ストレージとコンピュートの分離
ストレージとコンピュートを分離するシステムでは、データはAmazon S3、Google Cloud Storage、Azure Blob Storage、MinIOのような他のS3互換ストレージなど、低コストで信頼性の高いリモートストレージシステムに保存されます。ホットデータはローカルにキャッシュされ、キャッシュがヒットすると、クエリパフォーマンスはストレージとコンピュートが結合されたアーキテ�クチャと同等になります。コンピュートノード (CN) は、必要に応じて数秒で追加または削除できます。このアーキテクチャはストレージコストを削減し、リソースの分離を改善し、弾力性とスケーラビリティを提供します。
このチュートリアルでは以下をカバーします:
- DockerコンテナでのStarRocksの実行
- オブジェクトストレージとしてのMinIOの使用
- StarRocksの共有データ用の設定
- 2つの公開データセットのロード
- SELECTとJOINを使用したデータの分析
- 基本的なデータ変換 (ETLのT)
使用されるデータは、NYC OpenDataとNOAAのNational Centers for Environmental Informationによって提供されています。
これらのデータセットは非常に大きいため、このチュートリアルはStarRocksを使用する経験を得ることを目的としており、過去120年間のデータをロードすることはありません。Dockerイメージを実行し、このデータをDockerに4 GBのRAMを割り当てたマシンでロードできます。より大規模でフォールトトレラントなスケーラブルなデプロイメントについては、他のドキュメントを用意しており、後で提供します。
このドキュメントには多くの情報が含まれており、最初にステップバイステップの内容が提示され、最後に技術的な詳細が記載されています。これは以下の目的を順に達成するためです:
- 読者が共有データデプロイメントでデータをロードし、そのデータを分析できるようにする。
- 共有データデプロイメントの設定詳細を提供する。
- ロード中のデータ変換の基本を説明する。
前提条件
Docker
- Docker
- Dockerに割り当てられた4 GBのRAM
- Dockerに割り当てられた10 GBの空きディスクスペース
SQLクライアント
Docker環境で提供されるSQLクライアントを使用するか、システム上のものを使用できます。多くのMySQL互換クライアントが動作し、このガイドではDBeaverとMySQL WorkBenchの設定をカバーしています。
curl
curl はStarRocksにデータロードジョブを発行し、データセットをダウンロードするために使用されます。OSのプロンプトで curl または curl.exe を実行して、インストールされているか確認してください。curlがインストールされていない場合は、こちらからcurlを取得してください。
/etc/hosts
このガイドで使用されるインジェスト方法はStream Loadです。Stream LoadはFEサービスに接続してインジェストジョブを開始します。FEはその後、ジョブをバックエンドノード、つまりこのガイドではCNに割り当てます。インジェストジョブがCNに接続するためには、CNの名前がオペレーティングシステムに認識されている必要があります。次の行を /etc/hosts に追加してください:
127.0.0.1 starrocks-cn
用語
FE
フロントエンドノードは、メタデータ管理、クライアント接続管理、クエリプランニング、クエリスケジューリングを担当します。各FEはメモリ内にメタデータの完全なコピーを保存および維持し、FEs間での無差別なサービスを保証します。
CN
コンピュートノードは、共有データデプロイメントでクエリプランを実行する役割を担っています。
BE
バックエンドノードは、共有なしデプロイメントでデータストレージとクエリプランの実行の両方を担当します。
このガイドではBEsを使用しませんが、BEsとCNsの違いを理解するためにこの情報を含めています。
ラボファイルのダウンロード
ダウンロードするファイルは3つあります:
- StarRocksとMinIO環境をデプロイするDocker Composeファイル
- ニューヨーク市のクラッシュデータ
- 気象データ
このガイドでは、GNU Affero General Public Licenseの下で提供されるS3互換のオブジェクトストレージであるMinIOを使用します。
ラボファイルを保存するディレクトリを作成:
mkdir quickstart
cd quickstart
Docker Composeファイルのダウンロード
curl -O https://raw.githubusercontent.com/StarRocks/demo/master/documentation-samples/quickstart/docker-compose.yml
データのダウンロード
次の2つのデータセットをダウンロードします:
ニューヨーク市のクラッシュデータ
