本指南中使用的导入方法是 Stream Load。Stream Load 连接到 FE 服务以启动导入任务。然后 FE 将任务分配给后端节点,即本指南中的 CN。为了使导入任务能够连接到 CN,CN 的名称必须在您的操作系统中可用。将以下行添加到 /etc/hosts:
127.0.0.1 starrocks-cn
术语
FE
前端节点负责元数据管理、客户端连接管理、查询规划和查询调度。每个 FE 在其内存中存储并维护一份完整的元数据副本,确保 FEs 之间的服务无差别。
CN
计算节点负责在共享数据部署中执行查询计划。
BE
后端节点负责在无共享部署中进行数据存储和执行查询计划。
本指南不使用 BEs,此信息仅供您了解 BEs 和 CNs 之间的区别。
编辑您的 hosts 文件
本指南中使用的导入方法是 Stream Load。Stream Load 连接到 FE 服务以启动导入任务。然后 FE 将任务分配给后端节点——本指南中的 CN。为了使导入任务能够连接到 CN,CN 的名称必须在您的操作系统中可用。将以下行添加到 /etc/hosts:
127.0.0.1 starrocks-cn
下载实验文件
需要下载三个文件:
- 部署 StarRocks 和 MinIO 环境的 Docker Compose 文件
- 纽约市交通事故数据
- 天气数据
本指南使用 MinIO,它是根据 GNU Affero 通用公共许可证提供的兼容 S3 的对象存储。
创建一个目录来存储实验文件
mkdir quickstart
cd quickstart
下载 Docker Compose 文件
curl -O https://raw.githubusercontent.com/StarRocks/demo/master/documentation-samples/quickstart/docker-compose.yml
下载数据
下载这两个数据集:
纽约市交通事故数据
curl -O https://raw.githubusercontent.com/StarRocks/demo/master/documentation-samples/quickstart/datasets/NYPD_Crash_Data.csv
天气数据
curl -O https://raw.githubusercontent.com/StarRocks/demo/master/documentation-samples/quickstart/datasets/72505394728.csv
部署 StarRocks 和 MinIO
docker compose up --detach --wait --wait-timeout 120
FE、CN 和 MinIO 服务变为健康状态大约需要 30 秒。quickstart-minio_mc-1 容器将显示 Waiting 状态和一个退出代码。退出代码为 0 表示成功。
[+] Running 4/5
✔ Network quickstart_default Created 0.0s
✔ Container minio Healthy 6.8s
✔ Container starrocks-fe Healthy 29.3s
⠼ Container quickstart-minio_mc-1 Waiting 29.3s
✔ Container starrocks-cn Healthy 29.2s
container quickstart-minio_mc-1 exited (0)
MinIO
本快速入门使用 MinIO 进行共享存储。
验证 MinIO 凭证
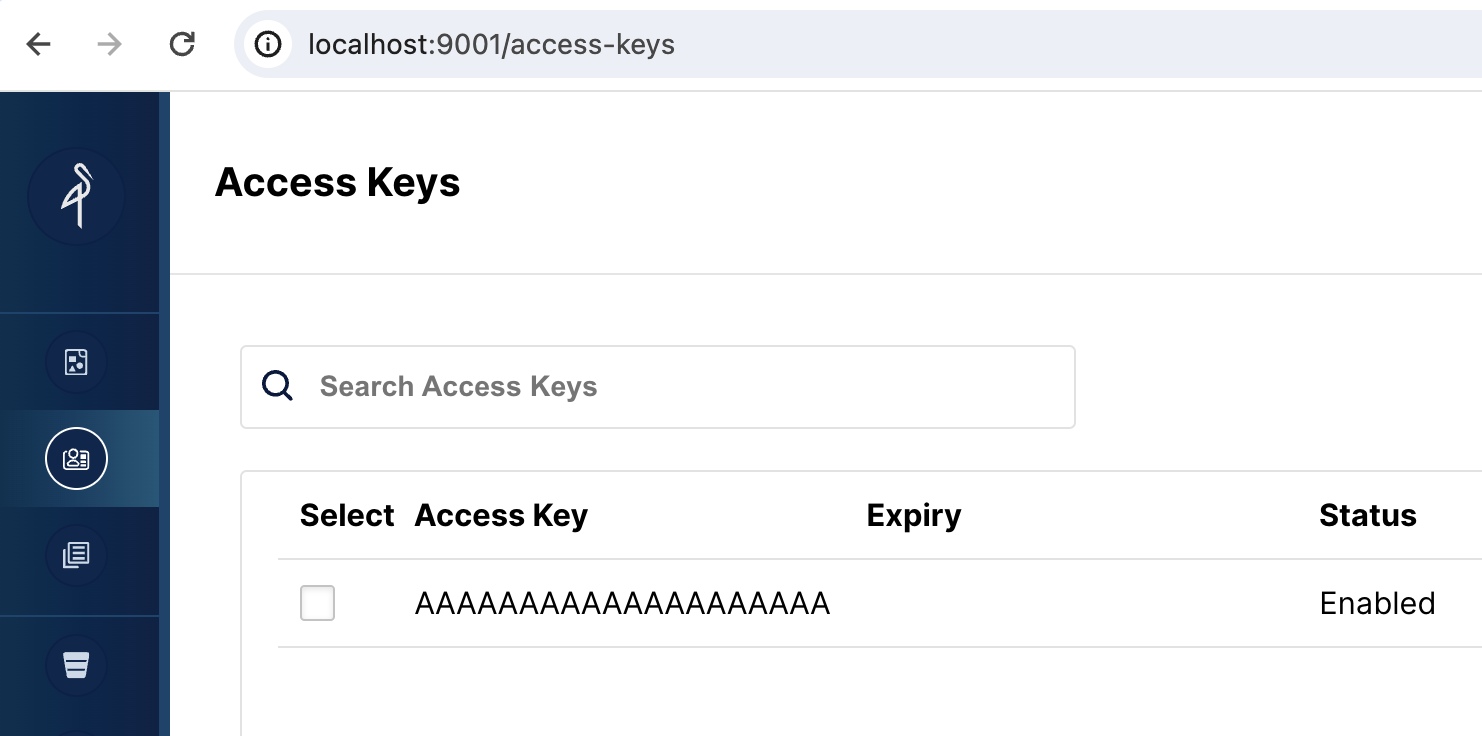
要将 MinIO 用作 StarRocks 的对象存储,StarRocks 需要一个 MinIO 访问密钥。访问密钥是在 Docker 服务启动时生成的。为了帮助您更好地理解 StarRocks 如何连接到 MinIO,您应该验证密钥是否存在。
浏览到 http://localhost:9001/access-keys 用户名和密码在 Docker compose 文件中指定,分别是 miniouser 和 miniopassword。��您应该看到有一个访问密钥。密钥是 AAAAAAAAAAAAAAAAAAAA,您无法在 MinIO 控制台中看到密钥,但它在 Docker compose 文件中是 BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB:
如果 MinIO 网页 UI 中没有显示访问密钥,请检查 minio_mc 服务的日志:
docker compose logs minio_mc
尝试重新运行 minio_mc pod:
docker compose run minio_mc
为您的数据创建一个 bucket
当您在 StarRocks 中创建一个存储卷时,您将指定数据的 LOCATION:
LOCATIONS = ("s3://my-starrocks-bucket/")
打开 http://localhost:9001/buckets 并为存储卷添加一个 bucket。将 bucket 命名为 my-starrocks-bucket。接受列出的三个选项的默认值。
SQL 客户端
当前教程可以使用以下三个客户端进行测试,您只需选择其中一个:
- MySQL CLI:您可以从 Docker 环境或您的本机运行此客户端。
- DBeaver(社区版或专业版)
- MySQL Workbench
配置客户端
- mysql CLI
- DBeaver
- MySQL Workbench
您可以从 StarRocks FE 节点容器 starrocks-fe 中直接运行 MySQL Client:
docker compose exec starrocks-fe \
mysql -P 9030 -h 127.0.0.1 -u root --prompt="StarRocks > "
所有 docker compose 命令必须从包含 docker-compose.yml 文件的目录中运行。
