データ分散
テーブル作成時に適切なパーティション化とバケッティングを設定することで、均等なデータ分散を実現できます。均等なデータ分散とは、特定のルールに従ってデータをサブセットに分割し、それらを異なるノードに均等に分散させることを意味します。これにより、スキャンするデータ量を減らし、クラスターの並列処理能力を最大限に活用することで、クエリパフォーマンスを向上させることができます。
注意
- テーブル作成時にデータ分散が指定され、ビジネスシナリオでクエリパターンやデータ特性が進化した場合、v3.2以降のStarRocksでは、テーブル作成後に特定のデータ分散関連プロパティを変更して最新のビジネスシナリオにおけるクエリパフォーマンスの要件を満たすことができます。
- v3.1以降、テーブル作成時やパーティション追加時にDISTRIBUTED BY句でバケッティングキーを指定する必要はありません。StarRocksはランダムバケット法をサポートしており、データをすべてのバケットにランダムに分散させます。詳細はランダムバケット法を参照してください。
- v2.5.7以降、テーブル作成時やパーティション追加時にバケット数を手動で設定しないことを選択できます。StarRocksは自動的にバケット数(BUCKETS)を設定します。ただし、StarRocksが自動的にバケット数を設定した後にパフォーマンスが期待に応えない場合で、バケッティン�グメカニズムに精通している場合は、バケット数を手動で設定することもできます。
分散手法
一般的な分散手法
現代の分散データベースシステムでは、一般的に以下の基本的な分散手法が使用されます: ラウンドロビン、レンジ、リスト、ハッシュ。
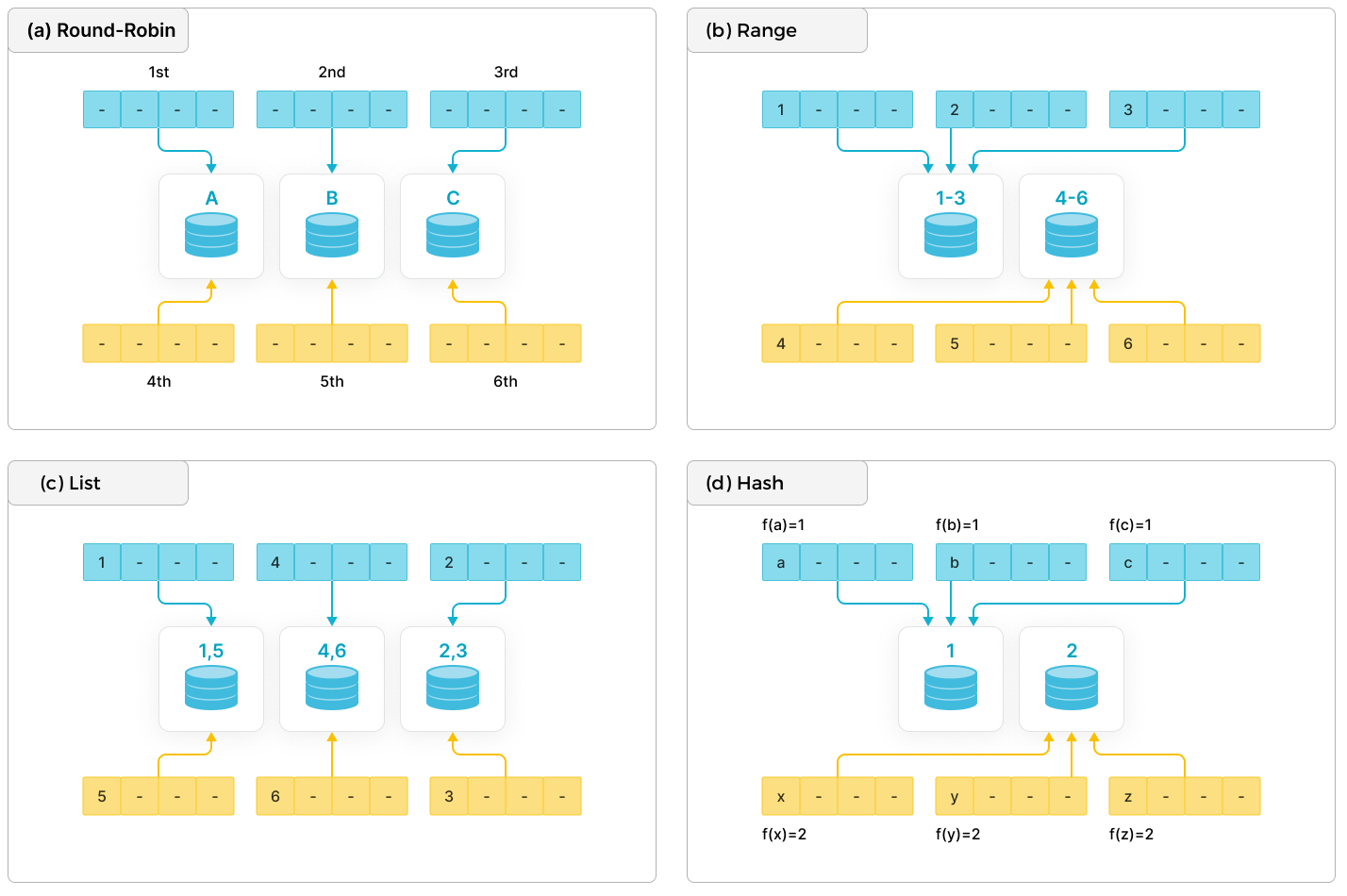
- ラウンドロビン: データを異なるノードに循環的に分散します。
- レンジ: パーティション列の値の範囲に基づいてデータを異なるノードに分散します。図に示すように、範囲[1-3]と[4-6]は異なるノードに対応しています。
- リスト: パーティション列の離散値に基づいてデータを異なるノードに分散します。性別や州などの離散値がノードにマッピングされ、複数の異なる値が同じノードにマッピングされることがあります。
- ハッシュ: ハッシュ関数に基づいてデータを異なるノードに分散します。
より柔軟なデータパーティション化を実現するために、上記のデータ分散手法のいずれ�かを使用するだけでなく、特定のビジネス要件に基づいてこれらの手法を組み合わせることもできます。一般的な組み合わせには、ハッシュ+ハッシュ、レンジ+ハッシュ、ハッシュ+リストがあります。
StarRocksにおける分散手法
StarRocksは、データ分散手法の個別および複合使用の両方をサポートしています。
注意
一般的な分散手法に加えて、StarRocksはバケッティング設定を簡素化するためにランダム分散もサポートしています。
また、StarRocksは二層のパーティション化 + バケッティング手法を実装してデータを分散させます。
- 第一層はパーティション化です: テーブル内のデータはパーティション化できます。サポートされているパーティション化の手法は、式に基づくパーティション化、レンジパーティション化、リストパーティション化です。また、パーティション化を使用しないことも選択できます(テーブル全体が1つのパーティションと見なされます)。
- 第二層はバケッティングです: パーティション内のデータはさらに小さなバケットに分配される必要があります。サポートされているバケッティング手法はハッシュとランダムバケット法です。
| 分散手法 | パーティション化とバケッティング手法 | 説明 |
|---|---|---|
| ランダム分散 | ランダムバケット法 | テーブル全体が1つのパーティションと見なされます。テーブル内のデータは異なるバケットにランダムに分散されます。これはデフォルトのデータ分散手法です。 |
| ハッシュ分散 | ハッシュバケット法 | テーブル全体が1つのパーティションと見なされます。テーブル内のデータは、データのバケッティングキーのハッシュ値に基づいて対応するバケットに分配されます。 |
| レンジ+ランダム分散 |
|
|
| レンジ+ハッシュ分散 |
|
|
| リスト+ランダム分散 |
|
|
| リスト+ハッシュ分散 |
|
|
-
ランダム分散
テーブル作成時にパーティション化とバケッティング手法を設定しない場合、デフォルトでランダム分散が使用されます。この分散手法は現在、重複キーテーブルの作成にのみ使用できます。
CREATE TABLE site_access1 (
event_day DATE,
site_id INT DEFAULT '10',
pv BIGINT DEFAULT '0' ,
city_code VARCHAR(100),
user_name VARCHAR(32) DEFAULT ''
)
DUPLICATE KEY (event_day,site_id,pv);
-- パーティション化とバケッティング手法が設定されていないため、デフォルトでランダム分散が使用されます。 -
ハッシュ分散
CREATE TABLE site_access2 (
event_day DATE,
site_id INT DEFAULT '10',
city_code SMALLINT,
user_name VARCHAR(32) DEFAULT '',
pv BIGINT SUM DEFAULT '0'
)
AGGREGATE KEY (event_day, site_id, city_code, user_name)
-- ハッシュバケット法をバケッティング手法として使用し、バケッティングキーを指定する必要があります。
DISTRIBUTED BY HASH(event_day,site_id); -
レンジ+ランダム分散(この分散手法は現在、重複キーテーブルの作成にのみ使用できます。)
CREATE TABLE site_access3 (
event_day DATE,
site_id INT DEFAULT '10',
pv BIGINT DEFAULT '0' ,
city_code VARCHAR(100),
user_name VARCHAR(32) DEFAULT ''
)
DUPLICATE KEY(event_day,site_id,pv)
-- 式に基づくパーティション化をパーティション化手法として使用し、時間関数式を設定します。
-- レンジパーティション化も使用できます。