curl -O https://raw.githubusercontent.com/StarRocks/demo/master/documentation-samples/quickstart/datasets/NYPD_Crash_Data.csv
気象データ
curl -O https://raw.githubusercontent.com/StarRocks/demo/master/documentation-samples/quickstart/datasets/72505394728.csv
StarRocksとMinIOのデプロイ
docker compose up --detach --wait --wait-timeout 120
FE、CN、およびMinIOサービスが正常になるまで約30秒かかります。quickstart-minio_mc-1 コンテナは Waiting のステータスと終了コードを示します。終了コードが 0 の場合は成功を示します。
[+] Running 4/5
✔ Network quickstart_default Created 0.0s
✔ Container minio Healthy 6.8s
✔ Container starrocks-fe Healthy 29.3s
⠼ Container quickstart-minio_mc-1 Waiting 29.3s
✔ Container starrocks-cn Healthy 29.2s
container quickstart-minio_mc-1 exited (0)
MinIOのクレデンシャルを確認
StarRocksでMinIOをオブジェクトストレージとして使用するには、StarRocksにMinIOアクセスキーが必要です。アクセスキーはDockerサービスの起動時に生成されました。StarRocksがMinIOに接続する方法をよりよく理解するために、キーが存在することを確認してください。
MinIOウェブUIを開く
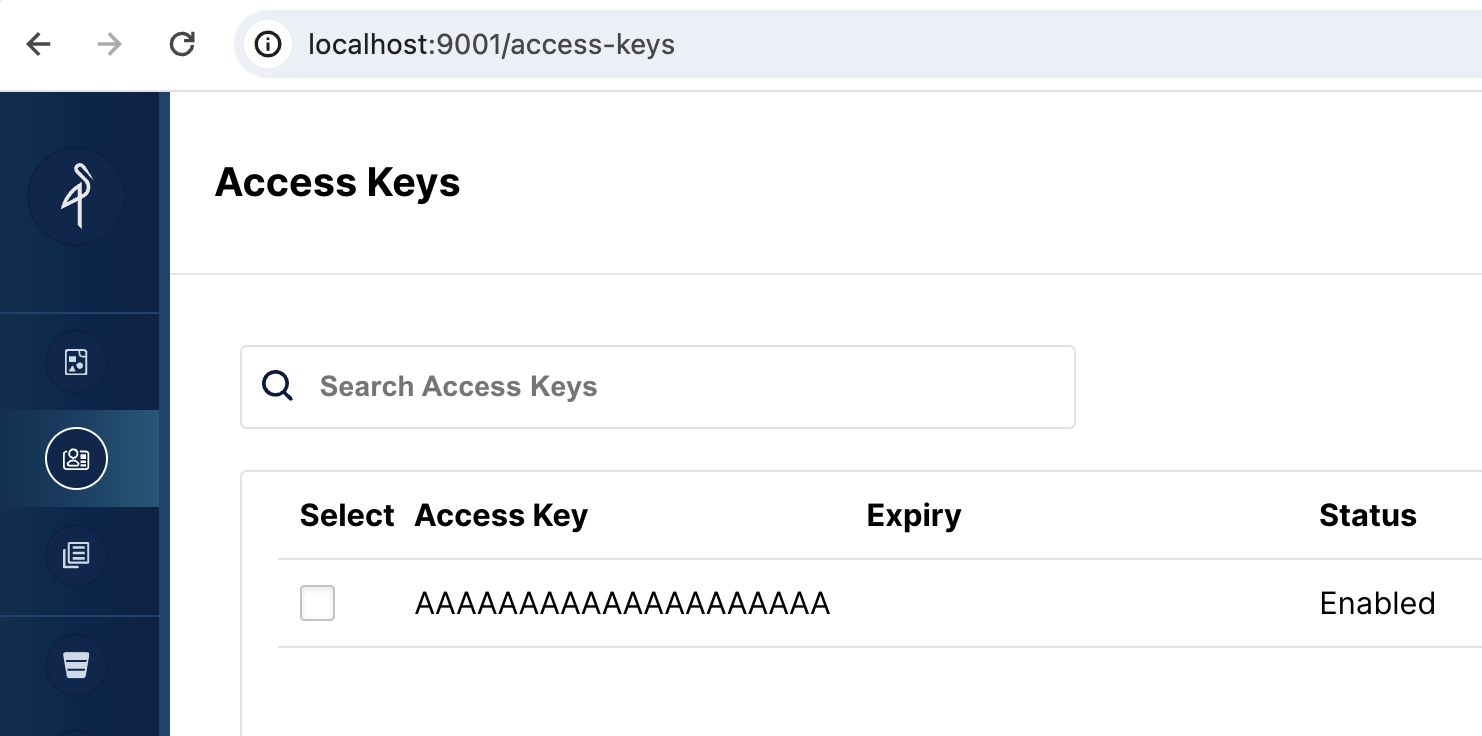
http://localhost:9001/access-keys にアクセスします。ユーザー名とパスワードはDocker composeファイルで指定されており、miniouser と miniopassword です。1つのアクセスキーがあることが確認��できます。キーは AAAAAAAAAAAAAAAAAAAA で、MinIOコンソールではシークレットは表示されませんが、Docker composeファイルには BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB と記載されています:
MinIOウェブUIにアクセスキーが表示されない場合は、minio_mc サービスのログを確認してください:
docker compose logs minio_mc
minio_mc ポッドを再実行してみてください:
docker compose run minio_mc
SQLクライアント
These three clients are tested with this tutorial, you only need one:
- mysql CLI: You can run this from the Docker environment or your machine.
- DBeaver is available as a community version and a Pro version.
- MySQL Workbench
Configuring the client
- mysql CLI
- DBeaver
- MySQL Workbench
The easiest way to use the mysql CLI is to run it from the StarRocks container starrocks-fe:
docker compose exec starrocks-fe \
mysql -P 9030 -h 127.0.0.1 -u root --prompt="StarRocks > "
All docker compose commands must be run from the directory containing the docker-compose.yml file.
If you would like to install the mysql CLI expand mysql client install below:
mysql client install
- macOS: If you use Homebrew and do not need MySQL Server run
brew install mysqlto install the CLI. - Linux: Check your repository system for the
mysqlclient. For example,yum install mariadb. - Microsoft Windows: Install the MySQL Community Server and run the provided client, or run
mysqlfrom WSL.
