クエリプラン
クエリパフォーマンスの最適化は、分析システムにおける一般的な課題です。クエリが遅いと、ユーザーエクスペリエンスやクラスタ全体のパフォーマンスに悪影響を及ぼす可能性があります。StarRocksでは、クエリプランとクエリプロファイルを理解し解釈することが、遅いクエリを診断し改善するための基盤となります。これらのツールは以下のことに役立ちます。
- ボトルネックや高コストの操作を特定する
- 最適でないジョイン戦略やインデックスの欠如を見つける
- データがどのようにフィルタリング、集計、移動されるかを理解する
- リソース使用のトラブルシューティングと最適化
クエリプランは、StarRocks FE によって生成される詳細なロードマップで、SQL ステートメントがどのように実行されるかを説明します。クエリをスキャン、ジョイン、集計、ソートなどの一連の操作に分解し、それらを最も効率的に実行する方法を決定します。
StarRocks はクエリプランを確認するためのいくつかの方法を提供しています。
-
EXPLAIN ステートメント:
EXPLAINを使用して、クエリの論理または物理的な実行プランを表示します。出力を制御するオプションを追加できます。EXPLAIN LOGICAL <query>: 簡略化されたプランを表示します。EXPLAIN <query>: 基本的な物理プランを表示します。EXPLAIN VERBOSE <query>: 詳細情報を含む物理プランを表示します。EXPLAIN COSTS <query>: 各操作の推定コストを含み、統計の問題を診断するために使用されます。
-
EXPLAIN ANALYZE:
EXPLAIN ANALYZE <query>を使用してクエリを実行し、実際の実行プランと実行時の統計情報を表示します。詳細は Explain Anlayze ドキュメントを参照してください。例:
EXPLAIN ANALYZE SELECT * FROM sales_orders WHERE amount > 1000; -
Query Profile:
クエリを実行した後、その詳細な実行プロファイルを表示できます。これには、タイミング、リソース使用量、オペレーター レベルの統計が含まれます。詳細情報のアクセスと解釈については Query Profile ドキュメントを参照してください。- SQL コマンド:
SHOW PROFILELISTおよびANALYZE PROFILE FOR <query_id>を使用して、特定のクエリの実行プロファイルを取得できます。 - FE HTTP サービス: StarRocks FE の Web UI で Query または Profile セクションに移動して、クエリの実行詳細を検索および確認できます。