PARTITION BY date_trunc('day', event_day);
-- バケッティング手法が設定されていないため、デフォルトでランダムバケット法が使用されます。 -
レンジ+ハッシュ分散
CREATE TABLE site_access4 (
event_day DATE,
site_id INT DEFAULT '10',
city_code VARCHAR(100),
user_name VARCHAR(32) DEFAULT '',
pv BIGINT SUM DEFAULT '0'
)
AGGREGATE KEY(event_day, site_id, city_code, user_name)
-- 式に基づくパーティション化をパーティション化手法として使用し、時間関数式を設定します。
-- レンジパーティション化も使用できます。
PARTITION BY date_trunc('day', event_day)
-- ハッシュバケット法をバケッティング手法として使用し、バケッティングキーを指定する必要があります。
DISTRIBUTED BY HASH(event_day, site_id); -
リスト+ランダム分散(この分散手法は現在、重複キーテーブルの作成にのみ使用できます。)
CREATE TABLE t_recharge_detail1 (
id bigint,
user_id bigint,
recharge_money decimal(32,2),
city varchar(20) not null,
dt date not null
)
DUPLICATE KEY(id)
-- 式に基づくパーティション化をパーティション化手法として使用し、パーティション列を指定します。
-- リストパーティション化も使用できます。
PARTITION BY (city);
-- バケッティング手法が設定されていないため、デフォルトでランダム�バケット法が使用されます。 -
リスト+ハッシュ分散
CREATE TABLE t_recharge_detail2 (
id bigint,
user_id bigint,
recharge_money decimal(32,2),
city varchar(20) not null,
dt date not null
)
DUPLICATE KEY(id)
-- 式に基づくパーティション化をパーティション化手法として使用し、パーティション列を指定します。
-- リ��ストパーティション化も使用できます。
PARTITION BY (city)
-- ハッシュバケット法をバケッティング手法として使用し、バケッティングキーを指定する必要があります。
DISTRIBUTED BY HASH(city,id);
パーティション化
パーティション化手法は、テーブルを複数のパーティ�ションに分割します。パーティション化は主に、パーティションキーに基づいてテーブルを異なる管理単位(パーティション)に分割するために使用されます。各パーティションに対してストレージ戦略を設定できます。これには、バケット数、ホットデータとコールドデータの保存戦略、記憶媒体の種類、レプリカの数が含まれます。StarRocksは、クラスター内で異なる種類の記憶媒体を使用することを許可しています。たとえば、最新のデータをソリッドステートドライブ(SSD)に保存してクエリパフォーマンスを向上させ、履歴データをSATAハードドライブに保存してストレージコストを削減することができます。
| パーティション化手法 | シナリオ | パーティションを作成する方法 |
|---|---|---|
| 式に基づくパーティション化(推奨) | 以前は自動パーティション化として知られていました。このパーティション化手法はより柔軟で使いやすく、連続した日付範囲や列挙値に基づいてデータをクエリおよび管理するほとんどのシナリオに適しています。 | データロード中に自動的に作成されます |
| レンジパーティション化 | 典型的なシナリオは、連続した日付/数値範囲に基づいて頻繁にクエリおよび管理されるシンプルで順序付けられたデータを保存することです。たとえば、特定のケースでは、履歴データを月ごとにパーティション化し、最近のデータを日ごとにパーティション化する必要があります。 | 手動で、動的に、またはバッチで作成されます |
| リストパーティション化 | 典型的なシナリオは、列挙値に基づいてデータをクエリおよび管理し、各パーティション列の異なる値を含むデータを含む必要がある場合です。たとえば、国や都市に基づいて頻繁にデータをクエリおよび管理する場合、この手法を使用し、cityをパーティション列として選択できます。この場合、1つのパーティションは同じ国に属する複数の都市のデータを保存できます。 | 手動で作成されます |
パーティション列と粒度の選択方法
- 適切なパーティション列を選択することで、クエリ中にスキャンするデータ量を効果的に減らすことができます。ほとんどのビジネスシステムでは、時間に基づくパーティション化が一般的に採用されており、期限切れデータの削除によって引き起こされる特定の問題を解決し、ホットデータとコールドデータの階層型ストレージの管理を容易にします。この場合、式に基づくパーティション化またはレンジパーティション化を使用し、時間列をパーティション列として指定できます。さらに、データがENUM値に基づいて頻繁にクエリおよび管理される場合、式に基づくパーティション化またはリストパーティション化を使用し、これらの値を含む列をパーティション列として指定できます。
- パーティションの粒度を選択する際には、データ量、クエリパターン、データ管理の粒度を考慮する必要があります。
- 例1: テーブルの月間データ量が少ない場合、日ごとにパーティション化するよりも月ごとにパーティション化することで、メタデータの量を減らし、メタデータ管理とスケジューリングのリソース消費を削減できます。
- 例2: テーブルの月間データ量が多く、クエリが特定の日のデータを主に要求する場合、日ごとにパーティション化することで、クエリ中にスキャンするデータ量を効果的に減らすことができます。
- 例3: データが日ごとに期限切れになる必要がある場合、日ごとにパーティション化することをお勧めします。
バケッティング
バケッティング手法は、パーティションを複数のバケットに分割します。バケット内のデータはtabletと呼ばれます。
サポートされているバケッティング手法は、ランダムバケット法(v3.1以降)とハッシュバケット法です。