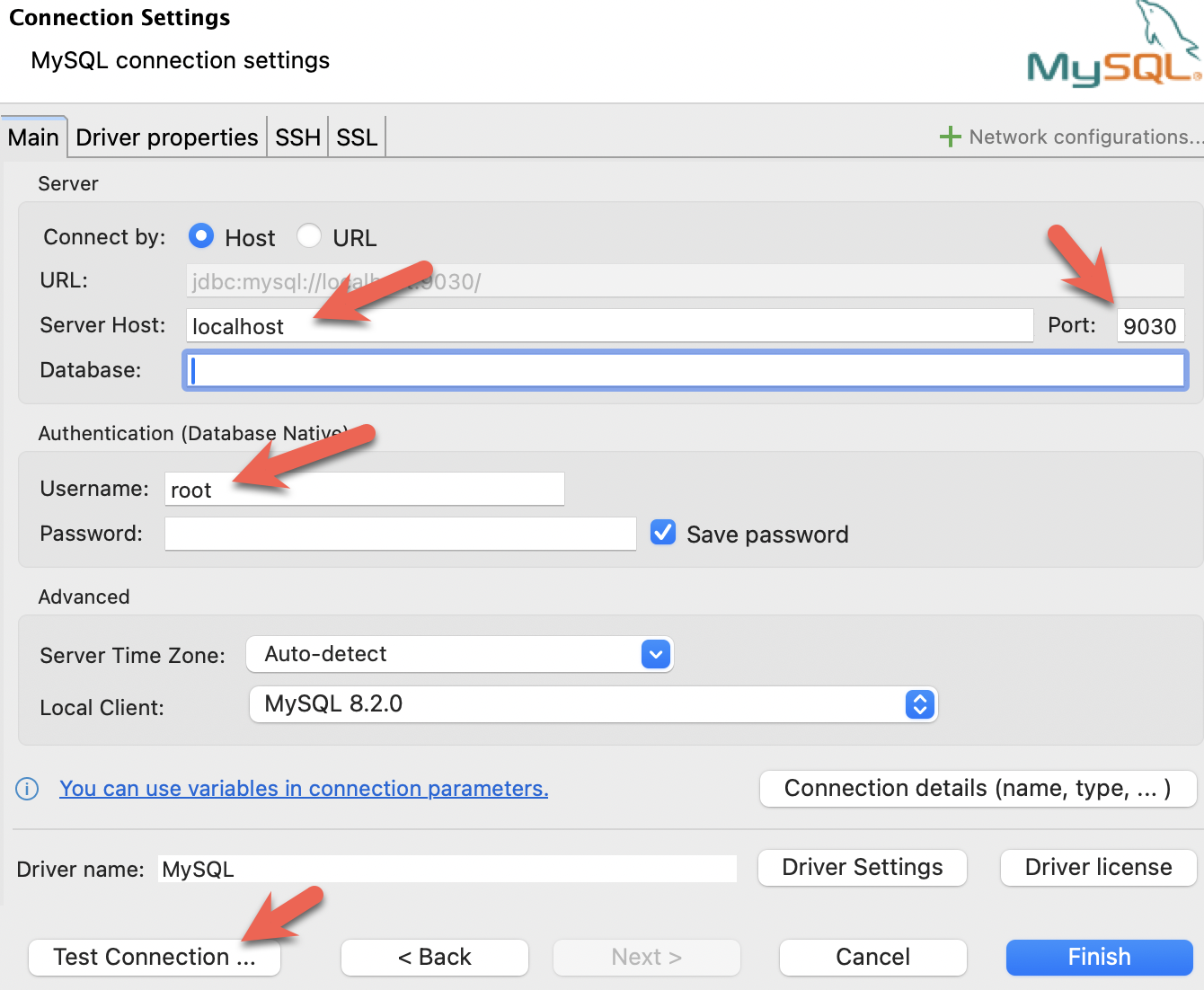
- Install DBeaver, and add a connection:

- Configure the port, IP, and username. Test the connection, and click Finish if the test succeeds:
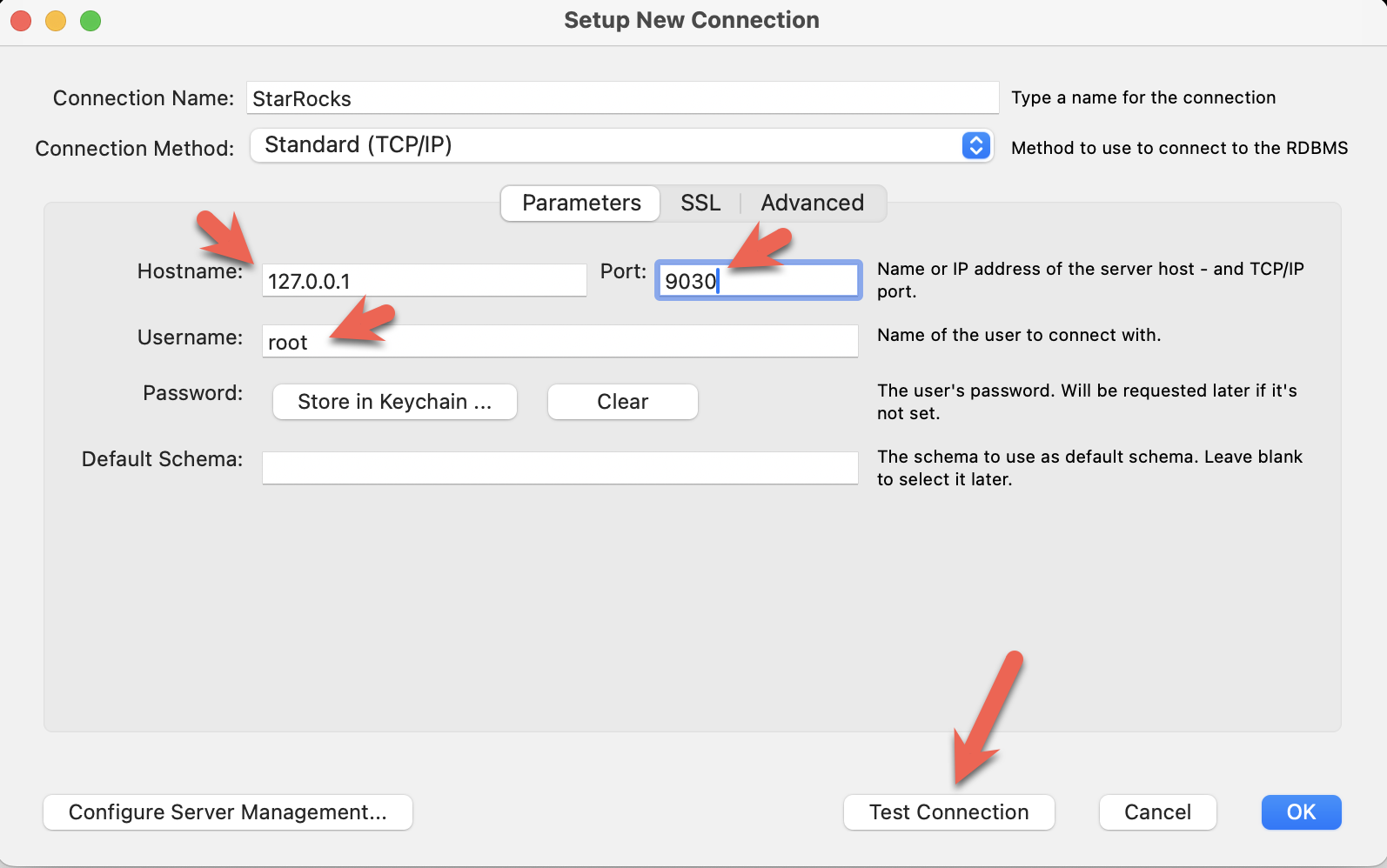
- Install the MySQL Workbench, and add a connection.
- Configure the port, IP, and username and then test the connection:
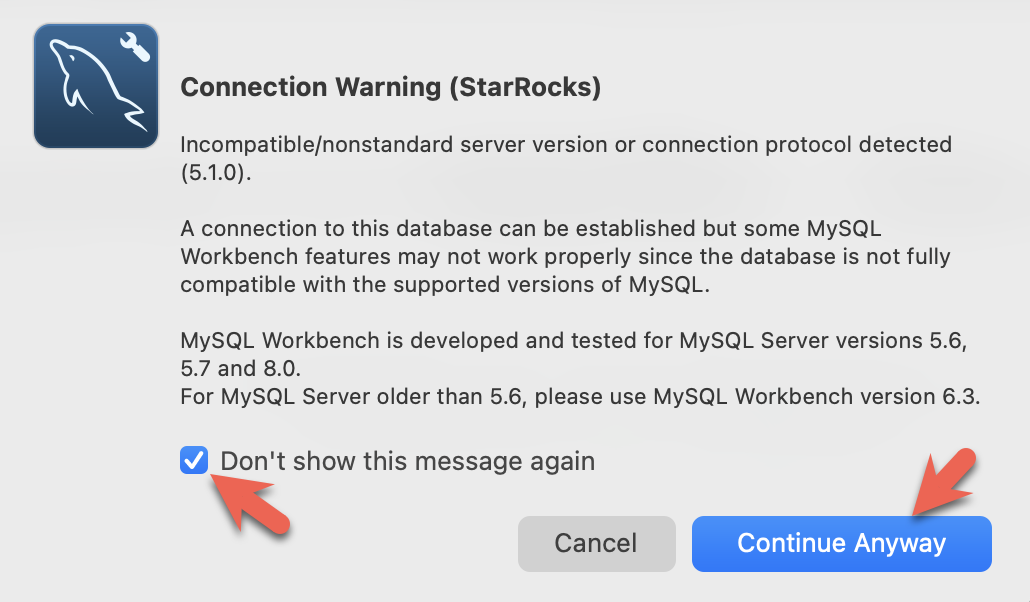
- You will see warnings from the Workbench as it is checking for a specific MySQL version. You can ignore the warnings and when prompted, you can configure Workbench to stop displaying the warnings:
StarRocksの共有データ用設定
この時点でStarRocksが実行され、MinIOも実行されています。MinIOアクセスキーはStarRocksとMinIOを接続するために使用されます。StarRocksが起動したときにMinIOとの接続を確立し、MinIOにデフォルトのストレージボリュームを作成しました。
これはMinIOを使用するデフォルトストレージボリュームを設定するために使用される設定です(これもDocker composeファイルにあります)。設定はこのガイドの最後に詳細に説明されますが、今は aws_s3_access_key がMinIOコンソールで見た文字列に設定されていることと、run_mode が shared_data に設定されていることに注意してください:
# enable shared data, set storage type, set endpoint
run_mode = shared_data
cloud_native_storage_type = S3
aws_s3_endpoint = minio:9000
# set the path in MinIO
aws_s3_path = starrocks
# credentials for MinIO object read/write
aws_s3_access_key = AAAAAAAAAAAAAAAAAAAA
