Hive catalog
Hive Catalog 是一种 External Catalog,自 2.3 版本开始支持。通过 Hive Catalog,您可以:
- 无需手动建表,通过 Hive Catalog 直接查询 Hive 内的数据。
- 通过 INSERT INTO 或异步物化视图(3.1 版本及以上)将 Hive 内的数据进行加工建模,并导入至 StarRocks。
- 在 StarRocks 侧创建或删除 Hive 库表,或通过 INSERT INTO 把 StarRocks 表数据写入到 Parquet 格式(3.2 版本及以上)、以及 ORC 或 Textfile 格式(3.3 版本及以上)的 Hive 表中。
为保证正常访问 Hive 内的数据,StarRocks 集群必须能够访问 Hive 集群的存储系统和元数据服务。目前 StarRocks 支持以下存储系统和元数据服务:
-
分布式文件系统 (HDFS) 或对象存储。当前支持的对象存储包括:AWS S3、Microsoft Azure Storage、Google GCS、其他兼容 S3 协议的对象存储(如阿里云 OSS、MinIO)。
-
元数据服务。当前支持的元数据服务包括:Hive Metastore(以下简称 HMS)、AWS Glue。
备注如果选择 AWS S3 作为存储系统,您可以选择 HMS 或 AWS Glue 作为元数据服务。如果选择其他存储系统,则只能选择 HMS 作为元数据服务。
使用说明
-
StarRocks 查询 Hive 内的数据时,支持 Parquet、ORC、Textfile、Avro、RCFile、SequenceFile 文件格式,其中:
- Parquet 文件支持 SNAPPY、LZ4、ZSTD、GZIP 和 NO_COMPRESSION 压缩格式。自 v3.1.5 起,Parquet 文件还支持 LZO 压缩格式。
- ORC 文件支持 ZLIB、SNAPPY、LZO、LZ4、ZSTD 和 NO_COMPRESSION 压缩格式。
- Textfile 文件从 v3.1.5 起支持 LZO 压缩格式。
-
StarRocks 查询 Hive 内的数据时,不支持 INTERVAL、BINARY 和 UNION 三种数据类型。此外,对于 Textfile 格式的 Hive 表,StarRocks 不支持 MAP、STRUCT 数据类型。
-
StarRocks 写入数据到 Hive 时,支持 Parquet(3.2 版本及以上)、以及 ORC 或 Textfile(3.3 版本及以上)文件格式,其中:
- Parquet 和 ORC 文件支持 NO_COMPRESSION、SNAPPY、LZ4、ZSTD 和 GZIP 压缩格式。
- Textfile 文件支持 NO_COMPRESSION 压缩格式。
您可以通过系统变量
connector_sink_compression_codec来设置写入到 Hive 表时的压缩算法。
准备工作
在创建 Hive Catalog 之前,请确保 StarRocks 集群能够正常访问 Hive 的文件存储及元数据服务。
AWS IAM
如果 Hive 使用 AWS S3 作为文件存储或使用 AWS Glue 作为元数据服务,您需要选择一种合适的认证鉴权方案,确保 StarRocks 集群可以访问相关的 AWS 云资源。
您可以选择如下认证鉴权方案:
- Instance Profile(推荐)
- Assumed Role
- IAM User
有关 StarRocks 访问 AWS 认证鉴权的详细内容,参见配置 AWS 认证方式 - 准备工作。
HDFS
如果使用 HDFS 作为文件存储,则需要在 StarRocks 集群中做如下配置:
- (可选)设置用于访问 HDFS 集群和 HMS 的用户名。 您可以在每个 FE 的 fe/conf/hadoop_env.sh 文件、以及每个 BE 的 be/conf/hadoop_env.sh 文件(或每个 CN 的 cn/conf/hadoop_env.sh 文件)最开头增加
export HADOOP_USER_NAME="<user_name>"来设置该用户名。配置完成后,需重启各个 FE 和 BE(或 CN)使配置生效。如果不设置该用户名,则默认使用 FE 和 BE(或 CN)进程的用户名进行访问。每个 StarRocks 集群仅支持配置一个用户名。 - 查询 Hive 数据时,StarRocks 集��群的 FE 和 BE(或 CN)会通过 HDFS 客户端访问 HDFS 集群。一般情况下,StarRocks 会按照默认配置来启动 HDFS 客户端,无需手动配置。但在以下场景中,需要进行手动配置:
- 如果 HDFS 集群开启了高可用(High Availability,简称为“HA”)模式,则需要将 HDFS 集群中的 hdfs-site.xml 文件放到每个 FE 的 $FE_HOME/conf 路径下、以及每个 BE 的 $BE_HOME/conf 路径(或每个 CN 的 $CN_HOME/conf 路径)下。
- 如果 HDFS 集群配置了 ViewFs,则需要将 HDFS 集群中的 core-site.xml 文件放到每个 FE 的 $FE_HOME/conf 路径下、以及每个 BE 的 $BE_HOME/conf 路径(或每个 CN 的 $CN_HOME/conf 路径)下。
如果查询时因为域名无法识别 (Unknown Host) 而发生访问失败,您需要将 HDFS 集群中各节点的主机名及 IP 地址之间的映射关系配置到 /etc/hosts 路径中。
Kerberos 认证
如果 HDFS 集群或 HMS 开启了 Kerberos 认证,则需要在 StarRocks 集群中做如下配置:
- 在每个 FE 和 每个 BE(或 CN)上执行
kinit -kt keytab_path principal命令,从 Key Distribution Center (KDC) 获取到 Ticket Granting Ticket (TGT)。执行命令的用户必须拥有访问 HMS 和 HDFS 的权限。注意,使用该命令访问 KDC 具有时效性,因此需要使用 cron 定期执行该命令。 - 在每个 FE 的 $FE_HOME/conf/fe.conf 文件和每个 BE 的 $BE_HOME/conf/be.conf 文件(或每个 CN 的 $CN_HOME/conf/cn.conf 文件)中添加
JAVA_OPTS="-Djava.security.krb5.conf=/etc/krb5.conf"。其中,/etc/krb5.conf是 krb5.conf 文件的路径,可以根据文件的实际路径进行修改。
创建 Hive Catalog
语法
CREATE EXTERNAL CATALOG <catalog_name>
[COMMENT <comment>]
PROPERTIES
(
"type" = "hive",
GeneralParams,
MetastoreParams,
StorageCredentialParams,
MetadataUpdateParams
)
参数说明
catalog_name
Hive Catalog 的名称。命名要求如下:
- 必须由字母 (a-z 或 A-Z)、数字 (0-9) 或下划线 (_) 组成,且只能以字母开头。
- 总长度不能超过 1023 个字符。
- Catalog 名称大小写敏感。
comment
Hive Catalog 的描述。此参数为可选。
type
数据源的类型。设置为 hive。
GeneralParams
指定通用设置的一组参数。
GeneralParams 包含如下参数。
| 参数 | 是否必须 | 说明 |
|---|---|---|
| enable_recursive_listing | �否 | 指定 StarRocks 是否递归读取表或者分区目录(包括子目录)中文件的数据。取值范围:true 和 false。默认值:true。取值为 true 表示递归遍历,取值为 false 表示只读取表或者分区目录当前层级中文件的数据。 |
MetastoreParams
StarRocks 访问 Hive 集群元数据服务的相关参数配置。
Hive metastore
如果选择 HMS 作为 Hive 集群的元数据服务,请按如下配置 MetastoreParams:
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "<hive_metastore_uri>"
在查询 Hive 数据之前,必须将所有 HMS 节点的主机名及 IP 地址之间的映射关系添加到 /etc/hosts 路径。否则,发起查询时,StarRocks 可能无法访问 HMS。
MetastoreParams 包含如下参数。
| 参数 | 是否必须 | 说明 |
|---|---|---|
| hive.metastore.type | 是 | Hive 集群所使用的元数据服务的类型。设置为 hive。 |
| hive.metastore.uris | 是 | HMS 的 URI。格式:thrift://<HMS IP 地址>:<HMS 端口号>。如果您的 HMS 开启了高可用模式,此处可以填写多个 HMS 地址并用逗号分隔,例如: "thrift://<HMS IP 地址 1>:<HMS 端口号 1>,thrift://<HMS IP 地址 2>:<HMS 端口号 2>,thrift://<HMS IP 地址 3>:<HMS 端口号 3>"。 |
AWS Glue
如果选择 AWS Glue 作为 Hive 集群的元数据服务(只有使用 AWS S3 作为存储系统时支持),请按如下配置 MetastoreParams:
-
基于 Instance Profile 进行认证和鉴权
"hive.metastore.type" = "glue",
"aws.glue.use_instance_profile" = "true",