-
ランダムバケット法: テーブル作成時やパーティション追加時に、バケッティングキーを設定する必要はありません。パーティション内のデータは異なるバケットにランダムに分散されます。
-
ハッシュバケット法: テーブル作成時やパーティション追加時に、バケッティングキーを指定する必要があります。同じパーティション内のデー�タは、バケッティングキーの値に基づいてバケットに分割され、バケッティングキーの同じ値を持つ行は対応する一意のバケットに分配されます。
バケット数: デフォルトでは、StarRocksは自動的にバケット数を設定します(v2.5.7以降)。また、バケット数を手動で設定することもできます。詳細については、バケット数の決定を参照してください。
パーティションの作成と管理
パーティションの作成
式に基づくパーティション化(推奨)
注意
v3.1以降、StarRocksの共有データモードは時間関数式をサポートし、列式をサポートしていません。
v3.0以降、StarRocksは式に基づくパーティション化(以前は自動パ��ーティション化として知られていました)をサポートしており、より柔軟で使いやすくなっています。このパーティション化手法は、連続した日付範囲やENUM値に基づいてデータをクエリおよび管理するほとんどのシナリオに適しています。
テーブル作成時にパーティション式(時間関数式または列式)を設定するだけで、StarRocksはデータロード中に自動的にパーティションを作成します。事前に多数のパーティションを手動で作成する必要はなく、動的パーティションプロパティを設定する必要もありません。
レンジパーティション化
レンジパーティション化は、時系列データや連続した数値データなど、シンプルで連続したデータを保存するのに適しています。レンジパーティション化は、連続した日付/数値範囲に基づいて頻繁にクエリされるデータに適しています。さらに、履歴データを月ごとにパーティション化し、最近のデータを日ごとにパーティション化する必要がある特定のケースにも適用できます。
StarRocksは、各パーティションの明示的に定義された範囲の明示的なマッピングに基づいて、対応するパーティションにデータを保存します。
動的パーティション化
動的パーティション化関連のプロパティは、テーブル作成時に設定されます。StarRocksは、新しいパーティションを事前に自動的に作成し、期限切れのパーティションを削除してデータの新鮮さを確保し、パーティションのタイムトゥリブ(TTL)管理を実装します。
式に基づくパーティション化によって提供される自動パーティション作成機能とは異なり、動的パーティション化はプロパティに基づいて新しいパーティションを定期的に作成することしかできません。新しいデータがこれらのパーティションに属していない場合、ロードジョブに対してエラーが返されます。ただし、式に基づくパーティション化によって提供される自動パーティション作成機能は、ロードされたデータに基づいて常に対応する新しいパーティションを作成できます。
パーティションを手動で作成する
適切なパーティションキーを使用することで、クエリ中にスキャンするデータ量を効果的に減らすことができます。現在、日付または整数型の列のみがパーティション列として選択され、パーティションキーを構成することができます。ビジネスシナリオでは、データ管理の観点からパーティションキーが選択されることが一般的です。一般的なパーティ��ション列には、日付や場所を表す列が含まれます。
CREATE TABLE site_access(
event_day DATE,
site_id INT DEFAULT '10',
city_code VARCHAR(100),
user_name VARCHAR(32) DEFAULT '',
pv BIGINT SUM DEFAULT '0'
)
AGGREGATE KEY(event_day, site_id, city_code, user_name)
PARTITION BY RANGE(event_day)(
PARTITION p1 VALUES LESS THAN ("2020-01-31"),
PARTITION p2 VALUES LESS THAN ("2020-02-29"),
PARTITION p3 VALUES LESS THAN ("2020-03-31")
)
DISTRIBUTED BY HASH(site_id);
バッチで複数のパーティションを作成する
テーブル作成時および作成後に、バッチで複数のパーティションを作成できます。START()およびEND()でバッチで作成されるすべてのパーティションの開始時間と終了時間を指定し、EVERY()でパーティションの増分値を指定できます。ただし、パーティションの範囲は右半開であり、開始時間を含み、終了時間を含まないことに注意してください。パーティションの命名ルールは動的パーティション化と同じです。
-
テーブル作成時に日付型列(DATEおよびDATETIME)でテーブルをパーティション化する
パーティション列が日付型�の場合、テーブル作成時に
START()およびEND()を使用してバッチで作成されるすべてのパーティションの開始日と終了日を指定し、EVERY(INTERVAL xxx)で2つのパーティション間の増分間隔を指定できます。現在、間隔の粒度はHOUR(v3.0以降)、DAY、WEEK、MONTH、YEARをサポートしています。次の例では、バッチで作成されるすべてのパーティションの日付範囲は2021-01-01から始まり、2021-01-04で終わり、増分間隔は1日です。
CREATE TABLE site_access (
datekey DATE,
site_id INT,
city_code SMALLINT,
user_name VARCHAR(32),
pv BIGINT DEFAULT '0'
)
ENGINE=olap
DUPLICATE KEY(datekey, site_id, city_code, user_name)
PARTITION BY RANGE (datekey) (
START ("2021-01-01") END ("2021-01-04") EVERY (INTERVAL 1 DAY)
)
DISTRIBUTED BY HASH(site_id)
PROPERTIES ("replication_num" = "3" );これは、CREATE TABLE文で次の
PARTITION BY句を使用することと同等です。PARTITION BY RANGE (datekey) (
