从云存储导入
StarRocks 支持通过两种方式从云存储系统导入大批量数据:Broker Load 和 INSERT。
在 3.0 及以前版本,StarRocks 只支持 Broker Load 导入方式。Broker Load 是一种异步导入方式,即您提交导入作业以后,StarRocks 会异步地执行导入作业。您可以使用 SELECT * FROM information_schema.loads 来查看 Broker Load 作业的结果,该功能自 3.1 版本起支持,具体请参见本文“查看导入作业”小节。
Broker Load 能够保证单次导入事务的原子性,即单次导入的多个数据文件都成功或者都失败,而不会出现部分导入成功、部分导入失败的情况。
另外,Broker Load 还支持在导入过程中做数据转换、以及通过 UPSERT 和 DELETE 操作实现数据变更。请参见导入过程中实现数据转换和通过导入实现数据变更。
注意
Broker Load 操作需要目标表的 INSERT 权限。如果您的用户账号没有 INSERT 权限,请参考 GRANT 给用户赋权。
从 3.1 版本起,StarRocks 新增支持使用 INSERT 语句和 FILES 关键字直接从 AWS S3 导入 Parquet 或 ORC 格式的数据文件,避免了需事先创建外部表的麻烦。参见 INSERT > 通过 FILES 关键字直接导入外部数据文件。
本文主要介绍如何使用 Broker Load 从云存储系统导入数据。
支持的数据文件格式
Broker Load 支持如下数据文件格式:
-
CSV
-
Parquet
-
ORC
-
JSON(自 3.2.3 版本起支持)
说明
对于 CSV 格式的数据,需要注意以下两点:
- StarRocks 支持设置长度最大不超过 50 个字节的 UTF-8 编码字符串作为列分隔符,包括常见的逗号 (,)、Tab 和 Pipe (|)。
- 空值 (null) 用
\N表示。比如,数据文件一共有三列,其中某行数据的第一列、第三列数据分别为a和b,第二列没有数据,则第二列需要用\N来表示空值,写作a,\N,b,而不是a,,b。a,,b表示第二列是一个空字符串。
基本原理
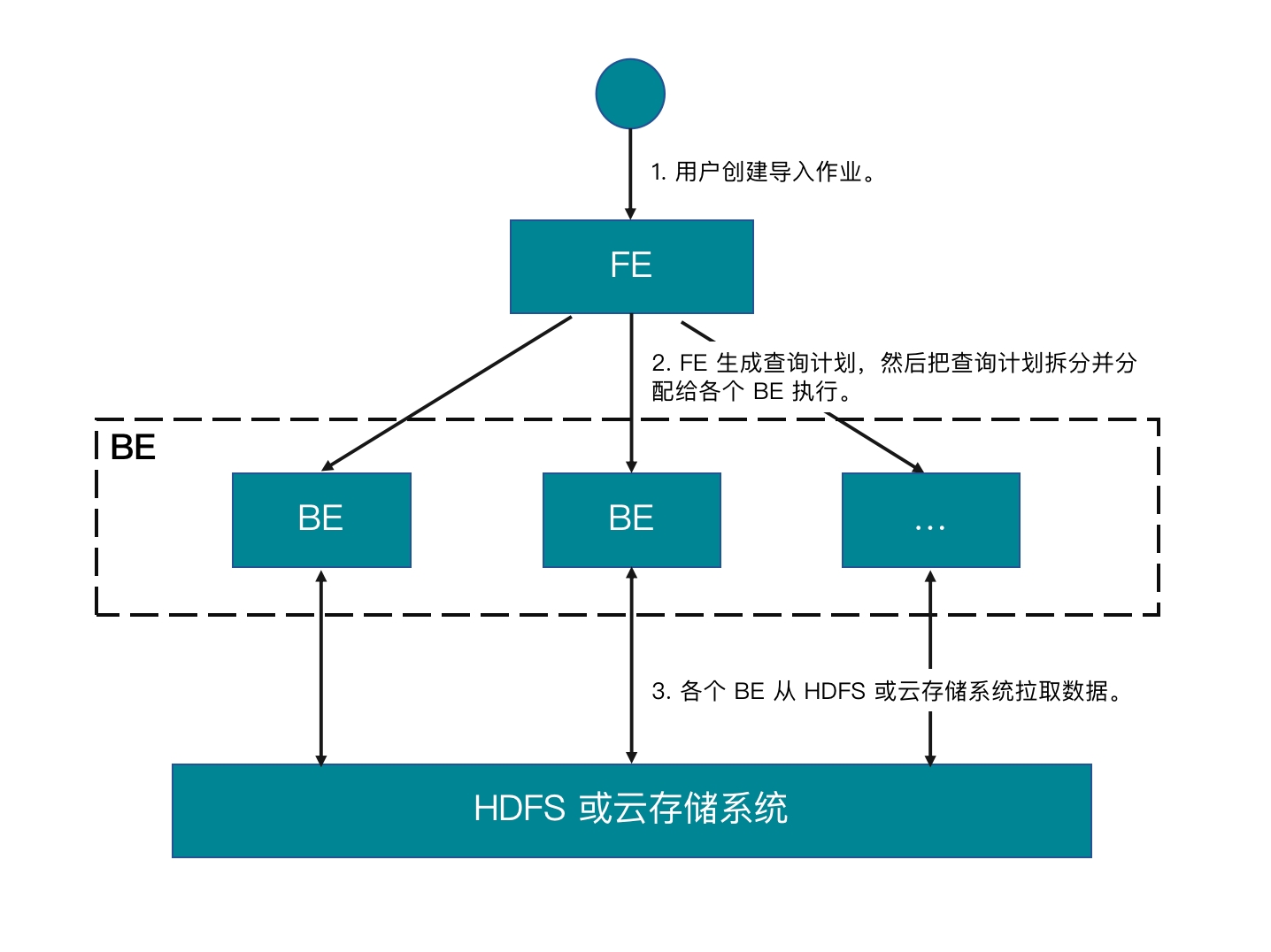
提交导入作业以后,FE 会生成对应的查询计划,并根据目前可用 BE(或 CN)的个数和源数据文件的大小,将查询计划分配给多个 BE(或 CN)执行。每个 BE(或 CN)负责执行一部分导入任务。BE(或 CN)在执行过程中,会从外�部存储系统拉取数据,并且会在对数据进行预处理之后将数据导入到 StarRocks 中。所有 BE(或 CN)均完成导入后,由 FE 最终判断导入作业是否成功。
下图展示了 Broker Load 的主要流程:
准备数据样例
-
在本地文件系统下,创建两个 CSV 格式的数据文件,
file1.csv和file2.csv。两个数据文件都包含三列,分别代表用户 ID、用户姓名和用户得分,如下所示:-
file1.csv1,Lily,21
2,Rose,22
3,Alice,23
4,Julia,24 -
file2.csv5,Tony,25
6,Adam,26
7,Allen,27
8,Jacky,28
-
-
将
file1.csv和file2.csv上传到云存储空间的指定路径下。这里假设分别上传到 AWS S3 存储空间bucket_s3里的input文件夹下、 Google GCS 存储空间bucket_gcs里的input文件夹下、阿里云 OSS 存储空间bucket_oss里的input文件夹下、腾讯云 COS 存储空间bucket_cos里的input文件夹下、华为云 OBS 存储空间bucket_obs里的input文件夹下、其他兼容 S3 协议的对象存储(如 MinIO)空间bucket_minio里的input文件夹下、以及 Azure Storage 的指定路径下。 -
登录 StarRocks 数据库(假设为
test_db),创建两张主键表,table1和table2。两张表都包含id、name和score三列,分别代表用户 ID、用户姓名和用户得分,主键为id列,如下所示:CREATE TABLE `table1`
(
`id` int(11) NOT NULL COMMENT "用户 ID",
`name` varchar(65533) NULL DEFAULT "" COMMENT "用户姓名",
`score` int(11) NOT NULL DEFAULT "0" COMMENT "用户得分"
)
ENGINE=OLAP
PRIMARY KEY(`id`)
DISTRIBUTED BY HASH(`id`);
CREATE TABLE `table2`
(
`id` int(11) NOT NULL COMMENT "用户 ID",
`name` varchar(65533) NULL DEFAULT "" COMMENT "用户姓名",
`score` int(11) NOT NULL DEFAULT "0" COMMENT "用户得分"
)
ENGINE=OLAP
PRIMARY KEY(`id`)
DISTRIBUTED BY HASH(`id`);
从 AWS S3 导入
注意,Broker Load 支持通过 S3 或 S3A 协议访问 AWS S3,因此从 AWS S3 导入数据时,您在文件路径 (DATA INFILE) 中传入的目标文件的 S3 URI 可以使用 s3:// 或 s3a:// 作为前缀。
另外注意,下述命令以 CSV 格式和基于 Instance Profile 的认证方式为例。有关如何导入其他格式的数据、以及使用其他认证方式时需要配置的参数,参见 BROKER LOAD。
导入单个数据文件到单表
操作示例
通过如下语句,把 AWS S3 存储空间 bucket_s3 里 input 文件夹内数据文件 file1.csv 的数据导入到目标表 table1:
LOAD LABEL test_db.label_brokerloadtest_101
(
DATA INFILE("s3a://bucket_s3/input/file1.csv")
INTO TABLE table1
COLUMNS TERMINATED BY ","
(id, name, score)
)
WITH BROKER
(
"aws.s3.use_instance_profile" = "true",
"aws.s3.region" = "<aws_s3_region>"
)
PROPERTIES
(
"timeout" = "3600"
);
查询数据
提交导入作业以后,您可以使用 SELECT * FROM information_schema.loads 来查看 Broker Load 作业的结果,该功能自 3.1 版本起支持,具体请参见本文“查看导入作业”小节。
确认导入作业成功以后,您可以使用 SELECT 语句来查询 table1 的数据,如下所示:
SELECT * FROM table1;
+------+-------+-------+
| id | name | score |
+------+-------+-------+
| 1 | Lily | 21 |
| 2 | Rose | 22 |
| 3 | Alice | 23 |
| 4 | Julia | 24 |
+------+-------+-------+
4 rows in set (0.01 sec)
导入多个数据文件到单表
操作示例
通过如下语句,把AWS S3 存储空间 bucket_s3 里 input 文件夹内所有数据文件(file1.csv 和 file2.csv)的数据导入到目标表 table1:
LOAD LABEL test_db.label_brokerloadtest_102
(
DATA INFILE("s3a://bucket_s3/input/*")
INTO TABLE table1
COLUMNS TERMINATED BY ","
(id, name, score)
)
WITH BROKER
(
"aws.s3.use_instance_profile" = "true",
"aws.s3.region" = "<aws_s3_region>"
)
PROPERTIES
(
"timeout" = "3600"
);
查询数据