"aws.glue.region" = "<aws_glue_region>" -
基于 Assumed Role 进行认证和鉴权
"hive.metastore.type" = "glue",
"aws.glue.use_instance_profile" = "true",
"aws.glue.iam_role_arn" = "<iam_role_arn>",
"aws.glue.region" = "<aws_glue_region>" -
基于 IAM User 进行认证和鉴权
"hive.metastore.type" = "glue",
"aws.glue.use_instance_profile" = "false",
"aws.glue.access_key" = "<iam_user_access_key>",
"aws.glue.secret_key" = "<iam_user_secret_key>",
"aws.glue.region" = "<aws_s3_region>"
MetastoreParams 包含如下参数。
| 参数 | 是否必须 | 说明 |
|---|---|---|
| hive.metastore.type | 是 | Hive 集群所使用的元数据服务的类型。设置为 glue。 |
| aws.glue.use_instance_profile | 是 | 指定是否开启 Instance Profile 和 Assumed Role 两种鉴权方式。取值范围:true 和 false。默认值:false。 |
| aws.glue.iam_role_arn | 否 | 有权限访问 AWS Glue Data Catalog 的 IAM Role 的 ARN。采用 Assumed Role 鉴权方式访问 AWS Glue 时,必须指定此参数。 |
| aws.glue.region | 是 | AWS Glue Data Catalog 所在的地域。示例:us-west-1。 |
| aws.glue.access_key | 否 | IAM User 的 Access Key。采用 IAM User 鉴权方式访问 AWS Glue 时,必须指定此参数。 |
| aws.glue.secret_key | 否 | IAM User 的 Secret Key。采用 IAM User 鉴权方式访问 AWS Glue 时,必��须指定此参数。 |
| hive.metastore.glue.catalogid | 否 | 要使用的 AWS Glue Data Catalog 的 ID。未指定时,使用当前 AWS 账户的 Data Catalog。当需要访问其他 AWS 账户中的 Glue Data Catalog(跨账户访问)时,必须指定此参数。 |
有关如何选择用于访问 AWS Glue 的鉴权方式、以及如何在 AWS IAM 控制台配置访问控制策略,参见访问 AWS Glue 的认证参数。
StorageCredentialParams
StarRocks 访问 Hive 集群文件存储的相关参数配置。
如果您使用 HDFS 作为存储系统,则不需要配置 StorageCredentialParams。
如果您使用 AWS S3、其他兼容 S3 协议的对象存储、Microsoft Azure Storage、 或 GCS,则必须配置 StorageCredentialParams。
AWS S3
如果选择 AWS S3 作为 Hive 集群的文件存储,请按如下配置 StorageCredentialParams:
-
基于 Instance Profile 进行认证和鉴权
"aws.s3.use_instance_profile" = "true",
"aws.s3.region" = "<aws_s3_region>" -
基于 Assumed Role 进行认证和鉴权
"aws.s3.use_instance_profile" = "true",
"aws.s3.iam_role_arn" = "<iam_role_arn>",
"aws.s3.region" = "<aws_s3_region>" -
基于 IAM User 进行认证和鉴权
"aws.s3.use_instance_profile" = "false",
"aws.s3.access_key" = "<iam_user_access_key>",
"aws.s3.secret_key" = "<iam_user_secret_key>",
"aws.s3.region" = "<aws_s3_region>"
StorageCredentialParams 包含如下参数。
| 参数 | 是否必须 | 说明 |
|---|---|---|
| aws.s3.use_instance_profile | 是 | 指定是否开启 Instance Profile 和 Assumed Role 两种鉴权方式。取值范围:true 和 false。默认值:false。 |
| aws.s3.iam_role_arn | 否 | 有权限访问 AWS S3 Bucket 的 IAM Role 的 ARN。采用 Assumed Role 鉴权方式访问 AWS S3 时,必须指定此参数。 |
| aws.s3.region | 是 | AWS S3 Bucket 所在的地域。示例:us-west-1。 |
| aws.s3.access_key | 否 | IAM User 的 Access Key。采用 IAM User 鉴权方式访问 AWS S3 时,必须指定此参数。 |
| aws.s3.secret_key | 否 | IAM User 的 Secret Key。采用 IAM User 鉴权方式访问 AWS S3 时,必须指定此参数。 |
有关如何选择用于访问 AWS S3 的鉴权方式、以及如何在 AWS IAM 控制台配置访问控制策略,参见访问 AWS S3 的认证参数。
阿里云 OSS
如果选择阿里云 OSS 作为 Hive 集群的文件存储,需要在 StorageCredentialParams 中配置如下认证参数:
"aliyun.oss.access_key" = "<user_access_key>",
"aliyun.oss.secret_key" = "<user_secret_key>",
"aliyun.oss.endpoint" = "<oss_endpoint>"
| 参数 | 是否必须 | 说明 |
|---|---|---|
| aliyun.oss.endpoint | 是 | 阿里云 OSS Endpoint, 如 oss-cn-beijing.aliyuncs.com,您可根据 Endpoint 与地域的对应关系进行查找,请参见 访问域名和数据中心。 |
| aliyun.oss.access_key | 是 | 指定阿里云账号或 RAM 用户的 AccessKey ID,获取方式,请参见 获取 AccessKey。 |
| aliyun.oss.secret_key | 是 | 指定阿里云账号或 RAM 用户的 AccessKey Secret,获取方式,请参见 获取 AccessKey。 |
兼容 S3 协议的对象存储
Hive Catalog 从 2.5 版本起支持兼容 S3 协议的对象存储。
如果选择兼容 S3 协议的对象存储(如 MinIO)作为 Hive 集群的文件存储,请按如下配置 StorageCredentialParams:
"aws.s3.enable_ssl" = "false",
"aws.s3.enable_path_style_access" = "true",
"aws.s3.endpoint" = "<s3_endpoint>",
"aws.s3.access_key" = "<iam_user_access_key>",
"aws.s3.secret_key" = "<iam_user_secret_key>"
StorageCredentialParams 包含如下参数。
| 参数 | 是否必须 | 说明 |
|---|---|---|
| aws.s3.enable_ssl | Yes | 是否开启 SSL 连接。 取值范围: true 和 false。默认值:true。 |
| aws.s3.enable_path_style_access | Yes | 是否开启路径类型访问 (Path-Style Access)。 取值范围: true 和 false。默认值:false。对于 MinIO,必须设置为 true。路径类型 URL 使用如下格式: https://s3.<region_code>.amazonaws.com/<bucket_name>/<key_name>。例如,如果您在美国西部(俄勒冈)区域中创建一个名为 DOC-EXAMPLE-BUCKET1 的存储桶,并希望访问该存储桶中的 alice.jpg 对象,则可使用以下路径类型 URL:https://s3.us-west-2.amazonaws.com/DOC-EXAMPLE-BUCKET1/alice.jpg。 |
| aws.s3.endpoint | Yes | 用于访问兼容 S3 协议的对象存储的 Endpoint。 |
| aws.s3.access_key | Yes | IAM User 的 Access Key。 |
| aws.s3.secret_key | Yes | IAM User 的 Secret Key。 |
Microsoft Azure Storage
Hive Catalog 从 3.0 版本起支持 Microsoft Azure Storage。
Azure Blob Storage
如果选择 Blob Storage 作为 Hive 集群的文件存储,请按如下配置 StorageCredentialParams:
-
基于 Shared Key 进行认证和鉴权
"azure.blob.storage_account" = "<storage_account_name>",