PARTITION p20210101 VALUES [('2021-01-01'), ('2021-01-02')),
PARTITION p20210102 VALUES [('2021-01-02'), ('2021-01-03')),
PARTITION p20210103 VALUES [('2021-01-03'), ('2021-01-04'))
) -
テーブル作成時に異なる日付間隔で日付型列(DATEおよびDATETIME)でテーブルをパーティション化する
各バッチのパーティションに対して異なる増分間隔を
EVERYで指定することにより、異なる増分間隔で日付パーティションのバッチを作成できます(異なるバッチ間でパーティション範囲が重ならないようにしてください)。各バッチのパーティションは、START (xxx) END (xxx) EVERY (xxx)句に従って作成されます。例:CREATE TABLE site_access(
datekey DATE,
site_id INT,
city_code SMALLINT,
user_name VARCHAR(32),
pv BIGINT DEFAULT '0'
)
ENGINE=olap
DUPLICATE KEY(datekey, site_id, city_code, user_name)
PARTITION BY RANGE (datekey)
(
START ("2019-01-01") END ("2021-01-01") EVERY (INTERVAL 1 YEAR),
START ("2021-01-01") END ("2021-05-01") EVERY (INTERVAL 1 MONTH),
START ("2021-05-01") END ("2021-05-04") EVERY (INTERVAL 1 DAY)
)
DISTRIBUTED BY HASH(site_id)
PROPERTIES(
"replication_num" = "3"
);これは、CREATE TABLE文で次の
PARTITION BY句を使用することと同等です。PARTITION BY RANGE (datekey) (
PARTITION p2019 VALUES [('2019-01-01'), ('2020-01-01')),
PARTITION p2020 VALUES [('2020-01-01'), ('2021-01-01')),
PARTITION p202101 VALUES [('2021-01-01'), ('2021-02-01')),
PARTITION p202102 VALUES [('2021-02-01'), ('2021-03-01')),
PARTITION p202103 VALUES [('2021-03-01'), ('2021-04-01')),
PARTITION p202104 VALUES [('2021-04-01'), ('2021-05-01')),
PARTITION p20210501 VALUES [('2021-05-01'), ('2021-05-02')),
PARTITION p20210502 VALUES [('2021-05-02'), ('2021-05-03')),
PARTITION p20210503 VALUES [('2021-05-03'), ('2021-05-04'))
) -
テーブル作成時に整数型列でテーブルをパーティション化する
パーティション列のデータ型がINTの場合、
STARTおよびENDでパーティションの範囲を指定し、EVERYで増分値を定義します。例:注意
**START()およびEND()**内のパーティション列の値は二重引用符で囲む必要がありますが、**EVERY()**内の増分値は二重引用符で囲む必要はありません。
次の例では、すべてのパーティションの範囲は
1から始まり、5で終わり、パーティションの増分は1です。CREATE TABLE site_access (
datekey INT,
site_id INT,
city_code SMALLINT,
user_name VARCHAR(32),
pv BIGINT DEFAULT '0'
)
ENGINE=olap
DUPLICATE KEY(datekey, site_id, city_code, user_name)
PARTITION BY RANGE (datekey) (START ("1") END ("5") EVERY (1)
)
DISTRIBUTED BY HASH(site_id)
PROPERTIES ("replication_num" = "3");これは、CREATE TABLE文で次の
PARTITION BY句を使用することと同等です。PARTITION BY RANGE (datekey) (
PARTITION p2019 VALUES [('2019-01-01'), ('2020-01-01')),
PARTITION p2020 VALUES [('2020-01-01'), ('2021-01-01')),
PARTITION p202101 VALUES [('2021-01-01'), ('2021-02-01')),
PARTITION p202102 VALUES [('2021-02-01'), ('2021-03-01')),
PARTITION p202103 VALUES [('2021-03-01'), ('2021-04-01')),
PARTITION p202104 VALUES [('2021-04-01'), ('2021-05-01')),
PARTITION p20210501 VALUES [('2021-05-01'), ('2021-05-02')),
PARTITION p20210502 VALUES [('2021-05-02'), ('2021-05-03')),
PARTITION p20210503 VALUES [('2021-05-03'), ('2021-05-04'))
)
テーブル作成後にバッチで複数のパーティションを作成する
テーブル作成後に、ALTER TABLE文を使用してパーティションを追加できます。構文は、テーブル作成時にバッチで複数のパーティションを作成する場合と似ています。ADD PARTITIONS句でSTART、END、EVERYを設定する必要があります。
ALTER TABLE site_access