- マネージドバージョン: クラウドまたはマネージドデプロイメントでは、提供された Web コンソールまたはモニタリングダッシュボードを使用して、クエリプランとプロファイルを表示できます。多くの場合、視覚化やフィルタリングオプションが強化されています。
- SQL コマンド:
通常、クエリプランはクエリの計画と最適化に関連する問題を診断するために使用され、クエリプロファイルはクエリ実行中のパフォーマンス問題を特定するのに役立ちます。以下のセクションでは、クエリ実行の主要な概念を探り、クエリプランを分析する具体的な例を紹介します。
クエリ実行フロー
StarRocks におけるクエリのライフサイクルは、主に3つのフェーズで構成されています。
- 計画: クエリは解析、分析、最適化を経て、クエリプランの生成に至ります。
- スケジューリング: スケジューラとコーディネータがプランをすべての参加バックエンドノードに分配します。
- 実行: プランはパイプライン実行エンジンを使用して実行されます。
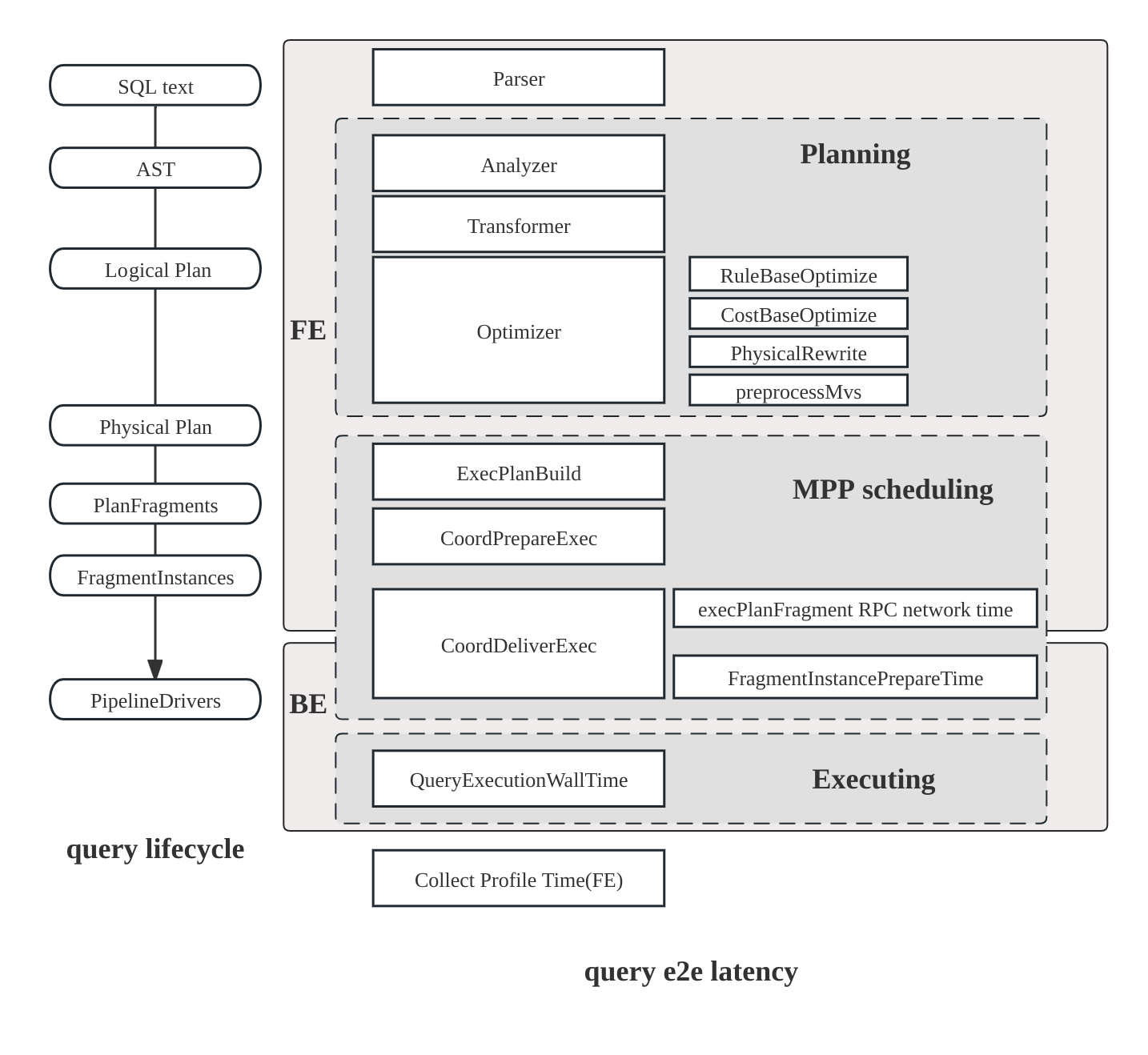
プラン構造
StarRocks のプランは階層的です。
- フラグメント: 最上位の作業スライスで、各フラグメントは異なるバックエンドノードで実行される複数の FragmentInstances を生成します。
- パイプライン: インスタンス内で、パイプラインはオペレーターを連結し、複数の PipelineDrivers が同じパイプラインを別々の CPU コアで同時に実行します。
- オペレーター: データを実際に処理するスキャン、ジョイン、集計などの基本的なステップです。
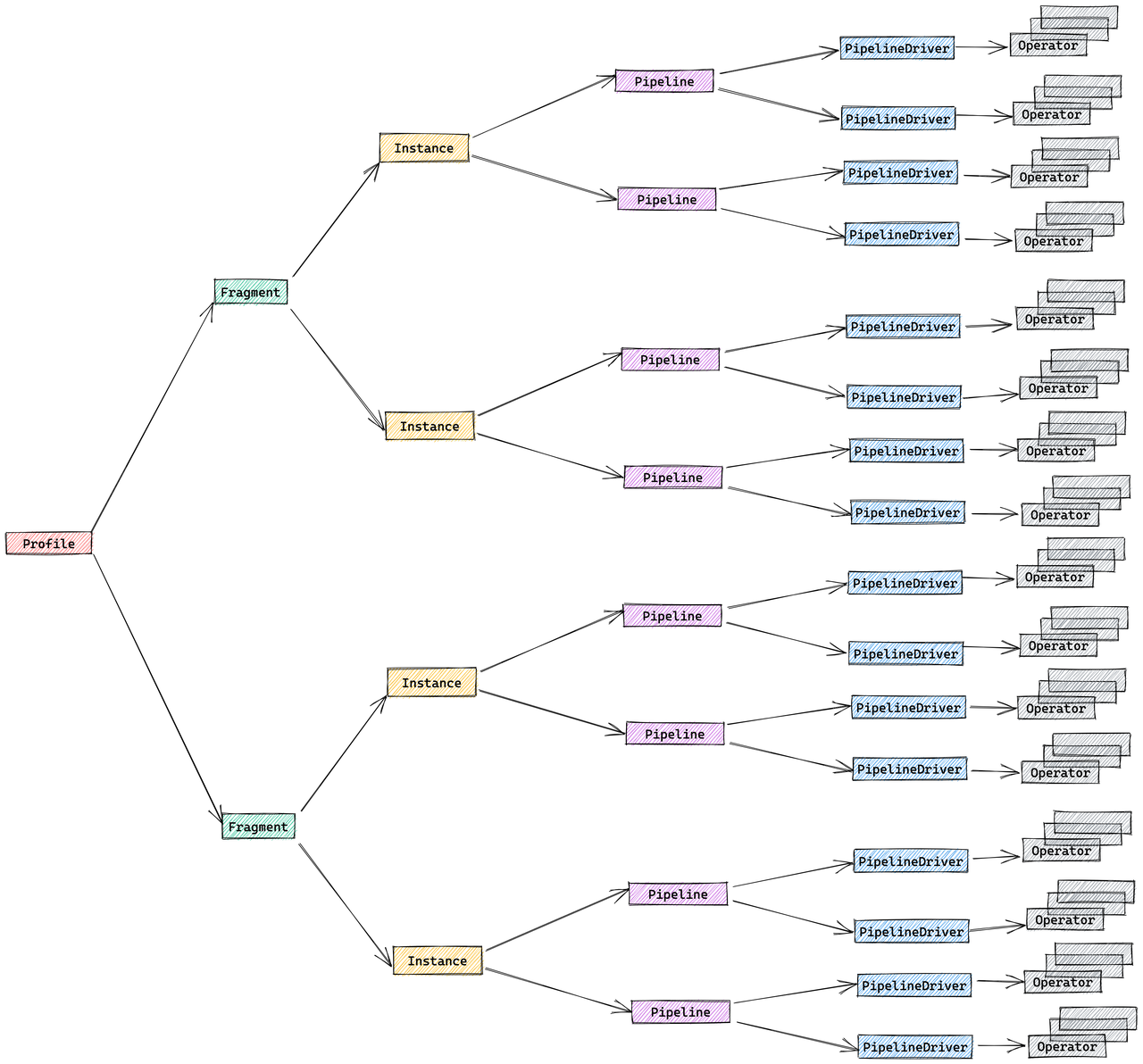
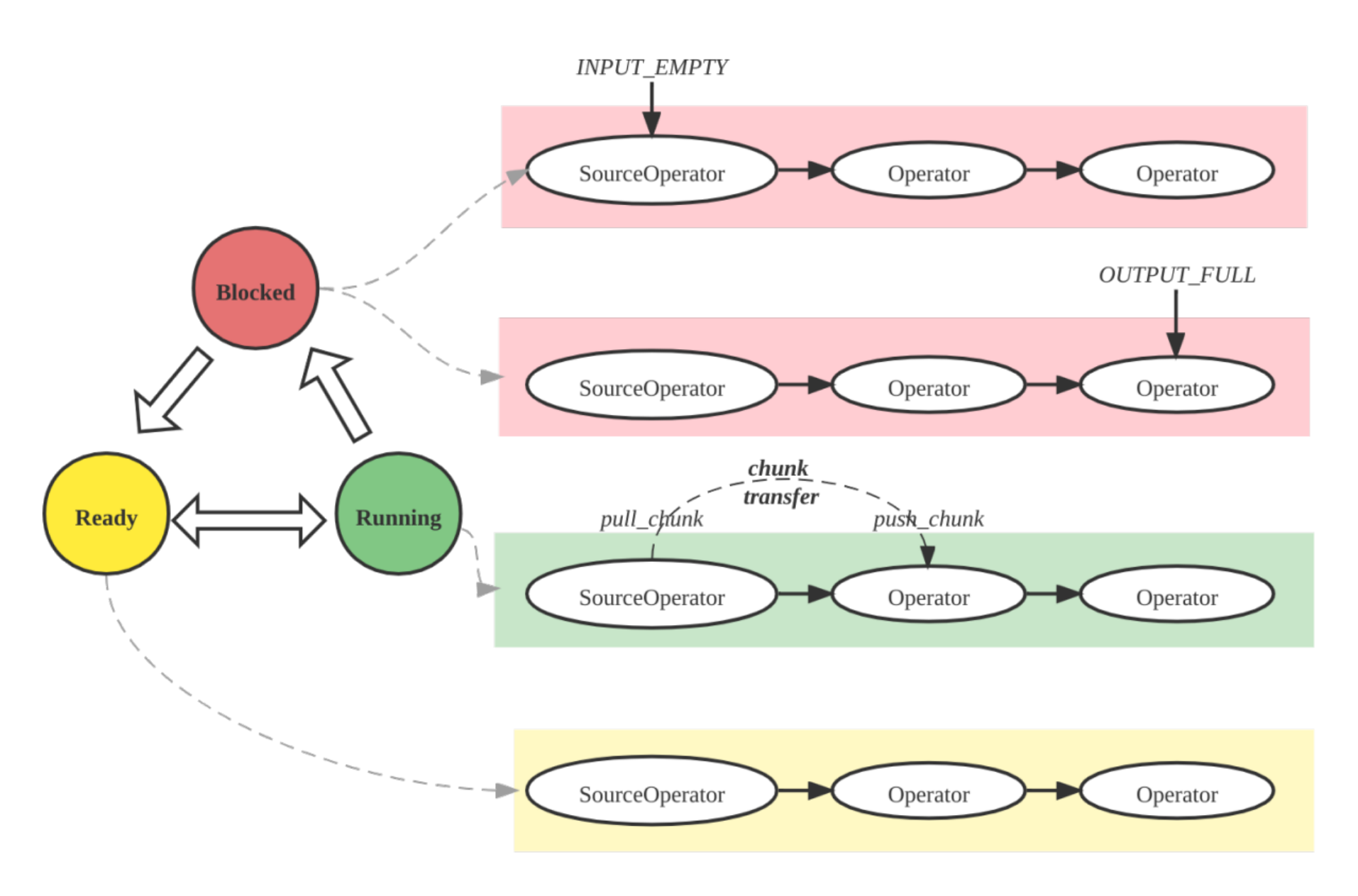
パイプライン実行エンジン
パイプラインエンジンは、クエリプランを並列かつ効率的に実行し、複雑なプランや大規模なデータ量を高パフォーマンスかつスケーラブルに処理します。
メトリックマージ戦略
デフォルトでは、StarRocks はプロファイルのボリュームを削減するために FragmentInstance と PipelineDriver レイヤーをマージし、簡略化された3層構造を生成します。
- フラグメント
- パイプライン
- オペレーター
このマージ動作は、セッション変数 pipeline_profile_level を通じて制御できます。
例
クエリプランとプロファイルの読み方
-
構造を理解する: クエリプランはフラグメントに分割され、それぞれが実行のステージを表します。下から上に読みます: まずスキャンノード、次にジョイン、集計、そして最終的に結果です。
-
全体的な分析:
- 総実行時間、メモリ使用量、CPU/ウォールタイム比を確認します。
- オペレーター時間でソートして遅いオペレーターを見つけます。
- フィルターが可能な限りプッシュダウンされていることを確認します。