"azure.blob.shared_key" = "<storage_account_shared_key>"StorageCredentialParams包含如下参数。参数 是否必须 说明 azure.blob.storage_account 是 Blob Storage 账号的用户名。 azure.blob.shared_key 是 Blob Storage 账号的 Shared Key。 -
基于 SAS Token 进行认证和鉴权
"azure.blob.storage_account" = "<storage_account_name>",
"azure.blob.container" = "<container_name>",
"azure.blob.sas_token" = "<storage_account_SAS_token>"StorageCredentialParams包含如下参数。参数 是否必须 说明 azure.blob.storage_account 是 Blob Storage 账号的用户名。 azure.blob.container 是 数据所在 Blob 容器的名称。 azure.blob.sas_token 是 用于访问 Blob Storage 账号的 SAS Token。
Azure Data Lake Storage Gen2
如果选择 Data Lake Storage Gen2 作为 Hive 集群的文件存储,请按如下配置 StorageCredentialParams:
-
基于 Managed Identity 进行认证和鉴权
"azure.adls2.oauth2_use_managed_identity" = "true",
"azure.adls2.oauth2_tenant_id" = "<service_principal_tenant_id>",
"azure.adls2.oauth2_client_id" = "<service_client_id>"StorageCredentialParams包含如下参数。参数 是否必须 说明 azure.adls2.oauth2_use_managed_identity 是 指定是否开启 Managed Identity 鉴权方式。设置为 true。azure.adls2.oauth2_tenant_id 是 数据所属 Tenant 的 ID。 azure.adls2.oauth2_client_id 是 Managed Identity 的 Client (Application) ID。 -
基于 Shared Key 进行认证和鉴权
"azure.adls2.storage_account" = "<storage_account_name>",
"azure.adls2.shared_key" = "<storage_account_shared_key>"StorageCredentialParams包含如下参数。参数 是否必须 说明 azure.adls2.storage_account 是 Data Lake Storage Gen2 账号的用户名。 azure.adls2.shared_key 是 Data Lake Storage Gen2 账号的 Shared Key。 -
基于 Service Principal 进行认证和鉴权
"azure.adls2.oauth2_client_id" = "<service_client_id>",
"azure.adls2.oauth2_client_secret" = "<service_principal_client_secret>",
"azure.adls2.oauth2_client_endpoint" = "<service_principal_client_endpoint>"StorageCredentialParams包含如下参数。参数 是否必须 说明 azure.adls2.oauth2_client_id 是 Service Principal 的 Client (Application) ID。 azure.adls2.oauth2_client_secret 是 新建的 Client (Application) Secret。 azure.adls2.oauth2_client_endpoint 是 Service Principal 或 Application 的 OAuth 2.0 Token Endpoint (v1)。
Azure Data Lake Storage Gen1
如果选择 Data Lake Storage Gen1 作为 Hive 集群的文件存储,请按如下配置 StorageCredentialParams:
-
基于 Managed Service Identity 进行认证和鉴权
"azure.adls1.use_managed_service_identity" = "true"StorageCredentialParams包含如下参数。参数 是否必须 说明 azure.adls1.use_managed_service_identity 是 指定是否开启 Managed Service Identity 鉴权方式。设置为 true。 -
基于 Service Principal 进行认证和鉴权
"azure.adls1.oauth2_client_id" = "<application_client_id>",
"azure.adls1.oauth2_credential" = "<application_client_credential>",
"azure.adls1.oauth2_endpoint" = "<OAuth_2.0_authorization_endpoint_v2>"StorageCredentialParams包含如下参数。Parameter Required Description azure.adls1.oauth2_client_id 是 Service Principal 的 Client (Application) ID。 azure.adls1.oauth2_credential 是 新建的 Client (Application) Secret。 azure.adls1.oauth2_endpoint 是 Service Principal 或 Application 的 OAuth 2.0 Token Endpoint (v1)。
Google GCS
Hive Catalog 从 3.0 版本起支持 Google GCS。
如果选择 Google GCS 作为 Hive 集群的文件存储,请按如下配置 StorageCredentialParams:
-
基于 VM 进行认证和鉴权
"gcp.gcs.use_compute_engine_service_account" = "true"StorageCredentialParams包含如下参数。参数 默认值 取值样例 说明 gcp.gcs.use_compute_engine_service_account false true 是否直接使用 Compute Engine 上面绑定的 Service Account。 -
基于 Service Account 进行认证和鉴权
"gcp.gcs.service_account_email" = "<google_service_account_email>",
"gcp.gcs.service_account_private_key_id" = "<google_service_private_key_id>",
"gcp.gcs.service_account_private_key" = "<google_service_private_key>"StorageCredentialParams包含如下参数。参数 默认值 取值样例 说明 gcp.gcs.service_account_email "" "user@hello.iam.gserviceaccount.com" 创建 Service Account 时生成的 JSON 文件中的 Email。 gcp.gcs.service_account_private_key_id "" "61d257bd8479547cb3e04f0b9b6b9ca07af3b7ea" 创建 Service Account 时生成的 JSON 文件中的 Private Key ID。 gcp.gcs.service_account_private_key "" "-----BEGIN PRIVATE KEY----xxxx-----END PRIVATE KEY-----\n" 创建 Service Account 时生成的 JSON 文件中的 Private Key。 -
基于 Impersonation 进行认证和鉴权
-
使用 VM 实例模拟 Service Account
"gcp.gcs.use_compute_engine_service_account" = "true",
"gcp.gcs.impersonation_service_account" = "<assumed_google_service_account_email>"StorageCredentialParams包含如下参数。参数 默认值 取值样例 说明 gcp.gcs.use_compute_engine_service_account false true 是否直接使用 Compute Engine 上面绑定的 Service Account。 gcp.gcs.impersonation_service_account "" "hello" 需要模拟的目标 Service Account。 -
使用一个 Service Account(暂时命名为“Meta Service Account”)模拟另一个 Service Account(暂时命名为“Data Service Account”)