ADD PARTITIONS START ("2021-01-04") END ("2021-01-06") EVERY (INTERVAL 1 DAY);
リストパーティション化(v3.1以降)
List Partitioningは、列挙値に基づいてデータを効率的に管理し、クエリを高速化するのに適しています。特に、パーティション列に異なる値を持つデータを含む必要があるシナリオで役立ちます。たとえば、国や都市に基づいて頻繁にデータをクエリおよび管理する場合、このパーティション化手法を使用し、city列をパーティション列として選択できます。この場合、1つのパーティションは1つの国に属するさまざまな都市のデータを含むことができます。
StarRocksは、各パーティションの事前定義された値リストの明示的なマッピングに基づいて、対応するパー�ティションにデータを保存します。
パーティションの管理
パーティションを追加する
レンジパーティション化およびリストパーティション化の場合、新しいデータを保存するために新しいパーティションを手動で追加できます。ただし、式に基づくパーティション化の場合、データロード中にパーティションが自動的に作成されるため、その必要はありません。
次の文は、新しい月のデータを保存するためにテーブルsite_accessに新しいパーティションを追加します。
ALTER TABLE site_access
ADD PARTITION p4 VALUES LESS THAN ("2020-04-30")
DISTRIBUTED BY HASH(site_id);
パーティションを削除する
次の文は、テーブルsite_accessからパーティションp1を削除します。
注意
この操作は、パーティション内のデータを即座に削除するわけではありません。データは一定期間(デフォルトで1日)ゴミ箱に保持されます。パーティションが誤って削除された場合、RECOVERコマンドを使用してパーティションとそのデータを復元できます。
ALTER TABLE site_access
DROP PARTITION p1;
パーティションを復元する
次の文は、パーティションp1とそのデータをテーブルsite_accessに復元します。
RECOVER PARTITION p1 FROM site_access;
パーティションを表示する
次の文は、テーブルsite_access内のすべてのパーティションの詳細を返します。
SHOW PARTITIONS FROM site_access;
バケッティングの設定
ランダムバケット法(v3.1以降)
StarRocksは、パーティション内のデータをすべてのバケットにランダムに分散させます。これは、データサイズが小さく、クエリパフォーマンスに対する要求が比較的低いシナリオに適しています。バケッティング手法を設定しない場合、StarRocksはデフォルトでランダムバケット法を使用し、バケット数を自動的に設定します。
ただし、大量のデータをクエリし、特定の列をフィルタ条件として頻繁に使用する場合、ランダムバケット法が提供するクエリパフォーマンスは最適ではない可能性があります。そのようなシナリオでは、ハッシュバケット法を使用することをお勧めします。これらの列がクエリのフィルタ条件として使用される場合、クエリがヒットするバケットのデータのみをスキャンおよび計算する必要があるため、クエリパフォーマンスが大幅に向上します。
制限事項
- ランダムバケット法は、重複キーテーブルの作成にのみ使用できます。
- ランダムにバケット化されたテーブルをColocation Groupに属させることはできません。
- Spark Loadを使用してランダムにバケット化されたテーブルにデータをロードすることはできません。
次のCREATE TABLEの例では、DISTRIBUTED BY xxx文が使用されていないため、StarRocksはデフォルトでランダムバケット法を使用し、バケット数を自動的に設定します。
CREATE TABLE site_access1(
event_day DATE,
site_id INT DEFAULT '10',
pv BIGINT DEFAULT '0' ,
city_code VARCHAR(100),
user_name VARCHAR(32) DEFAULT ''
)
DUPLICATE KEY(event_day,site_id,pv);
ただし、StarRocksのバケッティングメカニズムに精通している場合、ランダムバケット法でテーブルを作成する際にバケット数を手動で設定することもできます。
CREATE TABLE site_access2(
event_day DATE,
site_id INT DEFAULT '10',
pv BIGINT DEFAULT '0' ,
city_code VARCHAR(100),
user_name VARCHAR(32) DEFAULT ''
)
DUPLICATE KEY(event_day,site_id,pv)
DISTRIBUTED BY RANDOM BUCKETS 8; -- バケット数を8に手動で設定
ハッシュバケット法
StarRocksは、バケッティングキーとバケット数に基づいて、パーティション内のデータをバケットに細分化するためにハッシュバケット法を使用できます。ハッシュバケット法では、ハッシュ関数がデータのバケッティングキーの値を入力として受け取り、ハッシュ値を計算します。データは、ハッシュ値とバケットの間のマッピングに基づいて対応するバケットに保存されます。
利点
-
クエリパフォーマンスの向上: 同じバケッティングキーの値を持つ行が同じバケットに保存されるため、クエリ中にスキャンするデータ量が減少します。
-
均等なデータ分散: カーディナリティ(ユニークな値の数)が高い列をバケッティングキーとして選択することで、データをバケット間でより均等に分散させることができます。
バケッティング列の選択方法
次の2つの要件を満たす列をバケッティング列として選択することをお勧めします。
- カーディナリティが高い列(例: ID)
- クエリのフィルタとして頻繁に使用される列
ただし、どの列も両方の要件を満たさない場合、クエリの複雑さに応じてバケッティング列を決定する必要があります。
- クエリが複雑な場合、データをすべてのバケットにできるだけ均等に分散させ、クラスターのリソース利用率を向上させるために、カーディナリティが高い列をバケッティング列として選択することをお勧めします。