- データの偏り(オペレーター時間や行数の不均一)を探します。
- 高いメモリ使用量やディスクスピルを監視し、ジョイン順序を調整したり、ロールアップビューを使用したりします。
- 必要に応じてマテリアライズドビューやクエリヒント(
BROADCAST、SHUFFLE、COLOCATE)を使用して最適化します。
-
スキャン操作:
OlapScanNodeまたは類似のものを探します。どのテーブルがスキャンされ、どのフィルターが適用され、事前集計やマテリアライズドビューが使用されているかを確認します。 -
ジョイン操作: ジョインタイプ(
HASH JOIN、BROADCAST、SHUFFLE、COLOCATE、BUCKET SHUFFLE)を特定します。ジョイン方法はパフォーマンスに影響します。- Broadcast: 小さなテーブルをすべてのノードに送信します。�小さなテーブルに適しています。
- Shuffle: 行をパーティション分割してシャッフルします。大きなテーブルに適しています。
- Colocate: テーブルが同じ方法でパーティション分割されているため、ローカルジョインを可能にします。
- Bucket Shuffle: ネットワークコストを削減するために、1つのテーブルのみをシャッフルします。
-
集計とソート:
AGGREGATE、TOP-N、またはORDER BYを探します。これらは大規模または高カーディナリティのデータで高コストになる可能性があります。 -
データ移動:
EXCHANGEノードはフラグメントまたはノード間のデータ転送を示します。データ移動が多すぎるとパフォーマンスに悪影響を及ぼす可能性があります。 -
述語プッシュダウン: スキャン時に適用されるフィルターは、下流のデータを削減します。
PREDICATESまたはPushdownPredicatesを確認して、どのフィルターがプッシュダウンされているかを確認します。
クエリプランの例
これは、TPC-DS ベンチマークからのクエリ 96 です。
explain logical
select count(*)
from store_sales
,household_demographics
,time_dim
, store
where ss_sold_time_sk = time_dim.t_time_sk
and ss_hdemo_sk = household_demographics.hd_demo_sk
and ss_store_sk = s_store_sk
and time_dim.t_hour = 8
and time_dim.t_minute >= 30
and household_demographics.hd_dep_count = 5
and store.s_store_name = 'ese'
order by count(*) limit 100;