aws_s3_secret_key = BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB
aws_s3_use_instance_profile = false
aws_s3_use_aws_sdk_default_behavior = false
# Set this to false if you do not want default
# storage created in the object storage using
# the details provided above
enable_load_volume_from_conf = true
SQLクライアントでStarRocksに接続
docker-compose.yml ファイルを含むディレクトリからこのコマンドを実行してください。
mysql CLI以外のクライアントを使用している場合は、今それを開いてください。
docker compose exec starrocks-fe \
mysql -P9030 -h127.0.0.1 -uroot --prompt="StarRocks > "
ストレージボリュームを確認
SHOW STORAGE VOLUMES;
+------------------------+
| Storage Volume |
+------------------------+
| builtin_storage_volume |
+------------------------+
1 row in set (0.00 sec)
DESC STORAGE VOLUME builtin_storage_volume\G
このドキュメントの一部のSQL、およびStarRocksドキュメントの多くの他のドキュメントは、セミコロンの代わりに \G で終わります。mysql CLIでは、 \G はクエリ結果を縦に表示します。
多くのSQLクライアントは縦のフォーマット出力を解釈しないため、\G を ; に置き換える必要があります。
*************************** 1. row ***************************
Name: builtin_storage_volume
Type: S3
IsDefault: true
Location: s3://starrocks
Params: {"aws.s3.access_key":"******","aws.s3.secret_key":"******","aws.s3.endpoint":"minio:9000","aws.s3.region":"","aws.s3.use_instance_profile":"false","aws.s3.use_aws_sdk_default_behavior":"false"}
