主キーテーブル
主キーテーブルは、StarRocks によって設計された新しいストレージエンジンを使用しています。その主な利点は、リアルタイムのデータ更新をサポートしながら、複雑なアドホッククエリに対して効率的なパフォーマンスを確保することにあります。リアルタイムのビジネス分析では、主キーテーブルを使用することで、最新のデータを用いてリアルタイムで結果を分析し、データ分析におけるデータ遅延を軽減することができます。しかし、主キーは万能ではありません。不適切に使用すると、リソースの無駄遣いにつながる可能性があります。
したがって、このセクションでは、主キーのモデルをより効率的に使用して、望ましい結果を達成する方法を案内します。
主キーインデックスの選択
主インデックスは、主キーテーブルの最も重要なコンポーネントです。主キーインデックスは、主キー値と、主キー値によって識別されるデータ行の位置との間のマッピングを格納するために使用されます。
現在、3 種類の主キーインデックスをサポートしています。
- メモリ内フル主キーインデックス。
PROPERTIES (
"enable_persistent_index" = "false"
);
- ローカルディスクベースの永続性主キーインデックス。
PROPERTIES (
"enable_persistent_index" = "true",
"persistent_index_type" = "LOCAL"
);
- クラウドネイティブ永続性主キーインデックス。
PROPERTIES (
"enable_persistent_index" = "true",
"persistent_index_type" = "CLOUD_NATIVE"
);
メモリ内インデックスの使用は推奨しません。これは、メモリリソースの大幅な無駄遣いにつながる可能性があるためです。
共有データ(エラスティック)StarRocks クラスタを使用している場合は、クラウドネイティブ永続性主インデックスを選択することをお勧めします。ローカルディスクベースの永続性主インデックスとは異なり、完全なインデックスデータをリモートオブジェクトストレージに格納し、ローカルディスクはキャッシュとしてのみ機能します。ローカルディスクベースの永続性主インデックスと比較して、その利点は次のとおりです。
- ローカルディスク容量に依存しない。
- データシャードのリバランス後にインデックスを再��構築する必要がない。
主キーの選択
主キーは通常、クエリを高速化するのに役立ちません。ORDER BY句を使用して、主キーとは異なる列をソートキーとして指定し、クエリを高速化することができます。したがって、主キーを選択する際には、データのインポートおよび更新プロセス中の一意性のみを考慮する必要があります。
主キーが大きいほど、メモリ、I/O、およびその他のリソースを多く消費します。したがって、一般的には、あまりにも多くの列や過度に大きな列を主キーとして選択することは避けることが推奨されます。主キーのデフォルトの最大サイズは 128 バイトで、be.conf の primary_key_limit_size パラメータによって制御されます。
primary_key_limit_size を増やしてより大きな主キーを選択することができますが、これによりリソース消費が増加することに注意してください。
永続性インデックスがどのくらいのストレージとメモリスペースを占有するか?
ストレージスペースコストの計算式
(key size + 8 bytes) * row count * 50%
50% は推定圧縮効率であり、実際の圧縮効果はデータ自体に依存します。
メモリコストの計算式
min(l0_max_mem_usage * tablet cnt, update_memory_limit_percent * BE process memory);
メモリ使用量
主キーテーブルによって使用されるメモリは、mem_tracker によって監視できます。
//全体のメモリ統計を表示
http://be_ip:be_http_port/mem_tracker
// 主キーテーブルのメモリ統計を表示
http://be_ip:be_http_port/mem_tracker?type=update
// 詳細を含む主キーテーブルのメモリ統計を表示
http://be_ip:be_http_port/mem_tracker?type=update&upper_level=4
mem_tracker の update 項目は、主キーインデックス、Delete Vector など、主キーテーブルによって使用される全メモリを記録します。この update 項目は、メトリクスモニターサービスを通じて監視することもできます。たとえば、Grafana では、次のように update 項目を確認できます(赤枠内の項目):
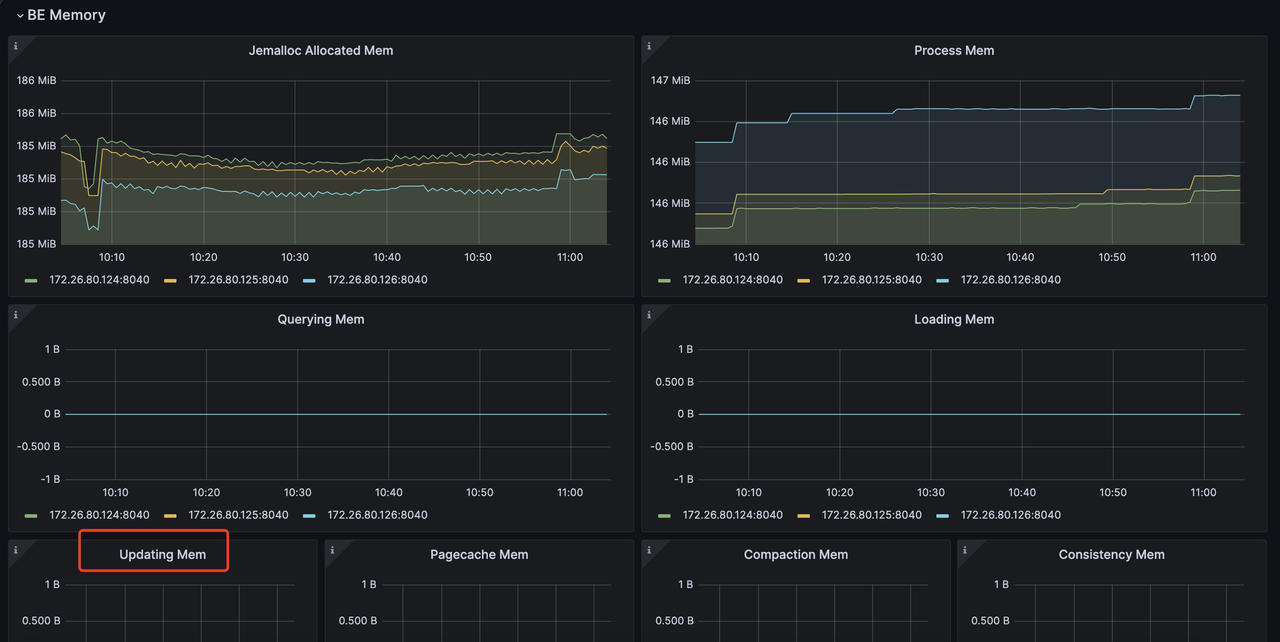
Prometheus と Grafana を使用したモニタリングとアラートについての詳細: https://docs.starrocks.io/docs/administration/management/monitoring/Monitor_and_Alert/
メモリ使用量に敏感で、PK テーブルのインポートプロセス中のメモリ消費を削減したい場合は、次の設定を通じてこれを達成できます。
be.conf
l0_max_mem_usage = (104857600 より小さい値、デフォルトは 104857600)