如果您需要安装 MySQL Client,请点击展开以下 安装 MySQL 客户端 部分:
安装 MySQL 客户端
- macOS:如果您使用 Homebrew 并且不需要安装 MySQL 服务器,请运行
brew install mysql-client@8.0安装 MySQL Client。 - Linux:请检查您的
mysql客户端的 Repository。例如,运行yum install mariadb。 - Microsoft Windows:安装 MySQL Community Server 后,运行提供的客户端,或在 WSL 中运行
mysql。
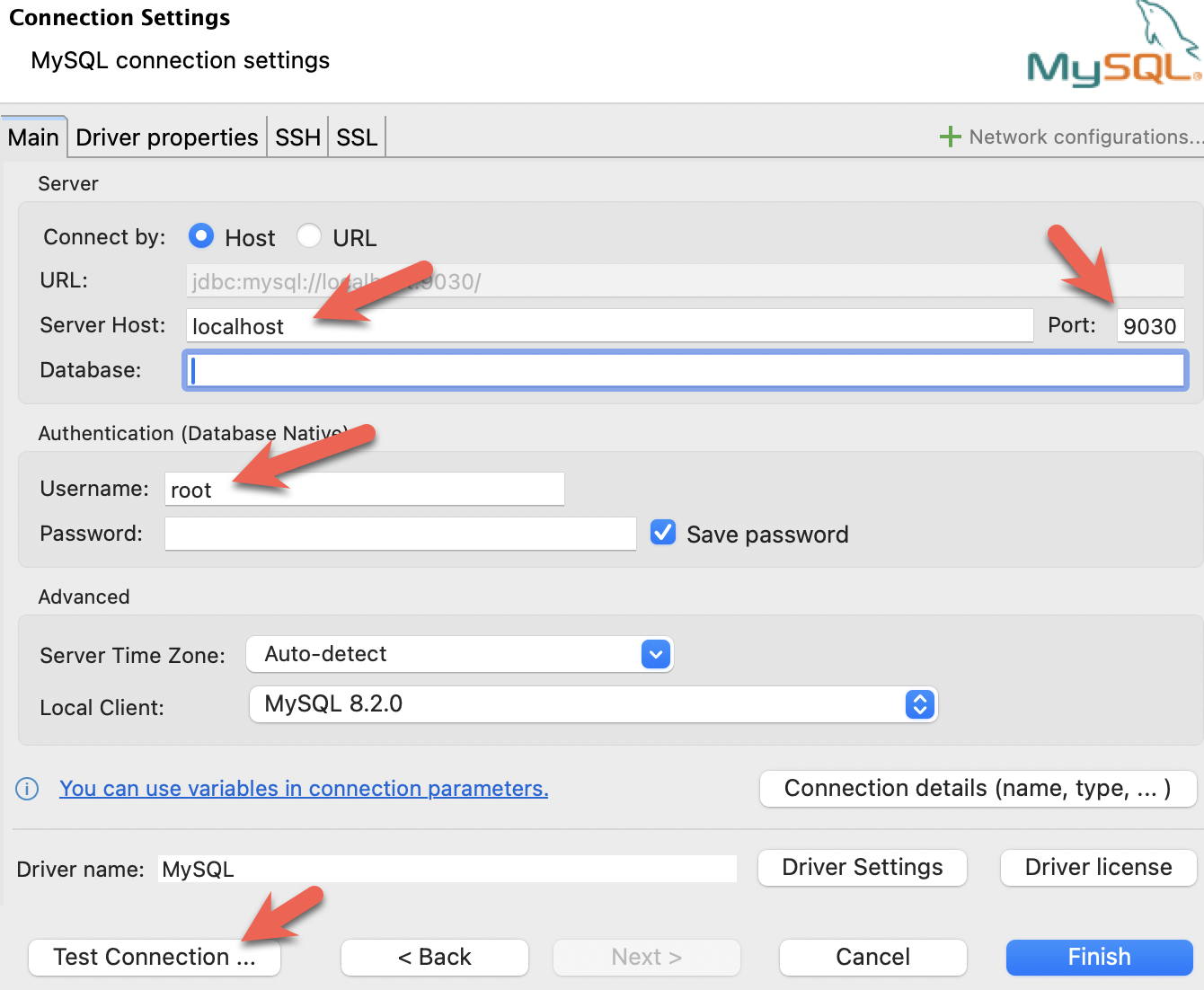
- 安装 DBeaver 并连接 StarRocks。

- 配置端口、IP 地址和用户名,并点击 Test Connection 测试连接。如果测试成功,请点击 Finish 完成配置。
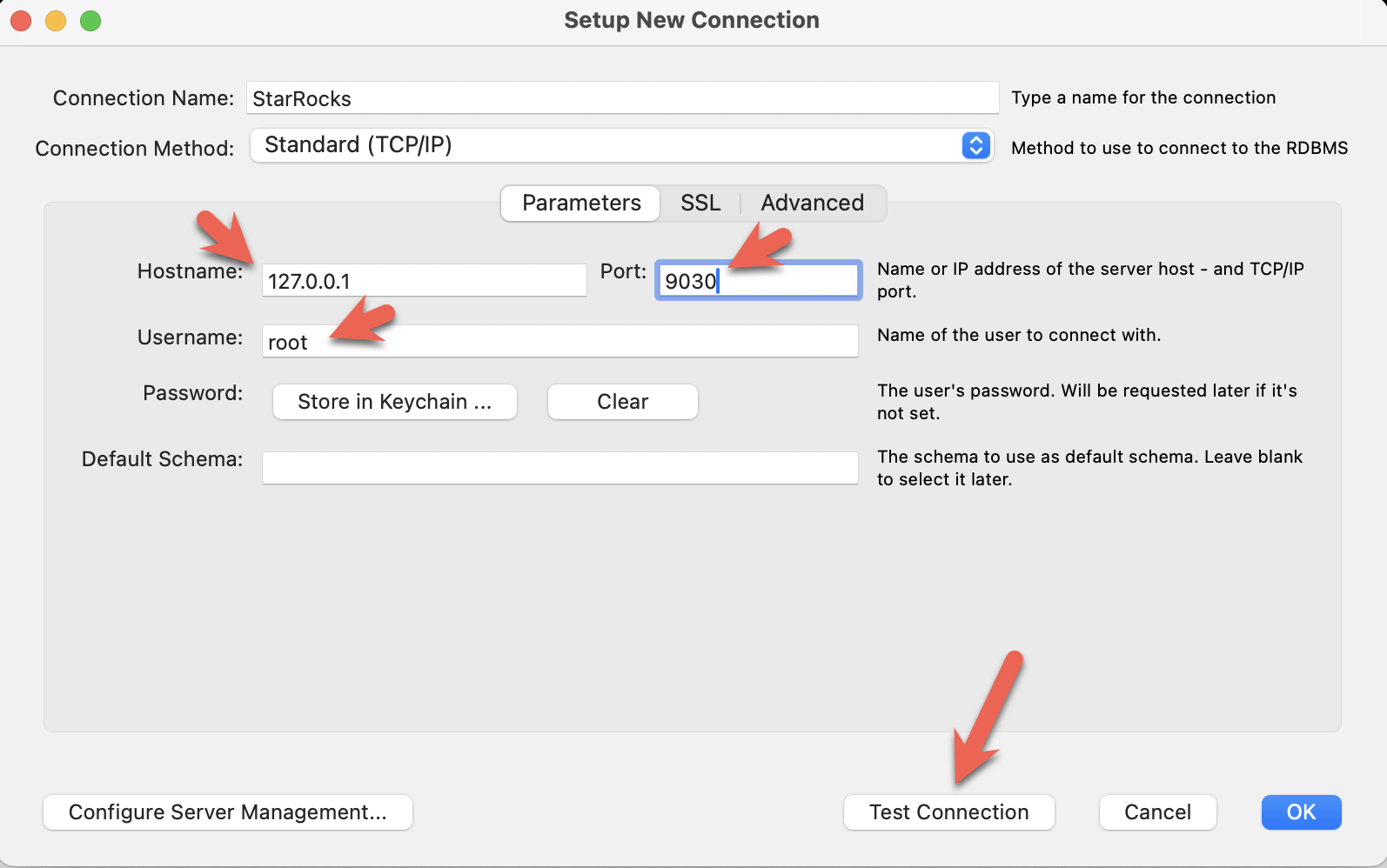
- 安装 MySQL Workbench 并连接 StarRocks。
- 配置端口、IP 地址和用户名,并点击 Test Connection 测试连接。
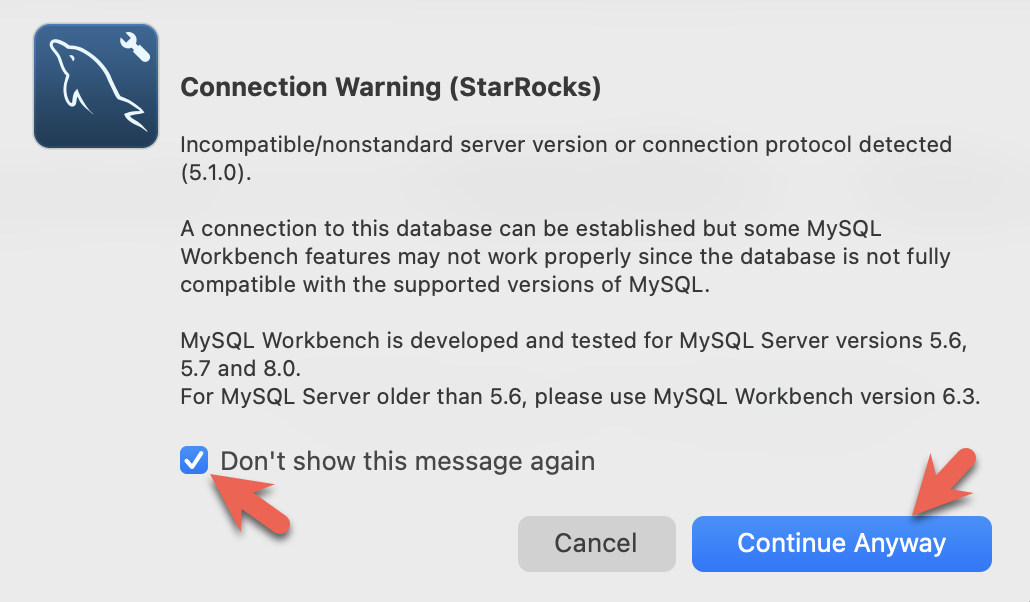
- 在 Workbench 检查 MySQL 版本时,会弹出以下警告。您可以忽略这些警告,并选择不再提示:
StarRocks 的共享数据配置
此时,您已经运行了 StarRocks,并且 MinIO 也在运行。MinIO 访问密钥用于连接 StarRocks 和 MinIO。
这是 FE 配置的一部分,指定 StarRocks 部署将使用共享数据。这是在 Docker Compose 创建部署时添加到文件 fe.conf 中的。
# enable the shared data run mode
run_mode = shared_data
cloud_native_storage_type = S3
您可以通过从 quickstart 目录运行此命令并查看文件末尾来验证这些设置:
docker compose exec starrocks-fe \
cat /opt/starrocks/fe/conf/fe.conf
:::
使用 SQL 客户端连接到 StarRocks
从包含 docker-compose.yml 文件的目录运行此命令。
如果您使用的是 MySQL 命令行客户端以外的客户端,请现在打开它。
docker compose exec starrocks-fe \
mysql -P9030 -h127.0.0.1 -uroot --prompt="StarRocks > "
检查存储卷
SHOW STORAGE VOLUMES;
应该没有存储卷,您将接下来创建一个。
Empty set (0.04 sec)
创建一个共享数据存储卷
之前您在 MinIO 中创建了一个名为 my-starrocks-volume 的 bucket,并验证了 MinIO 有一个名为 AAAAAAAAAAAAAAAAAAAA 的访问密钥。以下 SQL 将在 MionIO bucket 中使用访问密钥和密钥创建一个存储卷。
CREATE STORAGE VOLUME s3_volume
TYPE = S3
LOCATIONS = ("s3://my-starrocks-bucket/")
PROPERTIES
(
"enabled" = "true",
"aws.s3.endpoint" = "minio:9000",
"aws.s3.access_key" = "AAAAAAAAAAAAAAAAAAAA",
"aws.s3.secret_key" = "BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB",
"aws.s3.use_instance_profile" = "false",
"aws.s3.use_aws_sdk_default_behavior" = "false"
);
现在您应该看到一个存储卷列出,之前是空集:
SHOW STORAGE VOLUMES;
+----------------+
| Storage Volume |
+----------------+
| s3_volume |
+----------------+
1 row in set (0.02 sec)
查看存储卷的详细信息,并注意这还不是默认卷,并且它被配置为使用您的 bucket:
DESC STORAGE VOLUME s3_volume\G
本文档中的一些 SQL 以及 StarRocks 文档中的许多其他文档以 \G 而不是分号结束。 \G 使 mysql CLI 垂直呈现查询结果。
许多 SQL 客户端不解释垂直格式输出,因此您应将 \G 替换为 ;。
*************************** 1. row ***************************
Name: s3_volume
Type: S3
IsDefault: false
Location: s3://my-starrocks-bucket/
Params: {"aws.s3.access_key":"******","aws.s3.secret_key":"******","aws.s3.endpoint":"minio:9000","aws.s3.region":"us-east-1","aws.s3.use_instance_profile":"false","aws.s3.use_web_identity_token_file":"false","aws.s3.use_aws_sdk_default_behavior":"false"}
Enabled: true
Comment:
1 row in set (0.02 sec)
设置默认存储卷
SET s3_volume AS DEFAULT STORAGE VOLUME;
DESC STORAGE VOLUME s3_volume\G