"gcp.gcs.service_account_email" = "<google_service_account_email>",
"gcp.gcs.service_account_private_key_id" = "<meta_google_service_account_email>",
"gcp.gcs.service_account_private_key" = "<meta_google_service_account_email>",
"gcp.gcs.impersonation_service_account" = "<data_google_service_account_email>"StorageCredentialParams包含如下参数。参数 默认值 取值样例 说明 gcp.gcs.service_account_email "" "user@hello.iam.gserviceaccount.com" 创建 Meta Service Account 时生成的 JSON 文件中的 Email。 gcp.gcs.service_account_private_key_id "" "61d257bd8479547cb3e04f0b9b6b9ca07af3b7ea" 创建 Meta Service Account 时生成的 JSON 文件中的 Private Key ID。 gcp.gcs.service_account_private_key "" "-----BEGIN PRIVATE KEY----xxxx-----END PRIVATE KEY-----\n" 创建 Meta Service Account 时生成的 JSON 文件中的 Private Key。 gcp.gcs.impersonation_service_account "" "hello" 需要模拟的目标 Data Service Account。
-
MetadataUpdateParams
指定缓存元数据更新策略的一组参数。StarRocks 根据该策略更新缓存的 Hive 元数据。此组参数为可选。
StarRocks 默认采用自动异步更新策略,开箱即用。因此,一般情况下,您可以忽略 MetadataUpdateParams,无需对其中的策略参数进行调优。
如果 Hive 数据更新频率较高,那么您可以对这些参数进行调优,从而优化自动异步更新策略的性能。
| 参数 | 是否必须 | 说明 |
|---|---|---|
| enable_metastore_cache | 否 | 指定 StarRocks 是否缓存 Hive 表的元数据。取值范围:true 和 false。默认值:true。取值为 true 表示开启缓存,取值为 false 表示关闭缓存。 |
| enable_remote_file_cache | 否 | 指定 StarRocks 是否缓存 Hive 表或分区的数据文件的元数据。取值范围:true 和 false。默认值:true。取值为 true 表示开启缓存,取值为 false 表示关闭缓存。 |
| metastore_cache_refresh_interval_sec | 否 | StarRocks 异步更新缓存的 Hive 表或分区的元数据的时间间隔。单位:秒。默认值:60,即一分钟。自 v3.3.0 起,该属性默认值由 7200 变更为 60。 |
| remote_file_cache_refresh_interval_sec | 否 | StarRocks 异步更新缓存的 Hive 表或分区的数据文件的元数据的时间间隔。单位:秒。默认值:60。 |
| metastore_cache_ttl_sec | 否 | StarRocks 自动淘汰缓存的 Hive 表或分区的元数据的时间间隔。单位:秒。默认值:86400,即 24 小时。 |
| remote_file_cache_ttl_sec | 否 | StarRocks 自动淘汰缓存的 Hive 表或分区的数据文件的元数据的时间间隔。单位:秒。默认值:129600,即 36 小时。 |
| enable_cache_list_names | 否 | 指定 StarRocks 是否缓存 Hive Partition Names。取值范围:true 和 false。默认值:true。取值为 true 表示开启缓存,取值为 false 表示关闭缓存。 |
示例
以下示例创建了一个名为 hive_catalog_hms 或 hive_catalog_glue 的 Hive Catalog,用于查询 Hive 集群里的数据。
HDFS
使用 HDFS 作为存储时,可以按如下创建 Hive Catalog:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083"
);
AWS S3
如果基于 Instance Profile 进行鉴权和认证
-
如果 Hive 集群使用 HMS 作为元数据服务,可以按如下创建 Hive Catalog:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"aws.s3.use_instance_profile" = "true",
"aws.s3.region" = "us-west-2"
); -
如果 Amazon EMR Hive 集群使用 AWS Glue 作为元数据服务,可以按如下创建 Hive Catalog:
CREATE EXTERNAL CATALOG hive_catalog_glue
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "glue",
"aws.glue.use_instance_profile" = "true",
"aws.glue.region" = "us-west-2",
"aws.s3.use_instance_profile" = "true",
"aws.s3.region" = "us-west-2"
);
如果基于 Assumed Role 进行鉴权和认证
-
如果 Hive 集群使用 HMS 作为元数据服务,可以按如下创建 Hive Catalog:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"aws.s3.use_instance_profile" = "true",
"aws.s3.iam_role_arn" = "arn:aws:iam::081976408565:role/test_s3_role",
"aws.s3.region" = "us-west-2"
); -
如果 Amazon EMR Hive 集群使用 AWS Glue 作为元数据服务,可以按如下创建 Hive Catalog:
CREATE EXTERNAL CATALOG hive_catalog_glue
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "glue",
"aws.glue.use_instance_profile" = "true",
"aws.glue.iam_role_arn" = "arn:aws:iam::081976408565:role/test_glue_role",
"aws.glue.region" = "us-west-2",
"aws.s3.use_instance_profile" = "true",
"aws.s3.iam_role_arn" = "arn:aws:iam::081976408565:role/test_s3_role",
"aws.s3.region" = "us-west-2"
);
如果基于 IAM User 进行鉴权和认证
-
如果 Hive 集群使用 HMS 作为元数据服务,可以按如下创建 Hive Catalog:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"aws.s3.use_instance_profile" = "false",
"aws.s3.access_key" = "<iam_user_access_key>",
"aws.s3.secret_key" = "<iam_user_access_key>",
"aws.s3.region" = "us-west-2"
); -
如果 Amazon EMR Hive 集群使用 AWS Glue 作为元数据服务,可以按如下创建 Hive Catalog:
CREATE EXTERNAL CATALOG hive_catalog_glue
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "glue",
"aws.glue.use_instance_profile" = "false",
"aws.glue.access_key" = "<iam_user_access_key>",
"aws.glue.secret_key" = "<iam_user_secret_key>",
"aws.glue.region" = "us-west-2",
"aws.s3.use_instance_profile" = "false",
"aws.s3.access_key" = "<iam_user_access_key>",
"aws.s3.secret_key" = "<iam_user_secret_key>",
"aws.s3.region" = "us-west-2"
);
兼容 S3 协议的对象存储
以 MinIO 为例,可以按如下创建 Hive Catalog:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"aws.s3.enable_ssl" = "true",
"aws.s3.enable_path_style_access" = "true",
"aws.s3.endpoint" = "<s3_endpoint>",