- クエリが比較的単純な場合、クエリでフィルタ条件として頻繁に使用される列をバケッティング列として選択し、クエリ効率を向上させることをお勧めします。
1つのバケッティング列を使用してパーティションデータをすべてのバケットに均等に分散できない場合、複数のバケッティング列を選択できます。ただし、3列を超えないことをお勧めします。
注意事項
- テーブル作成時にバケッティング列を指定する必要があります。
- バケッティング列のデータ型は、INTEGER、DECIMAL、DATE/DATETIME、またはCHAR/VARCHAR/STRINGである必要があります。
- 3.2以降、テーブル作成後にALTER TABLEを使用してバケッティング列を変更できます。
例
次の例では、site_accessテーブルがsite_idをバケッティング列として使用して作成されています。さらに、site_accessテーブルのデータがクエリされる際、データはしばしばサイトでフィルタされます。site_idをバケッティングキーとして使用することで、クエリ中に関連のないバケットを大幅に削減できます。
CREATE TABLE site_access(
event_day DATE,
site_id INT DEFAULT '10',
city_code VARCHAR(100),
user_name VARCHAR(32) DEFAULT '',
pv BIGINT SUM DEFAULT '0'
)
AGGREGATE KEY(event_day, site_id, city_code, user_name)
PARTITION BY RANGE(event_day)
(
PARTITION p1 VALUES LESS THAN ("2020-01-31"),
PARTITION p2 VALUES LESS THAN ("2020-02-29"),
PARTITION p3 VALUES LESS THAN ("2020-03-31")
)
DISTRIBUTED BY HASH(site_id);
テーブルsite_accessの各パーティションが10個のバケットを持っていると仮定します。次のクエリでは、10個のバケットのうち9個が削除されるため、StarRocksはsite_accessテーブルのデータの1/10のみをスキャンする必要があります。
select sum(pv)
from site_access
where site_id = 54321;
ただし、site_idが不均等に分散され、多くのクエリが少数のサイトのデータのみを要求する場合、1つのバケッティング列のみを使用すると、深刻なデータスキューが発生し、システムのパフォーマンスボトルネックを引き起こす可能性があります。この場合、バケッティング列の組み合わせを使用できます。たとえば、次の文では、site_idとcity_codeをバケッティング列として使用しています。
CREATE TABLE site_access
(
site_id INT DEFAULT '10',
city_code SMALLINT,
user_name VARCHAR(32) DEFAULT '',
pv BIGINT SUM DEFAULT '0'
)
AGGREGATE KEY(site_id, city_code, user_name)
DISTRIBUTED BY HASH(site_id,city_code);
実際には、ビジネスの特性に基づいて1つまたは2つのバケッティング列を使用できます。1つのバケッティング列site_idを使用することは、短いクエリに非常に有益であり、ノード間のデータ交換を減らし��、クラスター全体のパフォーマンスを向上させます。一方、2つのバケッティング列site_idとcity_codeを採用することは、長いクエリに有利であり、分散クラスターの全体的な並列性を活用してパフォーマンスを大幅に向上させます。
注意
- 短いクエリは少量のデータをスキャンし、単一のノードで完了できます。
- 長いクエリは大量のデータをスキャンし、分散クラスター内の複数のノードでの並列スキャンによってパフォーマンスが大幅に向上します。
バケット数の設定
バケットは、StarRocksでデータファイルが実際にどのように編成されているかを反映しています。
テーブル作成時
-
バケット数を自動的に設定する(推奨)
v2.5.7以降、StarRocksは、マシンリソースとパーティションのデータ量に基づいてバケット数を自動的に設定することをサポートしています。
ヒントパーティションの生データサイズが100 GBを超える場合、手動でバケット数を設定することをお勧めします。
- ハッシュバケット法で設定されたテーブル
- ランダムバケット法で設定されたテーブル
例:
CREATE TABLE site_access (
site_id INT DEFAULT '10',
city_code SMALLINT,
user_name VARCHAR(32) DEFAULT '',
event_day DATE,
pv BIGINT SUM DEFAULT '0')
AGGREGATE KEY(site_id, city_code, user_name,event_day)
PARTITION BY date_trunc('day', event_day)
DISTRIBUTED BY HASH(site_id,city_code); -- バケット数を設定する必要はありませんランダムバケット法で�設定されたテーブルについては、パーティション内のバケット数を自動的に設定することに加えて、StarRocksはv3.2.0以降、ロジックをさらに最適化しています。StarRocksは、クラスターの容量とロードされたデータの量に基づいて、データロード中にパーティション内のバケット数を動的に増加させることもできます。
警告- バケット数のオンデマンドおよび動的増加を有効にするには、テーブルプロパティ
PROPERTIES("bucket_size"="xxx")を設定して、単一バケットのサイズを指定する必要があります。パーティション内のデータ量が少ない場合、bucket_sizeを1 GBに設定できます。それ以外の場合、bucket_sizeを4 GBに設定できます。 - バケット数のオンデマンドおよび動的増加が有効になっている場合、バージョン3.1にロールバックする必要がある場合は、バケット数の動的増加を有効にしたテーブルを最初に削除する必要があります。その後、ロールバックする前に、ALTER SYSTEM CREATE IMAGEを使用してメタデータチェックポイントを手動で実行する必要があります。