*************************** 1. row ***************************
Name: s3_volume
Type: S3
IsDefault: true
Location: s3://my-starrocks-bucket/
Params: {"aws.s3.access_key":"******","aws.s3.secret_key":"******","aws.s3.endpoint":"minio:9000","aws.s3.region":"us-east-1","aws.s3.use_instance_profile":"false","aws.s3.use_web_identity_token_file":"false","aws.s3.use_aws_sdk_default_behavior":"false"}
Enabled: true
Comment:
1 row in set (0.02 sec)
创建一个数据库
CREATE DATABASE IF NOT EXISTS quickstart;
验证数据库 quickstart 是否使用存储卷 s3_volume:
SHOW CREATE DATABASE quickstart \G
*************************** 1. row ***************************
Database: quickstart
Create Database: CREATE DATABASE `quickstart`
PROPERTIES ("storage_volume" = "s3_volume")
创建一些表
创建数据库
执行以下语句创建数据库 quickstart,并切换到该数据库下。
CREATE DATABASE IF NOT EXISTS quickstart;
USE quickstart;
建表
crashdata 表
创建 crashdata 表,用于存储交通事故数据集中的数据。该表的字段经过裁剪,仅包含与该教程相关字段。
CREATE TABLE IF NOT EXISTS crashdata (
CRASH_DATE DATETIME,
BOROUGH STRING,
ZIP_CODE STRING,
LATITUDE INT,
LONGITUDE INT,
LOCATION STRING,
ON_STREET_NAME STRING,
CROSS_STREET_NAME STRING,
OFF_STREET_NAME STRING,
CONTRIBUTING_FACTOR_VEHICLE_1 STRING,
CONTRIBUTING_FACTOR_VEHICLE_2 STRING,
COLLISION_ID INT,
VEHICLE_TYPE_CODE_1 STRING,
VEHICLE_TYPE_CODE_2 STRING
);
weatherdata 表
创建 weatherdata 表,用于存储天气数据集中的数据。该表的字段同样经过裁剪,仅包含与该教程相关字段。
CREATE TABLE IF NOT EXISTS weatherdata (
DATE DATETIME,
NAME STRING,
HourlyDewPointTemperature STRING,
HourlyDryBulbTemperature STRING,
HourlyPrecipitation STRING,
HourlyPresentWeatherType STRING,
HourlyPressureChange STRING,
HourlyPressureTendency STRING,
HourlyRelativeHumidity STRING,
HourlySkyConditions STRING,
HourlyVisibility STRING,
HourlyWetBulbTemperature STRING,
HourlyWindDirection STRING,
HourlyWindGustSpeed STRING,
HourlyWindSpeed STRING
);
导入两个数据集
有很多方法可以将数据导入 StarRocks。对于本教程,最简单的方法是使用 curl 和 StarRocks Stream Load。
从您下载数据集的目录运行这些 curl 命令。
系统可能会提示您输入密码。您可能没有为 MySQL root 用户分配密码,因此只需按回车键。
curl 命令看起来很复杂,但在教程的最后有详细解释。现在,我们建议运行这些命令并运行一些 SQL 来分析数据,然后在最后阅读有关数据导入的详细信息。
纽约市碰撞数据 - 事故
curl --location-trusted -u root \
-T ./NYPD_Crash_Data.csv \
-H "label:crashdata-0" \
-H "column_separator:," \
-H "skip_header:1" \
-H "enclose:\"" \
-H "max_filter_ratio:1" \
-H "columns:tmp_CRASH_DATE, tmp_CRASH_TIME, CRASH_DATE=str_to_date(concat_ws(' ', tmp_CRASH_DATE, tmp_CRASH_TIME), '%m/%d/%Y %H:%i'),BOROUGH,ZIP_CODE,LATITUDE,LONGITUDE,LOCATION,ON_STREET_NAME,CROSS_STREET_NAME,OFF_STREET_NAME,NUMBER_OF_PERSONS_INJURED,NUMBER_OF_PERSONS_KILLED,NUMBER_OF_PEDESTRIANS_INJURED,NUMBER_OF_PEDESTRIANS_KILLED,NUMBER_OF_CYCLIST_INJURED,NUMBER_OF_CYCLIST_KILLED,NUMBER_OF_MOTORIST_INJURED,NUMBER_OF_MOTORIST_KILLED,CONTRIBUTING_FACTOR_VEHICLE_1,CONTRIBUTING_FACTOR_VEHICLE_2,CONTRIBUTING_FACTOR_VEHICLE_3,CONTRIBUTING_FACTOR_VEHICLE_4,CONTRIBUTING_FACTOR_VEHICLE_5,COLLISION_ID,VEHICLE_TYPE_CODE_1,VEHICLE_TYPE_CODE_2,VEHICLE_TYPE_CODE_3,VEHICLE_TYPE_CODE_4,VEHICLE_TYPE_CODE_5" \
-XPUT http://localhost:8030/api/quickstart/crashdata/_stream_load
这是上述命令的输出。第一个高亮部分显示了您应该看到的内容(OK 和除一行外的所有行都已插入)。有一行被过滤掉,因为它不包含正确数量的列。
Enter host password for user 'root':
{
"TxnId": 2,
"Label": "crashdata-0",
"Status": "Success",
"Message": "OK",
"NumberTotalRows": 423726,
"NumberLoadedRows": 423725,
"NumberFilteredRows": 1,
"NumberUnselectedRows": 0,
"LoadBytes": 96227746,
"LoadTimeMs": 1013,
"BeginTxnTimeMs": 21,
"StreamLoadPlanTimeMs": 63,
"ReadDataTimeMs": 563,
"WriteDataTimeMs": 870,
"CommitAndPublishTimeMs": 57,
"ErrorURL": "http://starrocks-cn:8040/api/_load_error_log?file=error_log_da41dd88276a7bfc_739087c94262ae9f"
}%
如果有错误,输出会提供一个 URL 来查看错误消息。错误消息还包含 Stream Load 任务分配到的后端节点(starrocks-cn)。由于您在 /etc/hosts 文件中添加了 starrocks-cn 的条目,因此您应该能够导航到它并读取错误消息。
展开本教程开发过程中看到的内容摘要:
在浏览器中读取错误消息
Error: Value count does not match column count. Expect 29, but got 32.
Column delimiter: 44,Row delimiter: 10.. Row: 09/06/2015,14:15,,,40.6722269,-74.0110059,"(40.6722269, -74.0110059)",,,"R/O 1 BEARD ST. ( IKEA'S
09/14/2015,5:30,BRONX,10473,40.814551,-73.8490955,"(40.814551, -73.8490955)",TORRY AVENUE ,NORTON AVENUE ,,0,0,0,0,0,0,0,0,Driver Inattention/Distraction,Unspecified,,,,3297457,PASSENGER VEHICLE,PASSENGER VEHICLE,,,
天气数据
以与加载碰撞数据相同的方式加载天气数据集。
curl --location-trusted -u root \
-T ./72505394728.csv \
-H "label:weather-0" \
-H "column_separator:," \
-H "skip_header:1" \
-H "enclose:\"" \
-H "max_filter_ratio:1" \
-H "columns: STATION, DATE, LATITUDE, LONGITUDE, ELEVATION, NAME, REPORT_TYPE, SOURCE, HourlyAltimeterSetting, HourlyDewPointTemperature, HourlyDryBulbTemperature, HourlyPrecipitation, HourlyPresentWeatherType, HourlyPressureChange, HourlyPressureTendency, HourlyRelativeHumidity, HourlySkyConditions, HourlySeaLevelPressure, HourlyStationPressure, HourlyVisibility, HourlyWetBulbTemperature, HourlyWindDirection, HourlyWindGustSpeed, HourlyWindSpeed, Sunrise, Sunset, DailyAverageDewPointTemperature, DailyAverageDryBulbTemperature, DailyAverageRelativeHumidity, DailyAverageSeaLevelPressure, DailyAverageStationPressure, DailyAverageWetBulbTemperature, DailyAverageWindSpeed, DailyCoolingDegreeDays, DailyDepartureFromNormalAverageTemperature, DailyHeatingDegreeDays, DailyMaximumDryBulbTemperature, DailyMinimumDryBulbTemperature, DailyPeakWindDirection, DailyPeakWindSpeed, DailyPrecipitation, DailySnowDepth, DailySnowfall, DailySustainedWindDirection