Enabled: true
Comment:
1 row in set (0.03 sec)
パラメータが設定と一致していることを確認してください。
フォルダ builtin_storage_volume は、バケットにデータが書き込まれるまでMinIOオブジェクトリストに表示されません。
テーブルを作成
Create a database
Type these two lines in at the StarRocks > prompt and press enter after each:
CREATE DATABASE IF NOT EXISTS quickstart;
USE quickstart;
Create two tables
Crashdata
The crash dataset contains many more fields than these, the schema has been trimmed down to include only the fields that might be useful to answer questions about the impact weather has on driving conditions.
CREATE TABLE IF NOT EXISTS crashdata (
CRASH_DATE DATETIME,
BOROUGH STRING,
ZIP_CODE STRING,
LATITUDE INT,
LONGITUDE INT,
LOCATION STRING,
ON_STREET_NAME STRING,
CROSS_STREET_NAME STRING,
OFF_STREET_NAME STRING,
CONTRIBUTING_FACTOR_VEHICLE_1 STRING,
CONTRIBUTING_FACTOR_VEHICLE_2 STRING,
COLLISION_ID INT,
VEHICLE_TYPE_CODE_1 STRING,
VEHICLE_TYPE_CODE_2 STRING
);
Weatherdata
Similar to the crash data, the weather dataset has many more columns (a total of 125 columns) and only the ones that are expected to answer the questions are included in the database.