提交导入作业以后,您可以使用 SELECT * FROM information_schema.loads 来查看 Broker Load 作业的结果,该功能自 3.1 版本起支持,具体请参见本文“查看导入作业”小节。
确认导入作业成功以后,您可以使用 SELECT 语句来查询 table1 的数据,如下所示:
SELECT * FROM table1;
+------+-------+-------+
| id | name | score |
+------+-------+-------+
| 1 | Lily | 21 |
| 2 | Rose | 22 |
| 3 | Alice | 23 |
| 4 | Julia | 24 |
| 5 | Tony | 25 |
| 6 | Adam | 26 |
| 7 | Allen | 27 |
| 8 | Jacky | 28 |
+------+-------+-------+
4 rows in set (0.01 sec)
导入多个数据文件到多表
操作示例
通过如下语句,把 AWS S3 存储空间 bucket_s3 里 input 文件夹内数据文件 file1.csv 和 file2.csv 的数据分别导入到目标表 table1 和 table2:
LOAD LABEL test_db.label_brokerloadtest_103
(
DATA INFILE("s3a://bucket_s3/input/file1.csv")
INTO TABLE table1
COLUMNS TERMINATED BY ","
(id, name, score)
,
DATA INFILE("s3a://bucket_s3/input/file2.csv")
INTO TABLE table2
COLUMNS TERMINATED BY ","
(id, name, score)
)
WITH BROKER
(
"aws.s3.use_instance_profile" = "true",
"aws.s3.region" = "<aws_s3_region>"
)
PROPERTIES
(
"timeout" = "3600"
);
查询数据
提交导入作业以后,您可以使用 SELECT * FROM information_schema.loads 来查看 Broker Load 作业的结果,该功能自 3.1 版本起支持,具体请参见本文“查看导入作业”小节。
确认导入作业成功以后,您可以使用 SELECT 语句来查询 table1 和 table2 中的数据:
-
查询
table1的数据,如下所示:SELECT * FROM table1;
+------+-------+-------+
| id | name | score |
+------+-------+-------+
| 1 | Lily | 21 |
| 2 | Rose | 22 |
| 3 | Alice | 23 |
| 4 | Julia | 24 |
+------+-------+-------+
4 rows in set (0.01 sec) -
查询
table2的数据,如下所示:SELECT * FROM table2;
+------+-------+-------+
| id | name | score |
+------+-------+-------+
| 5 | Tony | 25 |
| 6 | Adam | 26 |
| 7 | Allen | 27 |
| 8 | Jacky | 28 |
+------+-------+-------+
4 rows in set (0.01 sec)
从 Google GCS 导入
注意,由于 Broker Load 只支持通过 gs 协议访问 Google GCS,因此从 Google GCS 导入数据时,必须确保您在文件路径 (DATA INFILE) 中传入的目标文件的 GCS URI 使用 gs:// 作为前缀。
另外注意,下述命令以 CSV 格式和基于 VM 的认证方式为例。有关如何导入其他格式的数据、以及使用其他认证方式时需要配置的参数,参见 BROKER LOAD。
导入单个数据文件到单表
操作示例
通过如下语句,把 Google GCS 存储空间 bucket_gcs 里 input 文件夹内数据文件 file1.csv 的数据导入到目标表 table1:
LOAD LABEL test_db.label_brokerloadtest_201
(
DATA INFILE("gs://bucket_gcs/input/file1.csv")
INTO TABLE table1
COLUMNS TERMINATED BY ","
(id, name, score)
)
WITH BROKER
(
"gcp.gcs.use_compute_engine_service_account" = "true"
)
PROPERTIES
(
"timeout" = "3600"
);
查询数据
提交导入作业以后,您可以使用 SELECT * FROM information_schema.loads 来查看 Broker Load 作业的结果,该功能自 3.1 版本起支持,具体请参见本文“查看导入作业”小节。
确认导入作业成功以后,您可以使用 SELECT 语句来查询 table1 的数据,如下所示:
SELECT * FROM table1;
+------+-------+-------+
| id | name | score |
+------+-------+-------+
| 1 | Lily | 21 |
| 2 | Rose | 22 |
| 3 | Alice | 23 |
| 4 | Julia | 24 |
+------+-------+-------+
4 rows in set (0.01 sec)
导入多个数据文件到单表
操作示例
通过如下语句,把 Google GCS 存储空间 bucket_gcs 里 input 文件夹内所有数据文件(file1.csv 和 file2.csv)的数据导入到目标表 table1:
LOAD LABEL test_db.label_brokerloadtest_202
(
DATA INFILE("gs://bucket_gcs/input/*")
INTO TABLE table1
COLUMNS TERMINATED BY ","
(id, name, score)
)
WITH BROKER
(
"gcp.gcs.use_compute_engine_service_account" = "true"
)
PROPERTIES
(
"timeout" = "3600"
);
查询数据
提交导入作业以后,您可以使用 SELECT * FROM information_schema.loads 来查看 Broker Load 作业的结果,该功能自 3.1 版本起支持,具体请参见本文“查看导入作业”小节。
确认导入作业成功以后,您可以使用 SELECT 语句来查询 table1 的数据,如下所示:
SELECT * FROM table1;
+------+-------+-------+
| id | name | score |
+------+-------+-------+
| 1 | Lily | 21 |
| 2 | Rose | 22 |
| 3 | Alice | 23 |
| 4 | Julia | 24 |
| 5 | Tony | 25 |
| 6 | Adam | 26 |
| 7 | Allen | 27 |
| 8 | Jacky | 28 |
+------+-------+-------+
4 rows in set (0.01 sec)
导入多�个数据文件到多表
操作示例
通过如下语句,把 Google GCS 存储空间 bucket_gcs 里 input 文件夹内数据文件 file1.csv 和 file2.csv 的数据分别导入到目标表 table1 和 table2:
LOAD LABEL test_db.label_brokerloadtest_203
(
DATA INFILE("gs://bucket_gcs/input/file1.csv")
INTO TABLE table1
COLUMNS TERMINATED BY ","
(id, name, score)