, DailySustainedWindSpeed, DailyWeather, MonthlyAverageRH, MonthlyDaysWithGT001Precip, MonthlyDaysWithGT010Precip, MonthlyDaysWithGT32Temp, MonthlyDaysWithGT90Temp, MonthlyDaysWithLT0Temp, MonthlyDaysWithLT32Temp, MonthlyDepartureFromNormalAverageTemperature, MonthlyDepartureFromNormalCoolingDegreeDays, MonthlyDepartureFromNormalHeatingDegreeDays, MonthlyDepartureFromNormalMaximumTemperature, MonthlyDepartureFromNormalMinimumTemperature, MonthlyDepartureFromNormalPrecipitation, MonthlyDewpointTemperature, MonthlyGreatestPrecip, MonthlyGreatestPrecipDate, MonthlyGreatestSnowDepth, MonthlyGreatestSnowDepthDate, MonthlyGreatestSnowfall, MonthlyGreatestSnowfallDate, MonthlyMaxSeaLevelPressureValue, MonthlyMaxSeaLevelPressureValueDate, MonthlyMaxSeaLevelPressureValueTime, MonthlyMaximumTemperature, MonthlyMeanTemperature, MonthlyMinSeaLevelPressureValue, MonthlyMinSeaLevelPressureValueDate, MonthlyMinSeaLevelPressureValueTime, MonthlyMinimumTemperature, MonthlySeaLevelPressure, MonthlyStationPressure, MonthlyTotalLiquidPrecipitation, MonthlyTotalSnowfall, MonthlyWetBulb, AWND, CDSD, CLDD, DSNW, HDSD, HTDD, NormalsCoolingDegreeDay, NormalsHeatingDegreeDay, ShortDurationEndDate005, ShortDurationEndDate010, ShortDurationEndDate015, ShortDurationEndDate020, ShortDurationEndDate030, ShortDurationEndDate045, ShortDurationEndDate060, ShortDurationEndDate080, ShortDurationEndDate100, ShortDurationEndDate120, ShortDurationEndDate150, ShortDurationEndDate180, ShortDurationPrecipitationValue005, ShortDurationPrecipitationValue010, ShortDurationPrecipitationValue015, ShortDurationPrecipitationValue020, ShortDurationPrecipitationValue030, ShortDurationPrecipitationValue045, ShortDurationPrecipitationValue060, ShortDurationPrecipitationValue080, ShortDurationPrecipitationValue100, ShortDurationPrecipitationValue120, ShortDurationPrecipitationValue150, ShortDurationPrecipitationValue180, REM, BackupDirection, BackupDistance, BackupDistanceUnit, BackupElements, BackupElevation, BackupEquipment, BackupLatitude, BackupLongitude, BackupName, WindEquipmentChangeDate" \
-XPUT http://localhost:8030/api/quickstart/weatherdata/_stream_load
验证数据是否存储在 MinIO 中
打开 MinIO http://localhost:9001/browser/my-starrocks-bucket 并验证您在 my-starrocks-bucket/ 下是否有条目
my-starrocks-bucket/ 下的文件夹名称是在加载数据时生成的。您应该在 my-starrocks-bucket 下看到一个目录,然后在其下看到两个目录。在这些目录中,您会找到数据、元数据或模式条目。

回答一些问题
在 SQL 客户端中运行以下查询。
查询一:纽约市每小时交通事故数量
SELECT COUNT(*),
date_trunc("hour", crashdata.CRASH_DATE) AS Time
FROM crashdata
GROUP BY Time
ORDER BY Time ASC
LIMIT 200;
以下截取了部分输出数据:
| 14 | 2014-01-06 06:00:00 |
| 16 | 2014-01-06 07:00:00 |
| 43 | 2014-01-06 08:00:00 |