CREATE TABLE IF NOT EXISTS weatherdata (
DATE DATETIME,
NAME STRING,
HourlyDewPointTemperature STRING,
HourlyDryBulbTemperature STRING,
HourlyPrecipitation STRING,
HourlyPresentWeatherType STRING,
HourlyPressureChange STRING,
HourlyPressureTendency STRING,
HourlyRelativeHumidity STRING,
HourlySkyConditions STRING,
HourlyVisibility STRING,
HourlyWetBulbTemperature STRING,
HourlyWindDirection STRING,
HourlyWindGustSpeed STRING,
HourlyWindSpeed STRING
);
2つのデータセットをロード
StarRocksにデータをロードする�方法は多数あります。このチュートリアルでは、最も簡単な方法はcurlとStarRocks Stream Loadを使用することです。
データセットをダウンロードしたディレクトリからこれらのcurlコマンドを実行してください。
パスワードを求められます。MySQLの root ユーザーにパスワードを割り当てていない場合は、Enterキーを押してください。
curl コマンドは複雑に見えますが、チュートリアルの最後で詳細に説明されています。今は、コマンドを実行してデータを分析するためのSQLを実行し、最後にデータロードの詳細を読むことをお勧めします。
ニューヨーク市の衝突データ - クラッシュ
curl --location-trusted -u root \
-T ./NYPD_Crash_Data.csv \
-H "label:crashdata-0" \
-H "column_separator:," \
-H "skip_header:1" \
-H "enclose:\"" \
-H "max_filter_ratio:1" \
-H "columns:tmp_CRASH_DATE, tmp_CRASH_TIME, CRASH_DATE=str_to_date(concat_ws(' ', tmp_CRASH_DATE, tmp_CRASH_TIME), '%m/%d/%Y %H:%i'),BOROUGH,ZIP_CODE,LATITUDE,LONGITUDE,LOCATION,ON_STREET_NAME,CROSS_STREET_NAME,OFF_STREET_NAME,NUMBER_OF_PERSONS_INJURED,NUMBER_OF_PERSONS_KILLED,NUMBER_OF_PEDESTRIANS_INJURED,NUMBER_OF_PEDESTRIANS_KILLED,NUMBER_OF_CYCLIST_INJURED,NUMBER_OF_CYCLIST_KILLED,NUMBER_OF_MOTORIST_INJURED,NUMBER_OF_MOTORIST_KILLED,CONTRIBUTING_FACTOR_VEHICLE_1,CONTRIBUTING_FACTOR_VEHICLE_2,CONTRIBUTING_FACTOR_VEHICLE_3,CONTRIBUTING_FACTOR_VEHICLE_4,CONTRIBUTING_FACTOR_VEHICLE_5,COLLISION_ID,VEHICLE_TYPE_CODE_1,VEHICLE_TYPE_CODE_2,VEHICLE_TYPE_CODE_3,VEHICLE_TYPE_CODE_4,VEHICLE_TYPE_CODE_5" \
-XPUT http://localhost:8030/api/quickstart/crashdata/_stream_load
上記のコマンドの出力です。最初のハイライトされたセクションは、期待される結果(OKと1行を除くすべての行が挿入されたこと)を示しています。1行は列数が正しくないためフィルタリングされました。
Enter host password for user 'root':
{
"TxnId": 2,
"Label": "crashdata-0",
"Status": "Success",
"Message": "OK",
"NumberTotalRows": 423726,
"NumberLoadedRows": 423725,
"NumberFilteredRows": 1,
"NumberUnselectedRows": 0,
"LoadBytes": 96227746,
"LoadTimeMs": 1013,
"BeginTxnTimeMs": 21,
"StreamLoadPlanTimeMs": 63,
"ReadDataTimeMs": 563,
"WriteDataTimeMs": 870,
"CommitAndPublishTimeMs": 57,
"ErrorURL": "http://starrocks-cn:8040/api/_load_error_log?file=error_log_da41dd88276a7bfc_739087c94262ae9f"
}%
エラーが発生した場合、出力にはエラーメッセージを確認するためのURLが提供されます。エラーメッセージには、Stream Loadジョブが割り当てられたバックエンドノード(starrocks-cn)も含まれています。/etc/hosts ファイルに starrocks-cn のエントリを追加したため��、そこに移動してエラーメッセージを読むことができるはずです。
このチュートリアルの開発中に見られた内容の要約を展開します:
ブラウザでのエラーメッセージの読み取り
Error: Value count does not match column count. Expect 29, but got 32.
Column delimiter: 44,Row delimiter: 10.. Row: 09/06/2015,14:15,,,40.6722269,-74.0110059,"(40.6722269, -74.0110059)",,,"R/O 1 BEARD ST. ( IKEA'S
09/14/2015,5:30,BRONX,10473,40.814551,-73.8490955,"(40.814551, -73.8490955)",TORRY AVENUE ,NORTON AVENUE ,,0,0,0,0,0,0,0,0,Driver Inattention/Distraction,Unspecified,,,,3297457,PASSENGER VEHICLE,PASSENGER VEHICLE,,,
気象データ
クラッシュデータをロードしたのと同じ方法で気象データセットをロードします。
curl --location-trusted -u root \
-T ./72505394728.csv \
-H "label:weather-0" \
-H "column_separator:," \
-H "skip_header:1" \
-H "enclose:\"" \
-H "max_filter_ratio:1" \
-H "columns: STATION, DATE, LATITUDE, LONGITUDE, ELEVATION, NAME, REPORT_TYPE, SOURCE, HourlyAltimeterSetting, HourlyDewPointTemperature, HourlyDryBulbTemperature, HourlyPrecipitation, HourlyPresentWeatherType, HourlyPressureChange, HourlyPressureTendency, HourlyRelativeHumidity, HourlySkyConditions, HourlySeaLevelPressure, HourlyStationPressure, HourlyVisibility, HourlyWetBulbTemperature, HourlyWindDirection, HourlyWindGustSpeed, HourlyWindSpeed, Sunrise, Sunset, DailyAverageDewPointTemperature, DailyAverageDryBulbTemperature, DailyAverageRelativeHumidity, DailyAverageSeaLevelPressure, DailyAverageStationPressure, DailyAverageWetBulbTemperature, DailyAverageWindSpeed, DailyCoolingDegreeDays, DailyDepartureFromNormalAverageTemperature, DailyHeatingDegreeDays, DailyMaximumDryBulbTemperature, DailyMinimumDryBulbTemperature, DailyPeakWindDirection, DailyPeakWindSpeed, DailyPrecipitation, DailySnowDepth, DailySnowfall, DailySustainedWindDirection, DailySustainedWindSpeed, DailyWeather, MonthlyAverageRH, MonthlyDaysWithGT001Precip, MonthlyDaysWithGT010Precip, MonthlyDaysWithGT32Temp, MonthlyDaysWithGT90Temp, MonthlyDaysWithLT0Temp, MonthlyDaysWithLT32Temp, MonthlyDepartureFromNormalAverageTemperature, MonthlyDepartureFromNormalCoolingDegreeDays, MonthlyDepartureFromNormalHeatingDegreeDays, MonthlyDepartureFromNormalMaximumTemperature, MonthlyDepartureFromNormalMinimumTemperature, MonthlyDepartureFromNormalPrecipitation, MonthlyDewpointTemperature, MonthlyGreatestPrecip, MonthlyGreatestPrecipDate, MonthlyGreatestSnowDepth, MonthlyGreatestSnowDepthDate, MonthlyGreatestSnowfall, MonthlyGreatestSnowfallDate, MonthlyMaxSeaLevelPressureValue, MonthlyMaxSeaLevelPressureValueDate, MonthlyMaxSeaLevelPressureValueTime, MonthlyMaximumTemperature, MonthlyMeanTemperature, MonthlyMinSeaLevelPressureValue, MonthlyMinSeaLevelPressureValueDate, MonthlyMinSeaLevelPressureValueTime, MonthlyMinimumTemperature, MonthlySeaLevelPressure, MonthlyStationPressure, MonthlyTotalLiquidPrecipitation, MonthlyTotalSnowfall, MonthlyWetBulb, AWND, CDSD, CLDD, DSNW, HDSD, HTDD, NormalsCoolingDegreeDay, NormalsHeatingDegreeDay, ShortDurationEndDate005, ShortDurationEndDate010, ShortDurationEndDate015, ShortDurationEndDate020, ShortDurationEndDate030, ShortDurationEndDate045, ShortDurationEndDate060, ShortDurationEndDate080, ShortDurationEndDate100, ShortDurationEndDate120, ShortDurationEndDate150, ShortDurationEndDate180, ShortDurationPrecipitationValue005, ShortDurationPrecipitationValue010, ShortDurationPrecipitationValue015, ShortDurationPrecipitationValue020, ShortDurationPrecipitationValue030, ShortDurationPrecipitationValue045, ShortDurationPrecipitationValue060, ShortDurationPrecipitationValue080, ShortDurationPrecipitationValue100, ShortDurationPrecipitationValue120, ShortDurationPrecipitationValue150, ShortDurationPrecipitationValue180, REM, BackupDirection, BackupDistance, BackupDistanceUnit, BackupElements, BackupElevation, BackupEquipment, BackupLatitude, BackupLongitude, BackupName, WindEquipmentChangeDate" \
-XPUT http://localhost:8030/api/quickstart/weatherdata/_stream_load
MinIOにデータが保存されていることを確認
MinIOを開き、http://localhost:9001/browser/starrocks/ にアクセスして、starrocks/shared/ 以下の各ディレクトリに data、metadata、schema エントリがあることを確認してください。
starrocks/shared/ 以下のフォルダ名は、データをロードするときに生成されます。shared の下に1つのディレクトリが表示され、その下にさらに2つのディレクトリが表示されます。それぞれのディレクトリ内に、データ、メタデータ、およびスキーマエントリが見つかります。
質問に答える
These queries can be run in your SQL client. All of the queries use the quickstart database.
USE quickstart;
How many crashes are there per hour in NYC?
SELECT COUNT(*),
date_trunc("hour", crashdata.CRASH_DATE) AS Time
FROM crashdata
GROUP BY Time
ORDER BY Time ASC
LIMIT 200;
Here is part of the output. Note that I am looking closer at January 6th and 7th as this is Monday and Tuesday of a non-holiday week. Looking at New Years Day is probably not indicative of a normal morning during rush-hour traffic.
| 14 | 2014-01-06 06:00:00 |
| 16 | 2014-01-06 07:00:00 |
| 43 | 2014-01-06 08:00:00 |
| 44 | 2014-01-06 09:00:00 |
| 21 | 2014-01-06 10:00:00 |
| 28 | 2014-01-06 11:00:00 |
| 34 | 2014-01-06 12:00:00 |
| 31 | 2014-01-06 13:00:00 |
| 35 | 2014-01-06 14:00:00 |
| 36 | 2014-01-06 15:00:00 |
| 33 | 2014-01-06 16:00:00 |
| 40 | 2014-01-06 17:00:00 |
| 35 | 2014-01-06 18:00:00 |
| 23 | 2014-01-06 19:00:00 |
| 16 | 2014-01-06 20:00:00 |
| 12 | 2014-01-06 21:00:00 |
| 17 | 2014-01-06 22:00:00 |
| 14 | 2014-01-06 23:00:00 |
| 10 | 2014-01-07 00:00:00 |
| 4 | 2014-01-07 01:00:00 |
| 1 | 2014-01-07 02:00:00 |
| 3 | 2014-01-07 03:00:00 |
| 2 | 2014-01-07 04:00:00 |
| 6 | 2014-01-07 06:00:00 |
| 16 | 2014-01-07 07:00:00 |
| 41 | 2014-01-07 08:00:00 |
| 37 | 2014-01-07 09:00:00 |
| 33 | 2014-01-07 10:00:00 |
It looks like about 40 accidents on a Monday or Tuesday morning during rush hour traffic, and around the same at 17:00 hours.