"aws.s3.access_key" = "<iam_user_access_key>",
"aws.s3.secret_key" = "<iam_user_secret_key>"
);
Microsoft Azure Storage
Azure Blob Storage
-
如果基于 Shared Key 进行认证和鉴权,可以按如下创建 Hive Catalog:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"azure.blob.storage_account" = "<blob_storage_account_name>",
"azure.blob.shared_key" = "<blob_storage_account_shared_key>"
); -
如果基于 SAS Token 进行认证和鉴权,可以按如下创建 Hive Catalog:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"azure.blob.storage_account" = "<blob_storage_account_name>",
"azure.blob.container" = "<blob_container_name>",
"azure.blob.sas_token" = "<blob_storage_account_SAS_token>"
);
Azure Data Lake Storage Gen1
-
如果基于 Managed Service Identity 进行认证和鉴权,可以按如下创建 Hive Catalog:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"azure.adls1.use_managed_service_identity" = "true"
); -
如果基于 Service Principal 进行认证和鉴权,可以按如下创建 Hive Catalog:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"azure.adls1.oauth2_client_id" = "<application_client_id>",
"azure.adls1.oauth2_credential" = "<application_client_credential>",
"azure.adls1.oauth2_endpoint" = "<OAuth_2.0_authorization_endpoint_v2>"
);
Azure Data Lake Storage Gen2
-
如果基于 Managed Identity 进行认证和鉴权,可以按如下创建 Hive Catalog:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"azure.adls2.oauth2_use_managed_identity" = "true",
"azure.adls2.oauth2_tenant_id" = "<service_principal_tenant_id>",
"azure.adls2.oauth2_client_id" = "<service_client_id>"
); -
如果基于 Shared Key 进行认证和鉴权,可以按如下创建 Hive Catalog:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"azure.adls2.storage_account" = "<storage_account_name>",
"azure.adls2.shared_key" = "<shared_key>"
); -
如果基于 Service Principal 进行认证和鉴权,可以按如下创建 Hive Catalog:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"azure.adls2.oauth2_client_id" = "<service_client_id>",
"azure.adls2.oauth2_client_secret" = "<service_principal_client_secret>",
"azure.adls2.oauth2_client_endpoint" = "<service_principal_client_endpoint>"
);
Google GCS
-
如果基于 VM 进行认证和鉴权,可以按如下创建 Hive Catalog:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"gcp.gcs.use_compute_engine_service_account" = "true"
); -
如果基于 Service Account 进行认证和鉴权,可以按如下创建 Hive Catalog:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"gcp.gcs.service_account_email" = "<google_service_account_email>",
"gcp.gcs.service_account_private_key_id" = "<google_service_private_key_id>",
"gcp.gcs.service_account_private_key" = "<google_service_private_key>"
); -
如果基于 Impersonation 进行认证和鉴权
-
使用 VM 实例模拟 Service Account,可以按如下创建 Hive Catalog:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"gcp.gcs.use_compute_engine_service_account" = "true",
"gcp.gcs.impersonation_service_account" = "<assumed_google_service_account_email>"
); -
使用一个 Service Account 模拟另一个 Service Account,可以按如下创建 Hive Catalog:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"gcp.gcs.service_account_email" = "<google_service_account_email>",
"gcp.gcs.service_account_private_key_id" = "<meta_google_service_account_email>",
"gcp.gcs.service_account_private_key" = "<meta_google_service_account_email>",
"gcp.gcs.impersonation_service_account" = "<data_google_service_account_email>"
);
-
查看 Hive Catalog
您可以通过 SHOW CATALOGS 查询当前所在 StarRocks 集群里所有 Catalog:
SHOW CATALOGS;
您也可以通过 SHOW CREATE CATALOG 查询某个 External Catalog 的创建语句。例如,通过如下命令查询 Hive Catalog hive_catalog_glue 的创建语句:
SHOW CREATE CATALOG hive_catalog_glue;
切换 Hive Catalog 和数据库
您可以通过如下方法切换至目标 Hive Catalog 和数据库:
-
先通过 SET CATALOG 指定当前会话生效的 Hive Catalog,然后再通过 USE 指定数据库:
-- 切换当前会话生效的 Catalog:
SET CATALOG <catalog_name>
-- 指定当前会话生效的数据库:
USE <db_name> -
通过 USE 直接将会话切换到目标 Hive Catalog 下的指定数据库:
USE <catalog_name>.<db_name>
删除 Hive Catalog
您可以通过 DROP CATALOG 删除某个 External Catalog。
例如,通过如下命令删除 Hive Catalog hive_catalog_glue:
DROP Catalog hive_catalog_glue;
查看 Hive 表结构
您可以通过如下方法查看 Hive 表的表结构:
-
查看表结构
DESC[RIBE] <catalog_name>.<database_name>.<table_name> -
从 CREATE 命令查看表结构和表文件存放位置
SHOW CREATE TABLE <catalog_name>.<database_name>.<table_name>
查询 Hive 表数据
-
通过 SHOW DATABASES 查看指定 Catalog 所属的 Hive 集群中的数据库:
SHOW DATABASES FROM <catalog_name> -
通过 SELECT 查询目标数据库中的目标表:
SELECT count(*) FROM <table_name> LIMIT 10
导入 Hive 数据
假设有一个 OLAP 表,表名为 olap_tbl。您可以这样来转换该表中的数据,并把数据导入到 StarRocks 中:
INSERT INTO default_catalog.olap_db.olap_tbl SELECT * FROM hive_table
赋予 Hive 表和视图的权限
您可以通过 GRANT 来赋予角色某个 Hive Catalog 内所有表和视图的查询权限。命令语法如下:
GRANT SELECT ON ALL TABLES IN ALL DATABASES TO ROLE <role_name>
例如,通过如下命令创建角色 hive_role_table,切换至 Hive Catalog hive_catalog,然后把 hive_catalog 内所有表和视图的查询权限都赋予 hive_role_table:
-- 创建角色 hive_role_table。
CREATE ROLE hive_role_table;
-- 切换到数据目录 hive_catalog。
SET CATALOG hive_catalog;
-- 把 hive_catalog 内所有表和视图的查询权限赋予 hive_role_table。
GRANT SELECT ON ALL TABLES IN ALL DATABASES TO ROLE hive_role_table;
创建 Hive 数据库
同 StarRocks 内部数据目录 (Internal Catalog) 一致,如果您拥有 Hive Catalog 的 CREATE DATABASE 权限,那么您可以使用 CREATE DATABASE 在该 Hive Catalog 内创建数据库。本功能自 3.2 版本起开始支持。
切换至目标 Hive Catalog,然后通过如下语句创建 Hive 数据库:
CREATE DATABASE <database_name>
[PROPERTIES ("location" = "<prefix>://<path_to_database>/<database_name.db>")]
location 参数用于指定数据库所在的文件路径,支持 HDFS 和对象存储:
- 选择 HMS 作为元数据服务时,如果您在创建数据库时不指定
location,那么系统会使用 HMS 默认的<warehouse_location>/<database_name.db>作为文件路径。 - 选择 AWS Glue 作为元数据服务时,
location参数没有默认值,因此您在创建数据库时必须指定该参数。
prefix 根据存储系统的不同而不同:
| 存储系统 | Prefix 取值 |
|---|---|
| HDFS | hdfs |
| Google GCS | gs |
| Azure Blob Storage |
|
| Azure Data Lake Storage Gen1 | adl |
| Azure Data Lake Storage Gen2 |
|
| 阿里云 OSS | oss |
| 腾讯云 COS | cosn |
| 华为云 OBS | obs |
| AWS S3 及其他兼容 S3 的存储(如 MinIO) | s3 |
删除 Hive 数据库
同 StarRocks 内部数据库一致,如果您拥有 Hive 数据库的 DROP 权限,那么您可以使用 DROP DATABASE 来删除该 Hive 数据库。本功能自 3.2 版本起开始支持。仅支持删除空数据库。
删除数据库操作并不会将 HDFS 或对象存储上的对应文件路径删除。
切换至目标 Hive Catalog,然后通过如下语句删除 Hive 数据库:
DROP DATABASE <database_name>
创建 Hive 表
同 StarRocks 内部数据库一致,如果您拥有 Hive 数据库的 CREATE TABLE 权限,那么您可以使用 CREATE TABLE、CREATE TABLE AS SELECT (CTAS)、或 [CREATE TABL../../sql-reference/sql-statements/table_bucket_part_index/CREATE_TABLE_LIKE.md_LIKE.md) 在该 Hive 数据库下创建 Managed Table。
本功能自 3.2 版本起开始支持,彼时只支持创建 Parquet 格式的 Hive 表。自 3.3 版本起,该功能还支持创建 ORC 及 Textfile 格式的 Hive 表。
切换至目标 Hive Catalog 和数据库。然后通过如下语法创建 Hive 的 Managed Table:
语法
CREATE TABLE [IF NOT EXISTS] [database.]table_name
(column_definition1[, column_definition2, ...
partition_column_definition1,partition_column_definition2...])
[partition_desc]
[PROPERTIES ("key" = "value", ...)]
[AS SELECT query]
[LIKE [database.]<source_table_name>]
参数说明
column_definition
column_definition 语法定义如下:
col_name col_type [COMMENT 'comment']
参数说明:
| 参数 | 说明 |
|---|---|
| col_name | 列名称。 |
| col_type | 列数据类型。当前支持如下数据类型:TINYINT、SMALLINT、INT、BIGINT、FLOAT、DOUBLE、DECIMAL、DATE、DATETIME、CHAR、VARCHAR[(length)]、ARRAY、MAP、STRUCT。不支持 LARGEINT、HLL、BITMAP 类型。 |
注意
所有非分区列均以
NULL为默认值(即,在建表语句中指定DEFAULT "NULL")。分区列必须在最后声明,且不能为NULL。
partition_desc
partition_desc 语法定义如下:
PARTITION BY (par_col1[, par_col2...])
目前 StarRocks 仅支持 Identity Transforms。 即,会为每个唯一的分区值创建一个分区。
注意
分区列必须在最后声明,支持除 FLOAT、DOUBLE、DECIMAL、DATETIME 以外的数据类型,不支持
NULL值。而且,partition_desc中声明的分区列的顺序必须与column_definition中定义的列的顺序一致。
PROPERTIES
可以在 PROPERTIES 中通过 "key" = "value" 的形式声明 Hive 表的属性。
以下为常见的几个属性:
| 属性 | 描述 |
|---|---|
| location | Managed Table 所在的文件路径。使用 HMS 作为元数据服务时,您无需指定 location 参数。使用 AWS Glue 作为元数据服务时:
|
| file_format | Managed Table 的文件格式。当前支持 Parquet、ORC、Textfile 文件格式,其中 ORC 和 Textfile 文件格式自 3.3 版本起支持。取值范围:parquet、orc、textfile。默认值:parquet。 |
| compression_codec | Managed Table 的压缩格式。该属性自 3.2.3 版本起弃用,此后写入 Hive 表时的压缩算法统一由会话变量 connector_sink_compression_codec 控制。 |
示例
以下建表语句以默认的 Parquet 格式为例。
-
创建非分区表
unpartition_tbl,包含id和score两列,如下所示:CREATE TABLE unpartition_tbl
(
id int,
score double
); -
创建分区表
partition_tbl_1,包含action、id、dt三列,并定义id和dt为分区列,如下所示:CREATE TABLE partition_tbl_1
(
action varchar(20),
id int,
dt date
)
PARTITION BY (id,dt); -
查询原表
partition_tbl_1的数据,并根据查询结果创建分区表partition_tbl_2,定义id和dt为partition_tbl_2的分区列:CREATE TABLE partition_tbl_2
PARTITION BY (id, dt)
AS SELECT * from partition_tbl_1;
向 Hive 表中插入数据
同 StarRocks 内表一致,如果您拥有 Hive 表(Managed Table 或 External Table)的 INSERT 权限,那么您可以使用 INSERT 将 StarRocks 表数据写入到该 Hive 表中。
本功能自 3.2 版本起开始支持,彼时只支持写入到 Parquet 格式的 Hive 表。自 3.3 版本起,该功能还支持写入到 ORC 及 Textfile 格式的 Hive 表。
需要注意的是,写数据到 External Table 的功能默认是关闭的,您需要通过系统变量 ENABLE_WRITE_HIVE_EXTERNAL_TABLE 打开。
- 您可以通过 GRANT 和 REVOKE 操作对用户和角色进行权限的赋予和收回。
- 您可以通过会话变量 connector_sink_compression_codec 来指定写入 Hive 表时的压缩算法。
切换至目标 Hive Catalog 和数据库,然后通过如下语法将 StarRocks 表数据写入到 Parquet 格式的 Hive 表中:
语法
INSERT {INTO | OVERWRITE} <table_name>
[ (column_name [, ...]) ]
{ VALUES ( { expression | DEFAULT } [, ...] ) [, ...] | query }
-- 向指定分区写入数据。
INSERT {INTO | OVERWRITE} <table_name>
PARTITION (par_col1=<value> [, par_col2=<value>...])