出力は、StarRocks がクエリをどのように実行するかを示す階層的なプランです。プランはオペレーターのツリー構造で、下から上に読むことができます。論理プランは、コスト見積もりを含む操作のシーケンスを示します:
- Output => [69:count]
- TOP-100(FINAL)[69: count ASC NULLS FIRST]
Estimates: {row: 1, cpu: 8.00, memory: 8.00, network: 8.00, cost: 68669801.20}
- TOP-100(PARTIAL)[69: count ASC NULLS FIRST]
Estimates: {row: 1, cpu: 8.00, memory: 8.00, network: 8.00, cost: 68669769.20}
- AGGREGATE(GLOBAL) []
Estimates: {row: 1, cpu: 8.00, memory: 8.00, network: 0.00, cost: 68669737.20}
69:count := count(69:count)
- EXCHANGE(GATHER)
Estimates: {row: 1, cpu: 8.00, memory: 0.00, network: 8.00, cost: 68669717.20}
- AGGREGATE(LOCAL) []
Estimates: {row: 1, cpu: 3141.35, memory: 0.80, network: 0.00, cost: 68669701.20}
69:count := count()
- HASH/INNER JOIN [9:ss_store_sk = 40:s_store_sk] => [71:auto_fill_col]
Estimates: {row: 3490, cpu: 111184.52, memory: 8.80, network: 0.00, cost: 68668128.93}
71:auto_fill_col := 1
- HASH/INNER JOIN [7:ss_hdemo_sk = 25:hd_demo_sk] => [9:ss_store_sk]
Estimates: {row: 19940, cpu: 1841177.20, memory: 2880.00, network: 0.00, cost: 68612474.92}
- HASH/INNER JOIN [4:ss_sold_time_sk = 30:t_time_sk] => [7:ss_hdemo_sk, 9:ss_store_sk]
Estimates: {row: 199876, cpu: 69221191.15, memory: 7077.97, network: 0.00, cost: 67671726.32}