| 44 | 2014-01-06 09:00:00 |
| 21 | 2014-01-06 10:00:00 |
| 28 | 2014-01-06 11:00:00 |
| 34 | 2014-01-06 12:00:00 |
| 31 | 2014-01-06 13:00:00 |
| 35 | 2014-01-06 14:00:00 |
| 36 | 2014-01-06 15:00:00 |
| 33 | 2014-01-06 16:00:00 |
| 40 | 2014-01-06 17:00:00 |
| 35 | 2014-01-06 18:00:00 |
| 23 | 2014-01-06 19:00:00 |
| 16 | 2014-01-06 20:00:00 |
| 12 | 2014-01-06 21:00:00 |
| 17 | 2014-01-06 22:00:00 |
| 14 | 2014-01-06 23:00:00 |
| 10 | 2014-01-07 00:00:00 |
| 4 | 2014-01-07 01:00:00 |
| 1 | 2014-01-07 02:00:00 |
| 3 | 2014-01-07 03:00:00 |
| 2 | 2014-01-07 04:00:00 |
| 6 | 2014-01-07 06:00:00 |
| 16 | 2014-01-07 07:00:00 |
| 41 | 2014-01-07 08:00:00 |
| 37 | 2014-01-07 09:00:00 |
| 33 | 2014-01-07 10:00:00 |
从结果可以看出,1 月 6 日和 7 日(正常工作日的周一和周二)的早高峰(08:00 至 10:00)每小时约有 40 起事故,较其他时间时间段事故数量明显更多。��除此之外,晚高峰(17:00 左右)的事故数量也接近这个数字。
查询二:纽约市的平均气温
SELECT avg(HourlyDryBulbTemperature),
date_trunc("hour", weatherdata.DATE) AS Time
FROM weatherdata
GROUP BY Time
ORDER BY Time ASC
LIMIT 100;
以下截取了部分输出数据:
+-------------------------------+---------------------+
| avg(HourlyDryBulbTemperature) | Time |
+-------------------------------+---------------------+
| 25 | 2014-01-01 00:00:00 |
| 25 | 2014-01-01 01:00:00 |
| 24 | 2014-01-01 02:00:00 |
| 24 | 2014-01-01 03:00:00 |
| 24 | 2014-01-01 04:00:00 |
| 24 | 2014-01-01 05:00:00 |
| 25 | 2014-01-01 06:00:00 |
| 26 | 2014-01-01 07:00:00 |
查询三:能见度情况对驾驶安全的影响
为了解能见度情况对驾驶安全的影响,需要对两张表格的 DATETIME 列进行 JOIN,分析在能见度不佳的情况下(0 到 1.0 英里之间)时的交通事故数量。
SELECT COUNT(DISTINCT c.COLLISION_ID) AS Crashes,
truncate(avg(w.HourlyDryBulbTemperature), 1) AS Temp_F,
truncate(avg(w.HourlyVisibility), 2) AS Visibility,
max(w.HourlyPrecipitation) AS Precipitation,
date_format((date_trunc("hour", c.CRASH_DATE)), '%d %b %Y %H:%i') AS Hour
FROM crashdata c
LEFT JOIN weatherdata w
ON date_trunc("hour", c.CRASH_DATE)=date_trunc("hour", w.DATE)
WHERE w.HourlyVisibility BETWEEN 0.0 AND 1.0
GROUP BY Hour
ORDER BY Crashes DESC
LIMIT 100;
以下截取了部分输出数据:
+---------+--------+------------+---------------+-------------------+
| Crashes | Temp_F | Visibility | Precipitation | Hour |
+---------+--------+------------+---------------+-------------------+
| 129 | 32 | 0.25 | 0.12 | 03 Feb 2014 08:00 |
| 114 | 32 | 0.25 | 0.12 | 03 Feb 2014 09:00 |
| 104 | 23 | 0.33 | 0.03 | 09 Jan 2015 08:00 |
| 96 | 26.3 | 0.33 | 0.07 | 01 Mar 2015 14:00 |
| 95 | 26 | 0.37 | 0.12 | 01 Mar 2015 15:00 |
| 93 | 35 | 0.75 | 0.09 | 18 Jan 2015 09:00 |
| 92 | 31 | 0.25 | 0.12 | 03 Feb 2014 10:00 |
| 87 | 26.8 | 0.5 | 0.09 | 01 Mar 2015 16:00 |
| 85 | 55 | 0.75 | 0.20 | 23 Dec 2015 17:00 |
| 85 | 20 | 0.62 | 0.01 | 06 Jan 2015 11:00 |