{ VALUES ( { expression | DEFAULT } [, ...] ) [, ...] | query }
注意
分区列不允许为
NULL,因此导入时需要保证分区列有值。
参数说明
| 参数 | 说明 |
|---|---|
| INTO | 将数据追加写入目标表。 |
| OVERWRITE | 将数据覆盖写入目标表。 |
| column_name | 导入的目标列。可以指定一个或多个列。指定多个列时,必须用逗号 (,) 分隔。指定的列必须是目标表中存在的列,并且必须包含分区列。该参数可以与源表中的列名称不同,但顺序需一一对应。如果不指定该参数,则默认导入数据到目标表中的所有列。如果源表中的某个非分区列在目标列不存在,则写入默认值 NULL。如果查询语句的结果列类型与目标列的类型不一致,会进行隐式转化,如果不能进行转化,那么 INSERT INTO 语句会报语法解析错误。 |
| expression | 表达式,用以为对应列赋值。 |
| DEFAULT | 为对应列赋予默认值。 |
| query | 查询语句,查询的结果会导入至目标表中。查询语句支持任意 StarRocks 支持的 SQL 查询语法。 |
| PARTITION | 导入的目标分区。需要指定目标表的所有分区列,指定的分区列的顺序可以与建表时定义的分区列的顺序不一致。指定分区时,不允许通过列名 (column_name) 指定导入的目标列。 |
示例
以下写入语句以默认的 Parquet 格式为例。
-
向表
partition_tbl_1中插入如下三行数据:INSERT INTO partition_tbl_1
VALUES
("buy", 1, "2023-09-01"),
("sell", 2, "2023-09-02"),
("buy", 3, "2023-09-03"); -
向表
partition_tbl_1按指定列顺序插入一个包含简单计算的 SELECT 查询的结果数据:INSERT INTO partition_tbl_1 (id, action, dt) SELECT 1+1, 'buy', '2023-09-03'; -
向表
partition_tbl_1中插入一个从其自身读取数据的 SELECT 查询的结果数据:INSERT INTO partition_tbl_1 SELECT 'buy', 1, date_add(dt, INTERVAL 2 DAY)
FROM partition_tbl_1
WHERE id=1; -
向表
partition_tbl_2中dt='2023-09-01'��、id=1的分区插入一个 SELECT 查询的结果数据:INSERT INTO partition_tbl_2 SELECT 'order', 1, '2023-09-01';Or
INSERT INTO partition_tbl_2 partition(dt='2023-09-01',id=1) SELECT 'order'; -
将表
partition_tbl_1中dt='2023-09-01'、id=1的分区下所有action列值全部覆盖为close:INSERT OVERWRITE partition_tbl_1 SELECT 'close', 1, '2023-09-01';Or
INSERT OVERWRITE partition_tbl_1 partition(dt='2023-09-01',id=1) SELECT 'close';
删除 Hive 表
同 StarRocks 内表一致,如果您拥有 Hive 表的 DROP 权限,那么您可以使用 DROP TABLE 来删除该 Hive 表。本功能自 3.2 版本起开始支持。注意当前只支持删除 Hive 的 Managed Table。
执行删除表的操作时,您必须在 DROP TABLE 语句中指定 FORCE 关键字。该操作不会删除表对应的文件路径,但是会删除 HDFS 或对象存储上的表数据。请您谨慎执行该操作。
切换至目标 Hive Catalog 和数据库,然后通过如下语句删除 Hive 表:
DROP TABLE <table_name> FORCE
手动或自动更新元数据缓存
手动更新
默认情况下,StarRocks 会缓存 Hive 的元数据、并以异步模式自动更新缓存的元数据,从而提高查询性能。此外,在对 Hive 表做了表结构变更或其他表更新后,您也可以使用 REFRESH EXTERNAL TABLE 手动更新该表的元数据,从而确保 StarRocks 第一时间生成合理的查询计划:
REFRESH EXTERNAL TABLE <table_name> [PARTITION ('partition_name', ...)]
以下情况适用于执行手动更新元数据:
-
已有分区内的数据文件发生变更,如执行过
INSERT OVERWRITE ... PARTITION ...命令。 -
Hive 表有 Schema 变更。
-
Hive 表被 DROP 后重建一个同名 Hive 表。
-
创建 Hive Catalog 时在