skip_pk_preload = true
// 共有なしクラスタ
transaction_apply_worker_count = (CPU コア数より小さい値、デフォルトは CPU コア数)
// 共有データクラスタ
transaction_publish_version_worker_count = (CPU コア数より小さい値、デフォルトは CPU コア数)
l0_max_mem_usage は、各 tablet の永続性主キーインデックスの�最大メモリ使用量を制御します。transaction_apply_worker_count と transaction_publish_version_worker_count は、主キーテーブルでの upsert と delete を処理するために使用できる最大スレッド数を制御します。
ただし、l0_max_mem_usage を削減すると I/O の負荷が増加する可能性があり、transaction_apply_worker_count または transaction_publish_version_worker_count を減少させるとデータ取り込みが遅くなる可能性があることを覚えておいてください。
Compaction リソース、データの新鮮さ、クエリ遅延のトレードオフ
他のモデルのテーブルと比較して、主キーテーブルは、データのインポート、更新、および削除中に主キーインデックスの検索と Delete Vector の生成のための追加の操作を必要とし、追加のリソースオーバーヘッドを導入します。したがって、これらの 3 つの要素の間でトレードオフを行う必要があります。
- Compaction リソースの制限。
- データの新鮮さ
- クエリ遅延
データの新鮮さとクエリ遅延
データの新鮮さとクエリ遅延の両方を改善したい場合、それは高頻度の書き込みを導入し、それらができるだけ早く圧縮されることを確認したいことを意味します。したがって、これらの書き込みを処理するためにより多くの Compaction リソースが必要になります。
// 共有データ
be.conf
compact_threads = 4
// 共有なし
be.conf
update_compaction_num_threads_per_disk = 1
update_compaction_per_tablet_min_interval_seconds = 120
compact_threads と update_compaction_num_threads_per_disk を増やすか、update_compaction_per_tablet_min_interval_seconds を減少させて、高頻度の書き込みを処理するためにより多くの Compaction リソースを導入することができます。
現在の Compaction リソースと設定が現在の高頻度の書き込みを処理できるかどうかを知るには、次の方法で観察できます。
- 共有データクラスタの場合、Compaction が取り込み速度に追いつかない場合、取り込みの遅延や書き込みエラー、取り込みの停止が発生する可能性があります。
a. 取り込みの遅延。
現在の実行中のトランザクションを確認するために
show proc /transactions/{db_name}/running';を使用し、次のような遅延メッセージが ErrMsg フィールドに表示される場合、取り込みの遅延が発生していることを意味します。
Partition's compaction score is larger than 100.0, delay commit for xxxms. You can try to increase compaction concurrency
例:
mysql> show proc '/transactions/test_pri_load_c/running';
+---------------+----------------------------------------------+------------------+-------------------+--------------------+---------------------+------------+-------------+------------+----------------------------------------------------------------------------------------------------------------------------+--------------------+------------+-----------+--------+
| TransactionId | Label | Coordinator | TransactionStatus | LoadJobSourceType | PrepareTime | CommitTime | PublishTime | FinishTime | Reason | ErrorReplicasCount | ListenerId | TimeoutMs | ErrMsg |