| 83 | 19.6 | 0.41 | 0.04 | 05 Mar 2015 13:00 |
| 80 | 20 | 0.37 | 0.02 | 06 Jan 2015 10:00 |
| 76 | 26.5 | 0.25 | 0.06 | 05 Mar 2015 09:00 |
| 71 | 26 | 0.25 | 0.09 | 05 Mar 2015 10:00 |
| 71 | 24.2 | 0.25 | 0.04 | 05 Mar 2015 11:00 |
从以上结果可以得出,在能见度较低的一小时内的最高交通事故数量是 129。
当然,除了能见度因素外,还有其他因素需要考虑在内:
- 2014 年 2 月 3 日是星期一(工作日)
- 上午 8 点是早高峰时段
- 当时正在下雨(一小时内降水量为 0.12 英寸)
- 温度为 32 华氏度(水的冰点)
查询四:结冰情况对驾驶安全的影响
由于路面上水大约会在 40 华氏度时开始转变为冰,因此以下查询分析了温度区间为 0 到 40 华氏度的交通事故数量。
SELECT COUNT(DISTINCT c.COLLISION_ID) AS Crashes,
truncate(avg(w.HourlyDryBulbTemperature), 1) AS Temp_F,
truncate(avg(w.HourlyVisibility), 2) AS Visibility,
max(w.HourlyPrecipitation) AS Precipitation,
date_format((date_trunc("hour", c.CRASH_DATE)), '%d %b %Y %H:%i') AS Hour
FROM crashdata c
LEFT JOIN weatherdata w
ON date_trunc("hour", c.CRASH_DATE)=date_trunc("hour", w.DATE)
WHERE w.HourlyDryBulbTemperature BETWEEN 0.0 AND 40.5
GROUP BY Hour
ORDER BY Crashes DESC
LIMIT 100;
以下截取了部分输出数据:
+---------+--------+------------+---------------+-------------------+
| Crashes | Temp_F | Visibility | Precipitation | Hour |
+---------+--------+------------+---------------+-------------------+
| 192 | 34 | 1.5 | 0.09 | 18 Jan 2015 08:00 |
| 170 | 21 | NULL | | 21 Jan 2014 10:00 |
| 145 | 19 | NULL | | 21 Jan 2014 11:00 |
| 138 | 33.5 | 5 | 0.02 | 18 Jan 2015 07:00 |
| 137 | 21 | NULL | | 21 Jan 2014 09:00 |
| 129 | 32 | 0.25 | 0.12 | 03 Feb 2014 08:00 |
| 114 | 32 | 0.25 | 0.12 | 03 Feb 2014 09:00 |
| 104 | 23 | 0.7 | 0.04 | 09 Jan 2015 08:00 |
| 98 | 16 | 8 | 0.00 | 06 Mar 2015 08:00 |
| 96 | 26.3 | 0.33 | 0.07 | 01 Mar 2015 14:00 |
结果显示,2015 年 1 月 18 日发生了大量交通事故。虽然当天是星期天早晨,但根据 weather.com 显示,当天下了一场大雪,导致许多交通事故。
配置 StarRocks 以实现共享数据
现在您已经体验了使用 StarRocks 的共享数据,了解配置很重要。
CN 配置
此处使用的 CN 配置是默认配置,因为 CN 设计用于共享数据使用。默认配置如下所示。您无需进行任何更改。
sys_log_level = INFO
# ports for admin, web, heartbeat service
be_port = 9060
be_http_port = 8040
heartbeat_service_port = 9050
brpc_port = 8060
starlet_port = 9070
FE 配置
FE 配置与默认配置略有不同,因为 FE 必须配置为期望数据存储在对象存储中,而不是 BE 节点上的本地磁盘上。
docker-compose.yml 文件在 command 中生成 FE 配置。
# enable shared data, set storage type, set endpoint
run_mode = shared_data
cloud_native_storage_type = S3
此配置文件不包含 FE 的默认条目,仅显示共享数据配置。
非默认 FE 配置设置:
许多配置参数以 s3_ 为前缀。此前缀用于所有兼容 Amazon S3 的存储类型(例如:S3、GCS 和 MinIO)。使用 Azure Blob Storage 时,前缀为 azure_。
run_mode=shared_data
这启用了共享数据使用。
cloud_native_storage_type=S3
这指定了使用 S3 兼容存储还是 Azure Blob Storage。对于 MinIO,这始终是 S3。
CREATE storage volume 的详细信息
CREATE STORAGE VOLUME s3_volume
TYPE = S3
LOCATIONS = ("s3://my-starrocks-bucket/")
PROPERTIES
(
"enabled" = "true",
"aws.s3.endpoint" = "minio:9000",
"aws.s3.access_key" = "AAAAAAAAAAAAAAAAAAAA",