- SCAN [store_sales] => [4:ss_sold_time_sk, 7:ss_hdemo_sk, 9:ss_store_sk]
Estimates: {row: 5501341, cpu: 66016092.00, memory: 0.00, network: 0.00, cost: 33008046.00}
partitionRatio: 1/1, tabletRatio: 192/192
predicate: 7:ss_hdemo_sk IS NOT NULL
- EXCHANGE(BROADCAST)
Estimates: {row: 1769, cpu: 7077.97, memory: 7077.97, network: 7077.97, cost: 38928.81}
- SCAN [time_dim] => [30:t_time_sk]
Estimates: {row: 1769, cpu: 21233.90, memory: 0.00, network: 0.00, cost: 10616.95}
partitionRatio: 1/1, tabletRatio: 5/5
predicate: 33:t_hour = 8 AND 34:t_minute >= 30
- EXCHANGE(BROADCAST)
Estimates: {row: 720, cpu: 2880.00, memory: 2880.00, network: 2880.00, cost: 14400.00}
- SCAN [household_demographics] => [25:hd_demo_sk]
Estimates: {row: 720, cpu: 5760.00, memory: 0.00, network: 0.00, cost: 2880.00}
partitionRatio: 1/1, tabletRatio: 1/1
predicate: 28:hd_dep_count = 5
- EXCHANGE(BROADCAST)
Estimates: {row: 2, cpu: 8.80, memory: 8.80, network: 8.80, cost: 44.15}
- SCAN [store] => [40:s_store_sk]
Estimates: {row: 2, cpu: 17.90, memory: 0.00, network: 0.00, cost: 8.95}
partitionRatio: 1/1, tabletRatio: 1/1
predicate: 45:s_store_name = 'ese'
プランを下から上に読む
クエリプランは、データフローに従って、底部(リーフノード)から上部(ルートノード)に向かって読む必要があります。
-
スキャン操作(下位レベル): 下部の