例:
CREATE TABLE details1 (
event_day DATE,
site_id INT DEFAULT '10',
pv BIGINT DEFAULT '0',
city_code VARCHAR(100),
user_name VARCHAR(32) DEFAULT '')
DUPLICATE KEY (event_day,site_id,pv)
PARTITION BY date_trunc('day', event_day)
-- パーティション内のバケット数はStarRocksによって自動的に決定され、バケットのサイズが1 GBに設定されているため、オンデマンドで動的に増加します。
PROPERTIES("bucket_size"="1073741824")
;
CREATE TABLE details2 (
event_day DATE,
site_id INT DEFAULT '10',
pv BIGINT DEFAULT '0' ,
city_code VARCHAR(100),
user_name VARCHAR(32) DEFAULT '')
DUPLICATE KEY (event_day,site_id,pv)
PARTITION BY date_trunc('day', event_day)
-- テーブルパーティション内のバケット数はStarRocksによって自動的に決定され、オンデマンドで動的に増加しないため、バケットのサイズは設定されていません。
; -
バケット数を手動で設定する
v2.4.0以降、StarRocksはクエリ中に複数のスレッドを�使用してtabletを並列にスキャンすることをサポートしており、スキャンパフォーマンスのtablet数への依存を減らします。各tabletに約10 GBの生データを含めることをお勧めします。バケット数を手動で設定する場合、テーブルの各パーティションのデータ量を見積もり、その後tabletの数を決定できます。
tabletでの並列スキャンを有効にするには、
enable_tablet_internal_parallelパラメータをシステム全体でTRUEに設定してください(SET GLOBAL enable_tablet_internal_parallel = true;)。- ハッシュバケット法で設定されたテーブル
- ランダムバケット法で設定されたテーブル
CREATE TABLE site_access (
site_id INT DEFAULT '10',
city_code SMALLINT,
user_name VARCHAR(32) DEFAULT '',
event_day DATE,
pv BIGINT SUM DEFAULT '0')
AGGREGATE KEY(site_id, city_code, user_name,event_day)
PARTITION BY date_trunc('day', event_day)
DISTRIBUTED BY HASH(site_id,city_code) BUCKETS 30;
-- パーティションにロードしたい生データの量が300 GBであると仮定します。
-- 各tabletに10 GBの生データを含めることをお勧めするため、バケット数を30に設定できます。
DISTRIBUTED BY HASH(site_id,city_code) BUCKETS 30;CREATE TABLE details (
site_id INT DEFAULT '10',
city_code VARCHAR(100),
user_name VARCHAR(32) DEFAULT '',
event_day DATE,
pv BIGINT DEFAULT '0'
)
DUPLICATE KEY (site_id,city_code)
PARTITION BY date_trunc('day', event_day)
DISTRIBUTED BY RANDOM BUCKETS 30
;
テーブル作成後
-
バケット数を自動的に設定する(推奨)
v2.5.7以降、StarRocksは、マシンリソースとパーティションのデータ量に基づいてバケット数を自動的に設定することをサポートしています。
ヒントパーティションの生データサイズが100 GBを超える場合、手動でバケット数を設定することをお勧めします。
- ハッシュバケット法で設定されたテーブル
- ランダムバケット法で設定されたテーブル
-- すべてのパーティションのバケット数を自動的に設定します。
ALTER TABLE site_access DISTRIBUTED BY HASH(site_id,city_code);
-- 特定のパーティションのバケット数を自動的に設定します。
ALTER TABLE site_access PARTITIONS (p20230101, p20230102)
DISTRIBUTED BY HASH(site_id,city_code);
-- 新しいパーティションのバケット数を自動的に設定します。
ALTER TABLE site_access ADD PARTITION p20230106 VALUES [('2023-01-06'), ('2023-01-07'))
DISTRIBUTED BY HASH(site_id,city_code);ランダムバケット法で設定されたテーブルについては、パーティション内のバケット数を自動的に設定することに加えて、StarRocksはv3.2.0以降、ロジックをさらに最適化しています。StarRocksは、クラスターの容量とロードされたデータの量に基づいて、データロード中に�パーティション内のバケット数を動的に増加させることもできます。これにより、パーティションの作成が容易になり、大量のロードパフォーマンスが向上します。
警告- バケット数のオンデマンドおよび動的増加を有効にするには、テーブルプロパティ
PROPERTIES("bucket_size"="xxx")を設定して、単一バケットのサイズを指定する必要があります。パーティション内のデータ量が少ない場合、bucket_sizeを1 GBに設定できます。それ以外の場合、bucket_sizeを4 GBに設定できます。 - バケット数のオンデマンドおよび動的増加が有効になっている場合、バージョン3.1にロールバックする必要がある場合は、バケット数の動的増加を有効にしたテーブルを最初に削除する必要があります。その後、ロールバックする前に、ALTER SYSTEM CREATE IMAGEを使用してメタデータチェックポイントを手動で実行する必要があります。