,
DATA INFILE("gs://bucket_gcs/input/file2.csv")
INTO TABLE table2
COLUMNS TERMINATED BY ","
(id, name, score)
)
WITH BROKER
(
"gcp.gcs.use_compute_engine_service_account" = "true"
);
PROPERTIES
(
"timeout" = "3600"
);
查询数据
提交导入作业以后,您可以使用 SELECT * FROM information_schema.loads 来查看 Broker Load 作业的结果,该功能自 3.1 版本起支持,具体请参见本文“查看导入作业”小节。
确认导入作业成功以后,您可以使用 SELECT 语句来查询 table1 和 table2 中的数据:
-
查询
table1的数据,如下所示:SELECT * FROM table1;
+------+-------+-------+
| id | name | score |
+------+-------+-------+
| 1 | Lily | 21 |
| 2 | Rose | 22 |
| 3 | Alice | 23 |
| 4 | Julia | 24 |
+------+-------+-------+
4 rows in set (0.01 sec) -
查询
table2的数据,如下所示:SELECT * FROM table2;
+------+-------+-------+
| id | name | score |
+------+-------+-------+
| 5 | Tony | 25 |
| 6 | Adam | 26 |
| 7 | Allen | 27 |
| 8 | Jacky | 28 |
+------+-------+-------+
4 rows in set (0.01 sec)
从 Microsoft Azure Storage 导入
注意,从 Azure Storage 导入数据时,您需要根据所使用的访问协议和存储服务来确定文件路径 (DATA INFILE) 的前缀:
- 从 Blob Storage 导入数据时,需要根据使用的访问协议在文件路径 (
DATA INFILE) 里添加wasb://或wasbs://作为前缀:- 如果使用 HTTP 协议进行访问,请使用
wasb://作为前缀,例如,wasb://<container>@<storage_account>.blob.core.windows.net/<path>/<file_name>/*。 - 如果使用 HTTPS 协议进行访问,请使用
wasbs://作为前缀,例如,wasbs://<container>@<storage_account>.blob.core.windows.net/<path>/<file_name>/*。
- 如果使用 HTTP 协议进行访问,请使用
- 从 Azure Data Lake Storage Gen1 导入数据时,需要在文件路径 (
DATA INFILE) 里添加adl://作为前缀,例如,adl://<data_lake_storage_gen1_name>.azuredatalakestore.net/<path>/<file_name>。 - 从 Data Lake Storage Gen2 导入数据时,需要根据使用的访问协议在文件路径 (
DATA INFILE) 里添加abfs://或abfss://作为前缀:- 如果使用 HTTP 协议进行访问,请使用
abfs://作为前缀,例如,abfs://<container>@<storage_account>.dfs.core.windows.net/<file_name>。 - 如果使用 HTTPS 协议进行访问,请使用
abfss://作为前缀,例如,abfss://<container>@<storage_account>.dfs.core.windows.net/<file_name>。
- 如果使用 HTTP 协议进行访问,请使用
另外注意,下述命令以 CSV 格式、Azure Blob Storage 和基于 Shared Key 的认证方式为例。有关如何导入其他格式的数据、以及使用其他 Azure 对象存储服务和其他认证方式时需要配置的参数,参见 BROKER LOAD。
导入单个数据文件到单表
操作示例
通过如下语句,把 Azure Storage 指定路径下数据文件 file1.csv 的数据导入到目标表 table1:
LOAD LABEL test_db.label_brokerloadtest_301
(
DATA INFILE("wasb[s]://<container>@<storage_account>.blob.core.windows.net/<path>/file1.csv")
INTO TABLE table1
COLUMNS TERMINATED BY ","
(id, name, score)
)
WITH BROKER
(
"azure.blob.storage_account" = "<blob_storage_account_name>",
"azure.blob.shared_key" = "<blob_storage_account_shared_key>"
)
PROPERTIES
(
"timeout" = "3600"
);
查询数据
提交导入作业以后,您可以使用 SELECT * FROM information_schema.loads 来查看 Broker Load 作业的结果,该功能自 3.1 版本起支持,具体请参见本文“查看导入作业”小节。
确认导入作业成功以后,您可以使用 SELECT 语句来查询 table1 的数据,如下所示:
SELECT * FROM table1;
+------+-------+-------+
| id | name | score |
+------+-------+-------+
| 1 | Lily | 21 |
| 2 | Rose | 22 |
| 3 | Alice | 23 |
| 4 | Julia | 24 |
+------+-------+-------+
4 rows in set (0.01 sec)
导入多个数据文件�到单表
操作示例
通过如下语句,把 Azure Storage 指定路径下所有数据文件(file1.csv 和 file2.csv)的数据导入到目标表 table1:
LOAD LABEL test_db.label_brokerloadtest_302
(
DATA INFILE("wasb[s]://<container>@<storage_account>.blob.core.windows.net/<path>/*")
INTO TABLE table1
COLUMNS TERMINATED BY ","
(id, name, score)
)
WITH BROKER
(
"azure.blob.storage_account" = "<blob_storage_account_name>",
"azure.blob.shared_key" = "<blob_storage_account_shared_key>"
)
PROPERTIES
(
"timeout" = "3600"
);
查询数据
提交导入作业以后,您可以使用 SELECT * FROM information_schema.loads 来查看 Broker Load 作业的结果,该功能自 3.1 版本起支持,具体请参见本文“查看导入作业”小节。
确认导入作业成功以后,您可以使用 SELECT 语句来查询 table1 的数据,如下所示:
SELECT * FROM table1;
+------+-------+-------+
| id | name | score |
+------+-------+-------+
| 1 | Lily | 21 |
| 2 | Rose | 22 |
| 3 | Alice | 23 |
| 4 | Julia | 24 |
| 5 | Tony | 25 |
| 6 | Adam | 26 |
| 7 | Allen | 27 |
| 8 | Jacky | 28 |
+------+-------+-------+