SCANオペレーターがベーステーブルからデータを読み取ります:SCAN [store_sales]は、述語ss_hdemo_sk IS NOT NULLでメインファクトテーブルを読み取りますSCAN [time_dim]は、述語t_hour = 8 AND t_minute >= 30で時間ディメンションテーブルを読み取りますSCAN [household_demographics]は、述語hd_dep_count = 5で人口統計テーブルを読み取りますSCAN [store]は、述語s_store_name = 'ese'でストアテーブルを読み取ります
各スキャン操作には以下が表示されます:
- 見積もり: 行数、CPU、メモリ、ネットワーク、コストの見積もり
- パーティションとタブレット比率: スキャンされるパーティション/タブレットの数(例:
partitionRatio: 1/1, tabletRatio: 192/192) - 述語: スキャンレベルにプッシュダウンされるクエリ条件で、読み取るデータ量を削減します
-
データ交換(ブロードキャスト):
EXCHANGE(BROADCAST)操作は、小さなディメンションテーブルを、大きなファクトテーブルを処理するすべてのノードに配布します。time_dim、household_demographics、storeがブロードキャストされるように、��ディメンションテーブルがファクトテーブルと比較して小さい場合、これは効率的です。 -
ジョイン操作(中間レベル): データは
HASH/INNER JOIN操作を通じて上向きに流れます:- 最初に、
store_salesがss_sold_time_sk = t_time_skでtime_dimとジョインされます - 次に、結果が
ss_hdemo_sk = hd_demo_skでhousehold_demographicsとジョインされます - 最後に、結果が
ss_store_sk = s_store_skでstoreとジョインされます
各ジョインには、ジョイン条件と結果の行数およびリソース使用量の見積もりが表示されます。
- 最初に、
-
集計(上位レベル):
AGGREGATE(LOCAL)は各ノードでローカル集計を実行し、count()を計算しますEXCHANGE(GATHER)はすべてのノードから結果を収集しますAGGREGATE(GLOBAL)はローカル結果を最終カウントにマージします
-
最終操作(最上位レベル):
TOP-100(PARTIAL)とTOP-100(FINAL)操作はORDER BY count(*) LIMIT 100句を処理し、並べ替え後に上位100の結果を選択します
論理プランは各操作のコスト見積もりを提供し、クエリがリソースの大部分をどこで消費するかを理解するのに役立ちます。実際の物理実行プラン(EXPLAIN または EXPLAIN VERBOSE から)には、操作がノード間でどのように分散され、並列実行されるかに関する追加の詳細が含まれます。