"aws.s3.secret_key" = "BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB",
"aws.s3.use_instance_profile" = "false",
"aws.s3.use_aws_sdk_default_behavior" = "false"
);
aws_s3_endpoint=minio:9000
MinIO 端点,包括端口号。
aws_s3_path=starrocks
bucket 名称。
aws_s3_access_key=AAAAAAAAAAAAAAAAAAAA
MinIO 访问密钥。
aws_s3_secret_key=BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB
MinIO 访问密钥密钥。
aws_s3_use_instance_profile=false
使用 MinIO 时使用访问密钥,因此 MinIO 不使用实例配置文件。
aws_s3_use_aws_sdk_default_behavior=false
使用 MinIO 时,此参数始终设置为 false。
配置 FQDN 模式
启动 FE 的命令也进行了更改。Docker Compose 文件中的 FE 服务命令添加了选项 --host_type FQDN。通过将 host_type 设置为 FQDN,Stream Load 任务被转发到 CN pod 的完全限定域名,而不是 IP 地址。这是因为 IP 地址在分配给 Docker 环境的范围内,通��常无法从主机机器访问。
这三个更改允许主机网络和 CN 之间的流量:
- 将
--host_type设置为FQDN - 将 CN 端口 8040 暴露给主机网络
- 为
starrocks-cn添加指向127.0.0.1的 hosts 文件条目
总结
在本教程中,您:
- 在 Docker 中部署了 StarRocks 和 Minio
- 创建了一个 MinIO 访问密钥
- 配置了一个使用 MinIO 的 StarRocks 存储卷
- 导入了纽约市提供的碰撞数据和 NOAA 提供的天气数据
- 使用 SQL JOIN 分析数据,发现低能见度或结冰街道上驾驶是个坏主意
还有更多内容需要学习;我们故意略过了 Stream Load 期间的数据转换。有关详细信息,请参阅下面 curl 命令的注释。
关于 curl 命令的注释
StarRocks 的 Stream Load 导入方式需要使用 curl 命令,涉及许多参数。以下仅列出此教程中需要使用的参数,其余参数请参考更多信息部分。
--location-trusted
此参数用于允许 curl 将认证凭据传输给任何重定向的 URL。
-u root
用于登录 StarRocks 的用户名。
-T filename
T 代表传输(Transfer),用于指定需要传输的文件名。
label:name-num
与此 Stream Load 作业关联的标签。标签必须唯一,因此如果多次运行作业,您可以添加一个数字保持递增。
column_separator:,
如果导入的文件使用单个 , 作为列分隔符,则设置如上所示。如果使用其他分隔符,则在此处设置该分隔符。常见分隔符包括 \t、, 和 |。
skip_header:1
某些 CSV 文件会在首行(Header)记录所有的列名,还有些会在第二行记录所有列的数据类型信息。如果 CSV 文件有一或两个 Header 行,需要将 skip_header 设置为 1 或 2。如果您使用的 CSV 没有 Header 行,请将其设置为 0。
enclose:\"
如果某些字段包含带有逗号的字符串,则需要用双引号括起该字段。本教程使用的示例数据集中,地理位置信息包含逗号,因此需将 enclose 设置为 \",其中 \ 用于转义 "。
max_filter_ratio:1
导入数据中允许出现错误行的比例。理想情况下,应将其设置为 0,即当导入的数据中有任意一行出现错误时,导入作业会失败。本教程中需要将其设置为 1,即在调试过程中,允许所有数据行出现错误。
columns:
此参数用于将 CSV 文件中的列映射到 StarRocks 表中的列。当前教程中使用的 CSV 文件中有大量的列,而 StarRocks 表中的列经过裁剪,仅保留部分列。未包含在表中的列在导入过程中都将被跳过。
本教程中的 columns: 参数中还包含数据转换逻辑。在 CSV 文件中经常会有不符合标准的日期和时间。以下是将日期和时间数据转换为 DATETIME 类型的逻辑:
数据转换
如下所示,数据集中的日期以 MM/DD/YYYY 为格式,时间以 HH:MI 为�格式。
08/05/2014,9:10,BRONX,10469,40.8733019,-73.8536375,"(40.8733019, -73.8536375)",
由于 StarRocks 中的 DATETIME 格式为 YYYY-MM-DD HH:MI:SS,因此需要转换数据集中的数据,将两列数据合并,并以空格分隔。则此处 columns: 参数应为:
-H "columns:tmp_CRASH_DATE, tmp_CRASH_TIME, CRASH_DATE=str_to_date(concat_ws(' ', tmp_CRASH_DATE, tmp_CRASH_TIME), '%m/%d/%Y %H:%i')
通过设置以上参数可实现以下目标:
- 将 CSV 文件的第一列内容分配给
tmp_CRASH_DATE列; - 将 CSV 文件的第二列内容分配给
tmp_CRASH_TIME列; - 通过
concat_ws()函数,使用空格将tmp_CRASH_DATE列和tmp_CRASH_TIME列连接在一起; - 通过
str_to_date()函数使用连接后的字符串生成 DATETIME 数据; - 将生成的 DATETIME 数据存储在列
CRASH_DATE中。
更多信息
机动车碰撞 - 事故 数据集由纽约市提供,受这些使用条款和隐私政策约束。
本地气候数据(LCD)由 NOAA 提供,附有此免责声明和此隐私政策。