4 rows in set (0.01 sec)
导入多个数据文件到多表
操作示例
通过如下语句,把 Azure Storage 指定路径下数据文件 file1.csv 和 file2.csv 的数据分别导入到目标表 table1 和 table2:
LOAD LABEL test_db.label_brokerloadtest_303
(
DATA INFILE("wasb[s]://<container>@<storage_account>.blob.core.windows.net/<path>/file1.csv")
INTO TABLE table1
COLUMNS TERMINATED BY ","
(id, name, score)
,
DATA INFILE("wasb[s]://<container>@<storage_account>.blob.core.windows.net/<path>/file2.csv")
INTO TABLE table2
COLUMNS TERMINATED BY ","
(id, name, score)
)
WITH BROKER
(
"azure.blob.storage_account" = "<blob_storage_account_name>",
"azure.blob.shared_key" = "<blob_storage_account_shared_key>"
);
PROPERTIES
(
"timeout" = "3600"
);
查询数据
提交导入作业以后,您可以使用 SELECT * FROM information_schema.loads 来查看 Broker Load 作业的结果,该功能自 3.1 版本起支持,具体请参见本文“查看导入作业”小节。
确认导入作业成功以后,您可以使用 SELECT 语句来查询 table1 和 table2 中的数据:
-
查询
table1的数据,如下所示:SELECT * FROM table1;
+------+-------+-------+
| id | name | score |
+------+-------+-------+
| 1 | Lily | 21 |
| 2 | Rose | 22 |
| 3 | Alice | 23 |
| 4 | Julia | 24 |
+------+-------+-------+
4 rows in set (0.01 sec) -
查询
table2的数据,如下所示:SELECT * FROM table2;
+------+-------+-------+
| id | name | score |
+------+-------+-------+
| 5 | Tony | 25 |
| 6 | Adam | 26 |
| 7 | Allen | 27 |
| 8 | Jacky | 28 |
+------+-------+-------+
4 rows in set (0.01 sec)
从阿里云 OSS 导入
下述命令以 CSV 格式为例。有关如何导入其他格式的数据,参见 BROKER LOAD。
导入单个数据文件到单表
操作示例
通过如下语句,把阿里云 OSS 存储空间 bucket_oss 里 input 文件夹内数据文件 file1.csv 的数据导入到目标表 table1:
LOAD LABEL test_db.label_brokerloadtest_401
(
DATA INFILE("oss://bucket_oss/input/file1.csv")
INTO TABLE table1
COLUMNS TERMINATED BY ","
(id, name, score)
)
WITH BROKER
(
"fs.oss.accessKeyId" = "<oss_access_key>",
"fs.oss.accessKeySecret" = "<oss_secret_key>",
"fs.oss.endpoint" = "<oss_endpoint>"
)
PROPERTIES
(
"timeout" = "3600"
);
查询数据
提交导入作业以后,您可以使用 SELECT * FROM information_schema.loads 来查看 Broker Load 作业的结果,该功能自 3.1 版本起支持,具体请参见本文“查看导入作业”小节。
确认导入作业成功以后,您可以使用 SELECT 语句来查询 table1 的数据,如下所示:
SELECT * FROM table1;
+------+-------+-------+
| id | name | score |
+------+-------+-------+
| 1 | Lily | 21 |
| 2 | Rose | 22 |
| 3 | Alice | 23 |
| 4 | Julia | 24 |
+------+-------+-------+
4 rows in set (0.01 sec)
导入多个数据文件到单表
操作示例
通过如下语句,把阿里云 OSS 存储空间 bucket_oss 里 input 文件夹内所有数据文件(file1.csv 和 file2.csv)的数据导入到目标表 table1:
LOAD LABEL test_db.label_brokerloadtest_402
(
DATA INFILE("oss://bucket_oss/input/*")
INTO TABLE table1
COLUMNS TERMINATED BY ","
(id, name, score)
)
WITH BROKER
(
"fs.oss.accessKeyId" = "<oss_access_key>",
"fs.oss.accessKeySecret" = "<oss_secret_key>",
"fs.oss.endpoint" = "<oss_endpoint>"
)
PROPERTIES
(
"timeout" = "3600"
);
查询数据
提交导入作业以后,您可以使用 SELECT * FROM information_schema.loads 来查看 Broker Load 作业的结果,该功能自 3.1 版本起支持,具体请参见本文“查看导入作业”小节。
确认导入作业成功��以后,您可以使用 SELECT 语句来查询 table1 的数据,如下所示:
SELECT * FROM table1;
+------+-------+-------+
| id | name | score |
+------+-------+-------+
| 1 | Lily | 21 |
| 2 | Rose | 22 |
| 3 | Alice | 23 |
| 4 | Julia | 24 |
| 5 | Tony | 25 |
| 6 | Adam | 26 |
| 7 | Allen | 27 |
| 8 | Jacky | 28 |
+------+-------+-------+
4 rows in set (0.01 sec)
导入多个数据文件到多表
操作示例
通过如下语句,把阿里云 OSS 存储空间 bucket_oss 里 input 文件夹内数据文件 file1.csv 和 file2.csv 的数据分别导入到目标表 table1 和 table2:
LOAD LABEL test_db.label_brokerloadtest_403
(
DATA INFILE("oss://bucket_oss/input/file1.csv")
INTO TABLE table1
COLUMNS TERMINATED BY ","
(id, name, score)
,
DATA INFILE("oss://bucket_oss/input/file2.csv")
INTO TABLE table2
COLUMNS TERMINATED BY ","
(id, name, score)
)
WITH BROKER
(
"fs.oss.accessKeyId" = "<oss_access_key>",
"fs.oss.accessKeySecret" = "<oss_secret_key>",
"fs.oss.endpoint" = "<oss_endpoint>"
);
PROPERTIES
(
"timeout" = "3600"
);
查询数据