-- すべてのパーティションのバケット数はStarRocksによって自動的に設定され、この数は固定されているため、バケット数のオンデマンドおよび動的増加は無効です。
ALTER TABLE details DISTRIBUTED BY RANDOM;
-- すべてのパーティションのバケット数はStarRocksによって自動的に設定され、バケット数のオンデマンドおよび動的増加が有効です。
ALTER TABLE details SET("bucket_size"="1073741824");
-- 特定のパーティションのバケット数を自動的に設定します。
ALTER TABLE details PARTITIONS (p20230103, p20230104)
DISTRIBUTED BY RANDOM;
-- 新しいパーティションのバケット数を自動的に設定します。
ALTER TABLE details ADD PARTITION p20230106 VALUES [('2023-01-06'), ('2023-01-07'))
DISTRIBUTED BY RANDOM; -
バケット数を手動で設定する
バケット数を手動で指定することもできます。パーティションのバケット数を計算するには、テーブル作成時にバケット数を手動で設定する際に使用したアプローチを参照してください。上記を参照。
- ハッシュバケット法で設定されたテーブル
- ランダムバケット法で設定されたテーブル
-- すべてのパーティションのバケット数を手動で設定
ALTER TABLE site_access
DISTRIBUTED BY HASH(site_id,city_code) BUCKETS 30;
-- 特定のパーティションのバケット数を手動で設定
ALTER TABLE site_access
partitions p20230104
DISTRIBUTED BY HASH(site_id,city_code) BUCKETS 30;
-- 新しいパーティションのバケット数を手動で設定
ALTER TABLE site_access
ADD PARTITION p20230106 VALUES [('2023-01-06'), ('2023-01-07'))
DISTRIBUTED BY HASH(site_id,city_code) BUCKETS 30;-- すべてのパーティションのバケット数を手動で設定
ALTER TABLE details
DISTRIBUTED BY RANDOM BUCKETS 30;
-- 特定のパーティションのバケット数を手動で設定
ALTER TABLE details
partitions p20230104
DISTRIBUTED BY RANDOM BUCKETS 30;
-- 新しいパーティションのバケット数を手動で設定
ALTER TABLE details
ADD PARTITION p20230106 VALUES [('2023-01-06'), ('2023-01-07'))
DISTRIBUTED BY RANDOM BUCKETS 30;動的パーティションのデフォルトのバケット数を手動で設定
ALTER TABLE details_dynamic
SET ("dynamic_partition.buckets"="xxx");
バケット数を確認する
テーブルを作��成した後、SHOW PARTITIONSを実行して、StarRocksが各パーティションに設定したバケット数を確認できます。ハッシュバケット法で設定されたテーブルは、各パーティションに固定されたバケット数を持っています。
- ランダムバケット法で設定されたテーブルの場合、バケット数のオンデマンドおよび動的増加が有効になっている場合、各パーティションのバケット数は動的に増加します。そのため、返される結果は各パーティションの現在のバケット数を表示します。
- このテーブルタイプの場合、パーティション内の実際の階層は次のようになります: パーティション > サブパーティション > バケット。バケット数を増やすために、StarRocksは実際に一定数のバケットを含む新しいサブパーティションを追加します。その結果、SHOW PARTITIONS文は同じパーティション名を持つ複数のデータ行を返すことがあり、同じパーティション内のサブパーティションの情報を表示します。
テーブル作成後のデータ分散の最適化(3.2以降)
注意
StarRocksの共有データモードは現在、この機能をサポートしていません。
ビジネスシナリオでクエリパターンやデータ量が進化するにつれて、テーブル作成時に指定された設定(バケッティング手法、バケット数、ソートキーなど)が新しいビジネスシナリオに適さなくなり、クエリパフォーマンスが低下する可能性があります。この時点で、ALTER TABLEを使用してバケッティング手法、バケット数、ソートキーを変更し、データ分散を最適化できます。例:
-
パーティション内のデータ量が大幅に増加した場合にバケット数を増やす
パーティション内のデータ量が以前よりも大幅に増加した場合、tabletサイズを一般的に1 GBから10 GBの範囲内に保つためにバケット数を変更する必要があります。
-
データスキューを回避するためにバケッティングキーを変更する
現在のバケッティングキーがデータスキューを引き起こす可能性がある場合(たとえば、
k1列のみがバケッティングキーとして設定されている場合)、より適切な列を指定するか、バケッティングキーに追加の列を追加する必要があります。例:ALTER TABLE t DISTRIBUTED BY HASH(k1, k2) BUCKETS 20;
-- StarRocksのバージョンが3.1以降で、テーブルが重複キーテーブルの場合、システムのデフォルトのバケッティング設定(ランダムバケット法とStarRocksによって自動的に設定されたバケット数)を直接使用することを検討できます。
ALTER TABLE t DISTRIBUTED BY RANDOM; -
クエリパターンの変更に応じてソートキーを適応させる
ビジネスクエリパターンが大幅に変更され、追加の列が条件列として使用される場合、ソートキーを調整することが有益です。例:
ALTER TABLE t ORDER BY k2, k1;
詳細については、ALTER TABLEを参照してください。