PROPERTIES中指定了"enable_cache_list_names" = "true"。在 Hive 侧新增分区后,需要查询新增分区。备注自 2.5.5 版本起,StarRocks 支持周期性刷新 Hive 元数据缓存。参见本文下面”周期性刷新元数据缓存“小节。开启 Hive 元数据缓存周期性刷新功能以后,默认情况下 StarRocks 每 10 分钟刷新一次 Hive 元数据缓存。因此,一般情况下,无需执行手动更新。您只有在新增分区后,需要立即查询新增分区的数据时,才需要执行手动更新。
注意 REFRESH EXTERNAL TABLE 只会更新 FE 中已缓存的表和分区。
周期性刷新元数据缓存
自 2.5.5 版本起,StarRocks 可以周期性刷新经常访问的 Hive 外部数据目录的元数据缓存,达到感知数据更新的效果。您可以通过以下 FE 参数配置 Hive 元数据缓存周期性刷新:
| 配置名称 | 默认值 | 说明 |
|---|---|---|
| enable_background_refresh_connector_metadata | v3.0 为 true,v2.5 为 false | 是否开启 Hive 元数据缓存周期性刷新。开启后,StarRocks 会轮询 Hive 集群的元数据服务(HMS 或 AWS Glue),并刷新经常访问的 Hive 外部数据目录的元数据缓存,以感知数据更新。true 代表开启,false 代表关闭。FE 动态参数,可以通过 ADMIN SET FRONTEND CONFIG 命令设置。 |
| background_refresh_metadata_interval_millis | 600000(10 分钟) | 接连两次 Hive 元数据缓存刷新之间的间隔。单位:毫秒。FE 动态参数,可以通过 ADMIN SET FRONTEND CONFIG 命令设置。 |
| background_refresh_metadata_time_secs_since_last_access_secs | 86400(24 小时) | Hive 元数据缓存刷新任务过期时间。对于已被访问过的 Hive Catalog,如果超过该时间没有被访问,则停止刷新其元数据缓存。对于未被访问过的 Hive Catalog,StarRocks 不会刷新其元数据缓存。单位:秒。FE 动态参数,可以通过 ADMIN SET FRONTEND CONFIG 命令设置。 |
元数据缓存周期性刷新与元数据自动异步更新策略配合使用,可以进一步加快数据访问速度,降低从外部数据源读取数据的压力,提升查询性能。
附录:理解元数据自动异步更新策略
自动异步更新策略是 StarRocks 用于更新 Hive Catalog 中元数据的默认策略。
默认情况下(即当 enable_metastore_cache 参数和 enable_remote_file_cache 参数均设置为 true 时),如果一个查询命中 Hive 表的某个分区,则 StarRocks 会自动缓存该分区的元数据、以及该分区下数据文件的元数据。缓存的元数据采用懒更新 (Lazy Update) 策略。
例如,有一张名为 table2 的 Hive 表,该表的数据分布在四个分区:p1、p2、p3 和 p4。当一个查询命中 p1 时,StarRocks 会自动缓存 p1 的元数据、以及 p1 下数据文件的元数据。假设当前缓存元数据的更新和淘汰策略设置如下:
- 异步更新
p1的缓存元数据的时间间隔(通过metastore_cache_refresh_interval_sec参数指定)为 60 秒。 - 异步更新
p1下数据文件的缓存元数据的时间间隔(通过remote_file_cache_refresh_interval_sec参数指定)为 60 秒。 - 自动淘汰
p1的缓存元数据的时间间隔(通过metastore_cache_ttl_sec参数指定)为 24 小时。 - 自动淘汰
p1下数据文件的缓存元数据的时间间隔(通过remote_file_cache_ttl_sec参数指定)为 36 小时。
如下图所示。
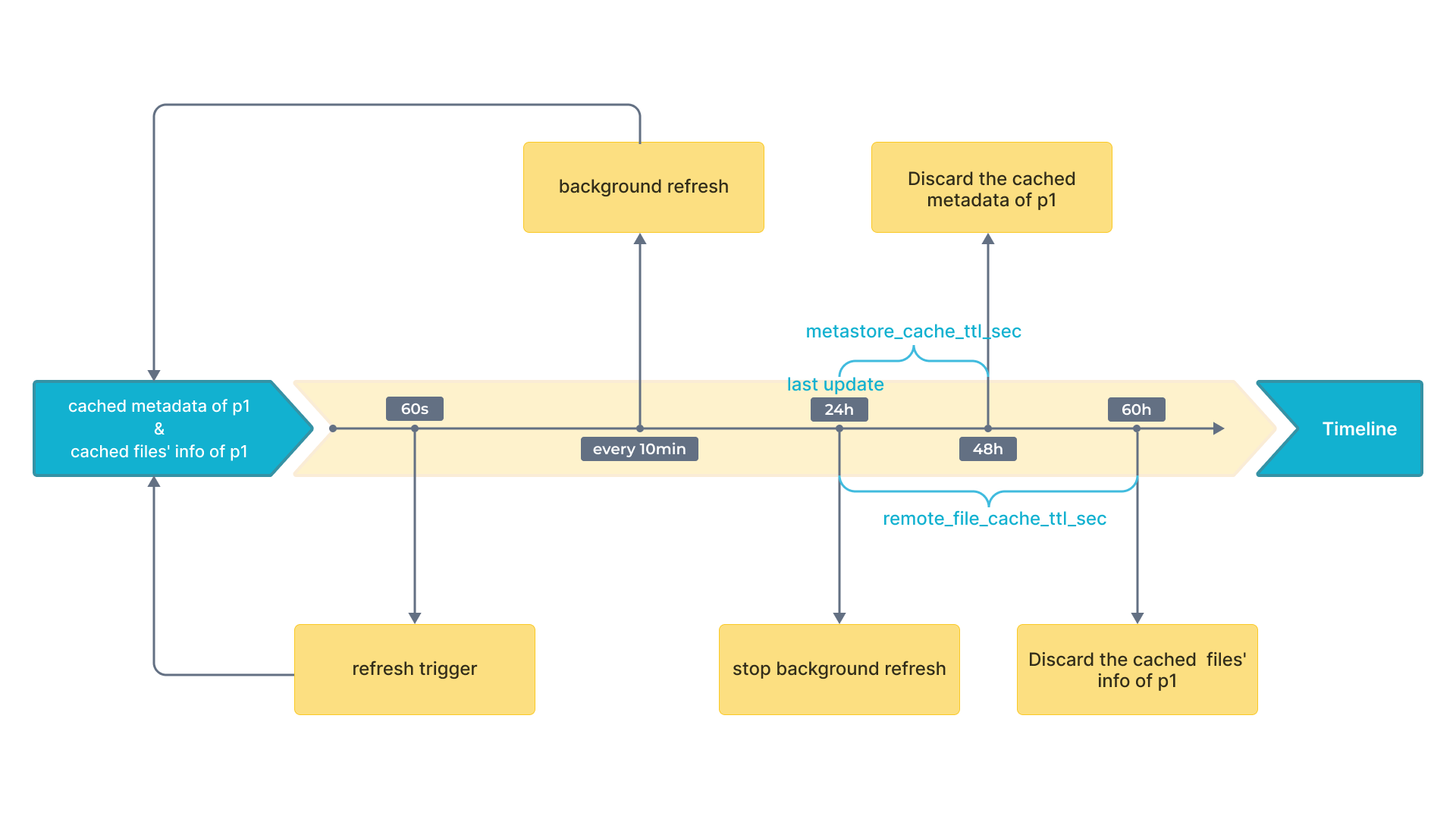
StarRocks 采用如下策略更新和淘汰缓存的元数据:
- 如果另有查询再次命中
p1,并且当前时间距离上次更新的时间间隔不超过 60 秒,则 StarRocks 既不会更新p1的缓存元数据,也不会更新p1下数据文件的缓存元数据。 - 如果另有查询再次命中
p1,并且当前时间距离上�次更新的时间间隔超过 60 秒,则 StarRocks 会更新p1的缓存元数据以及p1下数据文件的缓存元数据。 - 如果表在 24 小时内被访问过,相关缓存将每 10 分钟在后台刷新一次。
- 如果继上次更新结束后,
p1在 24 小时内未被访问,则 StarRocks 会淘汰p1的缓存元数据。后续有查询再次命中p1时,会重新缓存p1的元数据。 - 如果继上次更新结束后,
p1在 36 小时内未被访问,则 StarRocks 会淘汰p1下数据文件的缓存元数据。后续有查询再次命中p1时,会重新缓存p1下数据文件的元数据。