提交导入作业以后,您可以使用 SELECT * FROM information_schema.loads 来查看 Broker Load 作业的结果,该功能自 3.1 版本起支持,具体请参见本文“查看导入作业”小节。
确认导入作业成功以后,您可以使用 SELECT 语句来查询 table1 和 table2 中的数据:
-
查询
table1的数据,如下所示:SELECT * FROM table1;
+------+-------+-------+
| id | name | score |
+------+-------+-------+
| 1 | Lily | 21 |
| 2 | Rose | 22 |
| 3 | Alice | 23 |
| 4 | Julia | 24 |
+------+-------+-------+
4 rows in set (0.01 sec) -
查询
table2的数据,如下所示:SELECT * FROM table2;
+------+-------+-------+
| id | name | score |
+------+-------+-------+
| 5 | Tony | 25 |
| 6 | Adam | 26 |
| 7 | Allen | 27 |
| 8 | Jacky | 28 |
+------+-------+-------+
4 rows in set (0.01 sec)
从腾讯云 COS 导入
下述命令以 CSV 格式为例。有关如何导入其他格式的数据,参见 BROKER LOAD。
导入单个数据文件到单表
操作示例
通过如下语句,把腾讯云 COS 存储空间 bucket_cos 里 input 文件夹内数据文件 file1.csv 的数据导入到目标表 table1:
LOAD LABEL test_db.label_brokerloadtest_501
(
DATA INFILE("cosn://bucket_cos/input/file1.csv")
INTO TABLE table1
COLUMNS TERMINATED BY ","
(id, name, score)
)
WITH BROKER
(
"fs.cosn.userinfo.secretId" = "<cos_access_key>",
"fs.cosn.userinfo.secretKey" = "<cos_secret_key>",
"fs.cosn.bucket.endpoint_suffix" = "<cos_endpoint>"
)
PROPERTIES
(
"timeout" = "3600"
);
查询数据
提交导入作业以后,您可以使用 SELECT * FROM information_schema.loads 来查看 Broker Load 作业的结果,该功能自 3.1 版本起支持,具体请参见本文“查看��导入作业”小节。
确认导入作业成功以后,您可以使用 SELECT 语句来查询 table1 的数据,如下所示:
SELECT * FROM table1;
+------+-------+-------+
| id | name | score |
+------+-------+-------+
| 1 | Lily | 21 |
| 2 | Rose | 22 |
| 3 | Alice | 23 |
| 4 | Julia | 24 |
+------+-------+-------+
4 rows in set (0.01 sec)
导入多个数据文件到单表
操作示例
通过如下语句,把腾讯云 COS 存储空间 bucket_cos 里 input 文件夹内所有数据文件(file1.csv 和 file2.csv)的数据导入到目标表 table1:
LOAD LABEL test_db.label_brokerloadtest_502
(
DATA INFILE("cosn://bucket_cos/input/*")
INTO TABLE table1
COLUMNS TERMINATED BY ","
(id, name, score)
)
WITH BROKER
(
"fs.cosn.userinfo.secretId" = "<cos_access_key>",
"fs.cosn.userinfo.secretKey" = "<cos_secret_key>",
"fs.cosn.bucket.endpoint_suffix" = "<cos_endpoint>"
)
PROPERTIES
(
"timeout" = "3600"
);
查询数据
提交导入作业以后,您可以使用 SELECT * FROM information_schema.loads 来查看 Broker Load 作业的结果,该功能自 3.1 版本起支持,具体请参见本文“查看导入作业”小节。
确认导入作业成功以后,您可以使用 SELECT 语句来查询 table1 的数据,如下所示:
SELECT * FROM table1;
+------+-------+-------+
| id | name | score |
+------+-------+-------+
| 1 | Lily | 21 |
| 2 | Rose | 22 |
| 3 | Alice | 23 |
| 4 | Julia | 24 |
| 5 | Tony | 25 |
| 6 | Adam | 26 |
| 7 | Allen | 27 |
| 8 | Jacky | 28 |
+------+-------+-------+
4 rows in set (0.01 sec)
导入多个数据文件到多表
操作示例
通过如下语句,把腾讯云 COS 存储空间 bucket_cos 里 input 文件夹内数据文件 file1.csv 和 file2.csv 的数据分别导入到目标表 table1 和 table2:
LOAD LABEL test_db.label_brokerloadtest_503
(
DATA INFILE("cosn://bucket_cos/input/file1.csv")
INTO TABLE table1
COLUMNS TERMINATED BY ","
(id, name, score)
,
DATA INFILE("cosn://bucket_cos/input/file2.csv")
INTO TABLE table2
COLUMNS TERMINATED BY ","
(id, name, score)
)
WITH BROKER
(
"fs.cosn.userinfo.secretId" = "<cos_access_key>",
"fs.cosn.userinfo.secretKey" = "<cos_secret_key>",
"fs.cosn.bucket.endpoint_suffix" = "<cos_endpoint>"
);
PROPERTIES
(
"timeout" = "3600"
);
查询数据
提交导入作业以后,您可以使用 SELECT * FROM information_schema.loads 来查看 Broker Load 作业的结果,该功能自 3.1 版本起支持,具体请参见本文“查看导入作业”小节。
确认导入作业成功以后,您可以使用 SELECT 语句来查询 table1 和 table2 中的数据:
-
查询
table1的数据,如下所示:SELECT * FROM table1;
+------+-------+-------+
| id | name | score |
+------+-------+-------+
| 1 | Lily | 21 |
| 2 | Rose | 22 |
| 3 | Alice | 23 |
| 4 | Julia | 24 |
+------+-------+-------+
4 rows in set (0.01 sec) -
查询
table2的数据,如下所示:SELECT * FROM table2;
+------+-------+-------+
| id | name | score |
+------+-------+-------+
| 5 | Tony | 25 |
| 6 | Adam | 26 |
| 7 | Allen | 27 |
| 8 | Jacky | 28 |
+------+-------+-------+