+---------------+----------------------------------------------+------------------+-------------------+--------------------+---------------------+------------+-------------+------------+----------------------------------------------------------------------------------------------------------------------------+--------------------+------------+-----------+--------+
| 1034 | stream_load_d2753fbaa0b343acadd5f13de92d44c1 | FE: 172.26.94.39 | PREPARE | FRONTEND_STREAMING | 2024-10-24 13:05:01 | NULL | NULL | NULL | Partition's compaction score is larger than 100.0, delay commit for 6513ms. You can try to increase compaction concurrency, | 0 | 11054 | 86400000 | |
+---------------+----------------------------------------------+------------------+-------------------+--------------------+---------------------+------------+-------------+------------+----------------------------------------------------------------------------------------------------------------------------+--------------------+------------+-----------+--------+
b. 取り込みの停止。 次のような取り込みエラーが発生した場合:
Failed to load data into partition xxx, because of too large compaction score, current/limit: xxx/xxx. You can reduce the loading job concurrency, or increase compaction concurrency
これは、Compaction が現在の高頻度の書き込みに追いつかないため、取り込みが停止したことを意味します。
- 共有なしクラスタの場合、取り込みの遅延戦略はありません。Compaction が現在の高頻度の書き込みに追いつかない場合、取り込みは失敗し、次のようなエラーメッセージが返されます。
Failed to load data into tablet xxx, because of too many versions, current/limit: xxx/xxx. You can reduce the loading job concurrency, or increase loading data batch size. If you are loading data with Routine Load, you can increase FE configs routine_load_task_consume_second and max_routine_load_batch_size.
データの新鮮さと Compaction リソースの制限
限られた Compaction リソースを持ちながらも十分なデータの新鮮さを維持する必要がある場合、クエリ遅延を犠牲にする必要があります。
これを達成するために、次の設定変更を行うことができます。
- 共有データクラスタ
fe.conf
lake_ingest_slowdown_threshold = xxx (デフォルトは 100、増やすことができます)
lake_compaction_score_upper_bound = xxx (デフォルトは 2000、増やすことができます)
lake_ingest_slowdown_threshold パラメータは、取り込みの遅延をトリガーする閾値を制御します。パーティションの Compaction スコアがこの閾値を超えると、システムはデータ取り込みを遅延させ始めます。同様に、lake_compaction_score_upper_bound は取り込みの停止をトリガーする閾値を決定します。
- 共有なしクラスタ
be.conf
tablet_max_versions = xxx (デフォルトは 1000、増やすことができます)
tablet_max_versions は取り込みの停止をトリガーする閾値を決定します。
これらの設定を増やすことで、システムはより多くの小さなデータファイルを受け入れ、Compaction の頻度を減らすことができますが、これによりクエリ遅延にも影響を与えます。
クエリ遅延と Compaction リソースの制限
限られた Compaction リソースで良好なクエリ遅延を達成したい場合、書き込み頻度を減らし、取り込みのためにより大きなデータバッチを作成する必要があります。
具体的な実装については、取り込み方法のセクションを参照してください。取り込み頻度を減らし、バッチサイズを増やす方法が詳しく説明されています。