4 rows in set (0.01 sec)
从华为云 OBS 导入
下述命令以 CSV 格式为例。有关如何导入其他格式的数据,参见 BROKER LOAD。
导入单个数据文件到单表
操作示例
通过如下语句,把华为云 OBS 存储空间 bucket_obs 里 input 文件夹内数据文件 file1.csv 的数据导入到目标表 table1:
LOAD LABEL test_db.label_brokerloadtest_601
(
DATA INFILE("obs://bucket_obs/input/file1.csv")
INTO TABLE table1
COLUMNS TERMINATED BY ","
(id, name, score)
)
WITH BROKER
(
"fs.obs.access.key" = "<obs_access_key>",
"fs.obs.secret.key" = "<obs_secret_key>",
"fs.obs.endpoint" = "<obs_endpoint>"
)
PROPERTIES
(
"timeout" = "3600"
);
查询数据
提交导入作业以后,您可以使用 SELECT * FROM information_schema.loads 来查看 Broker Load 作业的结果,该功能自 3.1 版本起支持,具体请参见本文“查看导入作业”小节。
确认导入作业成功以后,您可以使用 SELECT 语句来查询 table1 的数据,如下所示:
SELECT * FROM table1;
+------+-------+-------+
| id | name | score |
+------+-------+-------+
| 1 | Lily | 21 |
| 2 | Rose | 22 |
| 3 | Alice | 23 |
| 4 | Julia | 24 |
+------+-------+-------+
4 rows in set (0.01 sec)
导入多个数据文件到单表
操作示例
通过如下语句,把华为云 OBS 存储空间 bucket_obs 里 input 文件夹内所有数据文件(file1.csv 和 file2.csv)的数据导入到目标表 table1:
LOAD LABEL test_db.label_brokerloadtest_602
(
DATA INFILE("obs://bucket_obs/input/*")
INTO TABLE table1
COLUMNS TERMINATED BY ","
(id, name, score)
)
WITH BROKER
(
"fs.obs.access.key" = "<obs_access_key>",
"fs.obs.secret.key" = "<obs_secret_key>",
"fs.obs.endpoint" = "<obs_endpoint>"
)
PROPERTIES
(
"timeout" = "3600"
);
查询数据
提交导入作业以后,您可以使用 SELECT * FROM information_schema.loads 来查看 Broker Load 作业的结果,该功能自 3.1 版本起支持,具体请参见本文“查看导入作业”小节。
确认导入作业成功以后,您可以使用 SELECT 语句来查询 table1 的数据,如下所示:
SELECT * FROM table1;
+------+-------+-------+
| id | name | score |
+------+-------+-------+
| 1 | Lily | 21 |
| 2 | Rose | 22 |
| 3 | Alice | 23 |
| 4 | Julia | 24 |
| 5 | Tony | 25 |
| 6 | Adam | 26 |
| 7 | Allen | 27 |
| 8 | Jacky | 28 |
+------+-------+-------+
4 rows in set (0.01 sec)
导入多个数据文件到多表
操作示例
通过如下语句,把华为云 OBS 存储空间 bucket_obs 里 input 文件夹内数据文件 file1.csv 和 file2.csv 的数据分别导入到目标表 table1 和 table2:
LOAD LABEL test_db.label_brokerloadtest_603
(
DATA INFILE("obs://bucket_obs/input/file1.csv")
INTO TABLE table1
COLUMNS TERMINATED BY ","
(id, name, score)
,
DATA INFILE("obs://bucket_obs/input/file2.csv")
INTO TABLE table2
COLUMNS TERMINATED BY ","
(id, name, score)
)
WITH BROKER
(
"fs.obs.access.key" = "<obs_access_key>",
"fs.obs.secret.key" = "<obs_secret_key>",
"fs.obs.endpoint" = "<obs_endpoint>"
);
PROPERTIES
(
"timeout" = "3600"
);
查询数据
提交导入作业以后,您可以使用 SELECT * FROM information_schema.loads 来查看 Broker Load 作业的结果,该功能自 3.1 版本起支持,具体请参见本文“查看导入作业”小节。
确认导入作业成功以后,您可以使用 SELECT 语句来查询 table1 和 table2 中的数据:
-
查询
table1的数据,如下所示:SELECT * FROM table1;
+------+-------+-------+
| id | name | score |
+------+-------+-------+
| 1 | Lily | 21 |
| 2 | Rose | 22 |
| 3 | Alice | 23 |
| 4 | Julia | 24 |
+------+-------+-------+
4 rows in set (0.01 sec) -
查询
table2的数据,如下所示:SELECT * FROM table2;
+------+-------+-------+
| id | name | score |
+------+-------+-------+
| 5 | Tony | 25 |
| 6 | Adam | 26 |
| 7 | Allen | 27 |
| 8 | Jacky | 28 |
+------+-------+-------+
4 rows in set (0.01 sec)
从其他兼容 S3 协议的对象存储导入
下述命令以 CSV 格式和 MinIO 存储为例。有关如何导入其他格式的数据,参见 BROKER LOAD。
导入单个数据文件到单表
操作示例
通过如下语句,把 MinIO 存储空间 bucket_minio 里 input 文件夹内数据文件 file1.csv 的数据导入到目标表 table1:
LOAD LABEL test_db.label_brokerloadtest_701
(
DATA INFILE("s3://bucket_minio/input/file1.csv")
INTO TABLE table1
COLUMNS TERMINATED BY ","
(id, name, score)
)
WITH BROKER
(
"aws.s3.enable_ssl" = "false",
"aws.s3.enable_path_style_access" = "true",
"aws.s3.endpoint" = "<s3_endpoint>",
"aws.s3.access_key" = "<iam_user_access_key>",
"aws.s3.secret_key" = "<iam_user_secret_key>"
)
PROPERTIES
(
"timeout" = "3600"
);
查询数据
提交导入作业以后,您可以使用 SELECT * FROM information_schema.loads 来查看 Broker Load 作业�的结果,该功能自 3.1 版本起支持,具体请参见本文“查看导入作业”小节。
确认导入作业成功以后,您可以使用 SELECT 语句来查询 table1 的数据,如下所示:
SELECT * FROM table1;
+------+-------+-------+
| id | name | score |
+------+-------+-------+
| 1 | Lily | 21 |
| 2 | Rose | 22 |
| 3 | Alice | 23 |
| 4 | Julia | 24 |
+------+-------+-------+
4 rows in set (0.01 sec)
导入多个数据文件到单表
操作示例
通过如下语句,把 MinIO 存储空间 bucket_minio 里 input 文件夹内所有数据文件(file1.csv 和 file2.csv)的数据导入到目标表 table1:
LOAD LABEL test_db.label_brokerloadtest_702
(
DATA INFILE("s3://bucket_minio/input/*")
INTO TABLE table1
COLUMNS TERMINATED BY ","
(id, name, score)
)
WITH BROKER
(
"aws.s3.enable_ssl" = "false",
"aws.s3.enable_path_style_access" = "true",
"aws.s3.endpoint" = "<s3_endpoint>",
"aws.s3.access_key" = "<iam_user_access_key>",
"aws.s3.secret_key" = "<iam_user_secret_key>"
)
PROPERTIES
(
"timeout" = "3600"
);
查询数据
提交导入作业以后,您可以使用 SELECT * FROM information_schema.loads 来查看 Broker Load 作业的结果,该功能自 3.1 版本起支持,具体请参见本文“查看导入作业”小节。
确认导入作业成功以后,您可以使用 SELECT 语句来查询 table1 的数据,如下所示:
SELECT * FROM table1;
+------+-------+-------+
| id | name | score |
+------+-------+-------+
| 1 | Lily | 21 |
| 2 | Rose | 22 |
| 3 | Alice | 23 |
| 4 | Julia | 24 |
| 5 | Tony | 25 |
| 6 | Adam | 26 |
| 7 | Allen | 27 |
| 8 | Jacky | 28 |
+------+-------+-------+
4 rows in set (0.01 sec)
导入多个数据文件到多表
操作示例
通过如下语句,把 MinIO 存储空间 bucket_minio 里 input 文件夹内数据文件 file1.csv 和 file2.csv 的数据分别导入到目标表 table1 和 table2:
LOAD LABEL test_db.label_brokerloadtest_703
(
DATA INFILE("s3://bucket_minio/input/file1.csv")
INTO TABLE table1
COLUMNS TERMINATED BY ","
(id, name, score)
,
DATA INFILE("s3://bucket_minio/input/file2.csv")
INTO TABLE table2
COLUMNS TERMINATED BY ","
(id, name, score)
)
WITH BROKER
(
"aws.s3.enable_ssl" = "false",
"aws.s3.enable_path_style_access" = "true",
"aws.s3.endpoint" = "<s3_endpoint>",
"aws.s3.access_key" = "<iam_user_access_key>",
"aws.s3.secret_key" = "<iam_user_secret_key>"
);
PROPERTIES
(
"timeout" = "3600"
);
查询数据
提交导入作业以后,您可以使用 SELECT * FROM information_schema.loads 来查看 Broker Load 作业的结果,该功能自 3.1 版本起支持,具体请参见本文“查看导入作业”小节。
确认导入作业成功以后,您可以使用 SELECT 语句来查询 table1 和 table2 中的数据:
-
查询
table1的数据,如下所示:SELECT * FROM table1;
+------+-------+-------+
| id | name | score |
+------+-------+-------+
| 1 | Lily | 21 |
| 2 | Rose | 22 |
| 3 | Alice | 23 |
| 4 | Julia | 24 |
+------+-------+-------+
4 rows in set (0.01 sec) -
查询
table2的数据,如下所示:SELECT * FROM table2;
+------+-------+-------+
| id | name | score |
+------+-------+-------+
| 5 | Tony | 25 |
| 6 | Adam | 26 |
| 7 | Allen | 27 |
| 8 | Jacky | 28 |
+------+-------+-------+
4 rows in set (0.01 sec)
查看导入作业
通过 SELECT 语句从 information_schema 数据库中的 loads 表来查看 Broker Load 作业的结果。该功能自 3.1 版本起支持。
示例一:通过如下命令查看 test_db 数据库中导入作业的执行情况,同时指定查询结果根据作业创建时间 (CREATE_TIME) 按降序排列,并且最多显示两条结果数据:
SELECT * FROM information_schema.loads
WHERE database_name = 'test_db'
ORDER BY create_time DESC
LIMIT 2\G
返回结果如下所示:
*************************** 1. row ***************************
JOB_ID: 20686
LABEL: label_brokerload_unqualifiedtest_83
DATABASE_NAME: test_db
STATE: FINISHED
PROGRESS: ETL:100%; LOAD:100%
TYPE: BROKER
PRIORITY: NORMAL
SCAN_ROWS: 8
FILTERED_ROWS: 0
UNSELECTED_ROWS: 0
SINK_ROWS: 8
ETL_INFO:
TASK_INFO: resource:N/A; timeout(s):14400; max_filter_ratio:1.0
CREATE_TIME: 2023-08-02 15:25:22
ETL_START_TIME: 2023-08-02 15:25:24
ETL_FINISH_TIME: 2023-08-02 15:25:24
LOAD_START_TIME: 2023-08-02 15:25:24
LOAD_FINISH_TIME: 2023-08-02 15:25:27
JOB_DETAILS: {"All backends":{"77fe760e-ec53-47f7-917d-be5528288c08":[10006],"0154f64e-e090-47b7-a4b2-92c2ece95f97":[10005]},"FileNumber":2,"FileSize":84,"InternalTableLoadBytes":252,"InternalTableLoadRows":8,"ScanBytes":84,"ScanRows":8,"TaskNumber":2,"Unfinished backends":{"77fe760e-ec53-47f7-917d-be5528288c08":[],"0154f64e-e090-47b7-a4b2-92c2ece95f97":[]}}
ERROR_MSG: NULL
TRACKING_URL: NULL
TRACKING_SQL: NULL
REJECTED_RECORD_PATH: NULL
*************************** 2. row ***************************
JOB_ID: 20624
LABEL: label_brokerload_unqualifiedtest_82
DATABASE_NAME: test_db
STATE: FINISHED
PROGRESS: ETL:100%; LOAD:100%
TYPE: BROKER
PRIORITY: NORMAL
SCAN_ROWS: 12
FILTERED_ROWS: 4
UNSELECTED_ROWS: 0
SINK_ROWS: 8
ETL_INFO:
TASK_INFO: resource:N/A; timeout(s):14400; max_filter_ratio:1.0
CREATE_TIME: 2023-08-02 15:23:29
ETL_START_TIME: 2023-08-02 15:23:34
ETL_FINISH_TIME: 2023-08-02 15:23:34
LOAD_START_TIME: 2023-08-02 15:23:34
LOAD_FINISH_TIME: 2023-08-02 15:23:34
JOB_DETAILS: {"All backends":{"78f78fc3-8509-451f-a0a2-c6b5db27dcb6":[10010],"a24aa357-f7de-4e49-9e09-e98463b5b53c":[10006]},"FileNumber":2,"FileSize":158,"InternalTableLoadBytes":333,"InternalTableLoadRows":8,"ScanBytes":158,"ScanRows":12,"TaskNumber":2,"Unfinished backends":{"78f78fc3-8509-451f-a0a2-c6b5db27dcb6":[],"a24aa357-f7de-4e49-9e09-e98463b5b53c":[]}}
ERROR_MSG: NULL
TRACKING_URL: http://172.26.195.69:8540/api/_load_error_log?file=error_log_78f78fc38509451f_a0a2c6b5db27dcb7
TRACKING_SQL: select tracking_log from information_schema.load_tracking_logs where job_id=20624
REJECTED_RECORD_PATH: 172.26.95.92:/home/disk1/sr/be/storage/rejected_record/test_db/label_brokerload_unqualifiedtest_0728/6/404a20b1e4db4d27_8aa9af1e8d6d8bdc
示例二:通过如下命令查看 test_db 数据库中标签为 label_brokerload_unqualifiedtest_82 的导入作业的执行情况:
SELECT * FROM information_schema.loads
WHERE database_name = 'test_db' and label = 'label_brokerload_unqualifiedtest_82'\G
返回结果如下所示:
*************************** 1. row ***************************
JOB_ID: 20624
LABEL: label_brokerload_unqualifiedtest_82
DATABASE_NAME: test_db
STATE: FINISHED
PROGRESS: ETL:100%; LOAD:100%
TYPE: BROKER
PRIORITY: NORMAL
SCAN_ROWS: 12
FILTERED_ROWS: 4
UNSELECTED_ROWS: 0
SINK_ROWS: 8
ETL_INFO:
TASK_INFO: resource:N/A; timeout(s):14400; max_filter_ratio:1.0
CREATE_TIME: 2023-08-02 15:23:29
ETL_START_TIME: 2023-08-02 15:23:34
ETL_FINISH_TIME: 2023-08-02 15:23:34
LOAD_START_TIME: 2023-08-02 15:23:34
LOAD_FINISH_TIME: 2023-08-02 15:23:34
JOB_DETAILS: {"All backends":{"78f78fc3-8509-451f-a0a2-c6b5db27dcb6":[10010],"a24aa357-f7de-4e49-9e09-e98463b5b53c":[10006]},"FileNumber":2,"FileSize":158,"InternalTableLoadBytes":333,"InternalTableLoadRows":8,"ScanBytes":158,"ScanRows":12,"TaskNumber":2,"Unfinished backends":{"78f78fc3-8509-451f-a0a2-c6b5db27dcb6":[],"a24aa357-f7de-4e49-9e09-e98463b5b53c":[]}}
ERROR_MSG: NULL
TRACKING_URL: http://172.26.195.69:8540/api/_load_error_log?file=error_log_78f78fc38509451f_a0a2c6b5db27dcb7
TRACKING_SQL: select tracking_log from information_schema.load_tracking_logs where job_id=20624
REJECTED_RECORD_PATH: 172.26.95.92:/home/disk1/sr/be/storage/rejected_record/test_db/label_brokerload_unqualifiedtest_0728/6/404a20b1e4db4d27_8aa9af1e8d6d8bdc
有关返回字段的说明,参见 information_schema.loads。
取消导入作业
当导入作业状态不为 CANCELLED 或 FINISHED 时,可以通过 CANCEL LOAD 语句来取消该导入作业。
例如,可以通过以下语句,撤销 test_db 数据库中标签为 label1 的导入作业:
CANCEL LOAD
FROM test_db
WHERE LABEL = "label1";
作业拆分与并行执行
一个 Broker Load 作业会拆分成一个或者多个子任务并行处理,一个作业的所有子任务作为一个事务整体成功或失败。作业的拆分通过 LOAD LABEL 语句中的 data_desc 参数来指定:
-
如果声明多个
data_desc参数对应导入多张不同的表,则每张表数据的导入会拆分成一个子任务。 -
如果声明多个
data_desc参数对应导入同一张表的不同分区,则每个分区数据的导入会拆分成一个子任务。
每个子任务还会拆分成一个或者多个实例,然后这些实例会均匀地被分配到 BE(或 CN)上并行执行。实例的拆分由 FE 配置参数 min_bytes_per_broker_scanner 和 BE(或 CN)节点数量决定,可以使用如下公式计算单个子任务的实例总数:
单个子任务的实例总数 = min(单个子任务待导入数据量的总大小/min_bytes_per_broker_scanner, BE/CN 节点数量)
一般情况下,一个导入作业只有一个 data_desc,只会拆分成一个子任务,子任务会拆分成与 BE(或 CN)节点数量相等的实例。
常见问题
请参见 Broker Load 常见问题。