What is the average temperature in NYC?
SELECT avg(HourlyDryBulbTemperature),
date_trunc("hour", weatherdata.DATE) AS Time
FROM weatherdata
GROUP BY Time
ORDER BY Time ASC
LIMIT 100;
Output:
Note that this is data from 2014, NYC has not been this cold lately.
+-------------------------------+---------------------+
| avg(HourlyDryBulbTemperature) | Time |
+-------------------------------+---------------------+
| 25 | 2014-01-01 00:00:00 |
| 25 | 2014-01-01 01:00:00 |
| 24 | 2014-01-01 02:00:00 |
| 24 | 2014-01-01 03:00:00 |
| 24 | 2014-01-01 04:00:00 |
| 24 | 2014-01-01 05:00:00 |
| 25 | 2014-01-01 06:00:00 |
| 26 | 2014-01-01 07:00:00 |
Is it safe to drive in NYC when visibility is poor?
Let's look at the number of crashes when visibility is poor (between 0 and 1.0 miles). To answer this question use a JOIN across the two tables on the DATETIME column.
SELECT COUNT(DISTINCT c.COLLISION_ID) AS Crashes,
truncate(avg(w.HourlyDryBulbTemperature), 1) AS Temp_F,
truncate(avg(w.HourlyVisibility), 2) AS Visibility,
max(w.HourlyPrecipitation) AS Precipitation,
date_format((date_trunc("hour", c.CRASH_DATE)), '%d %b %Y %H:%i') AS Hour
FROM crashdata c
LEFT JOIN weatherdata w
ON date_trunc("hour", c.CRASH_DATE)=date_trunc("hour", w.DATE)
WHERE w.HourlyVisibility BETWEEN 0.0 AND 1.0
GROUP BY Hour
ORDER BY Crashes DESC
LIMIT 100;
The highest number of crashes in a single hour during low visibility is 129. There are multiple things to consider:
- February 3rd 2014 was a Monday
- 8AM is rush hour
- It was raining (0.12 inches or precipitation that hour)
- The temperature is 32 degrees F (the freezing point for water)
- Visibility is bad at 0.25 miles, normal for NYC is 10 miles
+---------+--------+------------+---------------+-------------------+
| Crashes | Temp_F | Visibility | Precipitation | Hour |
+---------+--------+------------+---------------+-------------------+
| 129 | 32 | 0.25 | 0.12 | 03 Feb 2014 08:00 |
| 114 | 32 | 0.25 | 0.12 | 03 Feb 2014 09:00 |
| 104 | 23 | 0.33 | 0.03 | 09 Jan 2015 08:00 |
| 96 | 26.3 | 0.33 | 0.07 | 01 Mar 2015 14:00 |
| 95 | 26 | 0.37 | 0.12 | 01 Mar 2015 15:00 |
| 93 | 35 | 0.75 | 0.09 | 18 Jan 2015 09:00 |
| 92 | 31 | 0.25 | 0.12 | 03 Feb 2014 10:00 |
| 87 | 26.8 | 0.5 | 0.09 | 01 Mar 2015 16:00 |
| 85 | 55 | 0.75 | 0.20 | 23 Dec 2015 17:00 |
| 85 | 20 | 0.62 | 0.01 | 06 Jan 2015 11:00 |
| 83 | 19.6 | 0.41 | 0.04 | 05 Mar 2015 13:00 |
| 80 | 20 | 0.37 | 0.02 | 06 Jan 2015 10:00 |
| 76 | 26.5 | 0.25 | 0.06 | 05 Mar 2015 09:00 |
| 71 | 26 | 0.25 | 0.09 | 05 Mar 2015 10:00 |
| 71 | 24.2 | 0.25 | 0.04 | 05 Mar 2015 11:00 |
What about driving in icy conditions?
Water vapor can desublimate to ice at 40 degrees F; this query looks at temps between 0 and 40 degrees F.
SELECT COUNT(DISTINCT c.COLLISION_ID) AS Crashes,
truncate(avg(w.HourlyDryBulbTemperature), 1) AS Temp_F,
truncate(avg(w.HourlyVisibility), 2) AS Visibility,
max(w.HourlyPrecipitation) AS Precipitation,
date_format((date_trunc("hour", c.CRASH_DATE)), '%d %b %Y %H:%i') AS Hour
FROM crashdata c
LEFT JOIN weatherdata w
ON date_trunc("hour", c.CRASH_DATE)=date_trunc("hour", w.DATE)
WHERE w.HourlyDryBulbTemperature BETWEEN 0.0 AND 40.5
GROUP BY Hour
ORDER BY Crashes DESC
LIMIT 100;
The results for freezing temperatures suprised me a little, I did not expect too much traffic on a Sunday morning in the city on a cold January day.A quick look at weather.com showed that there was a big storm with many crashes that day, just like what can be seen in the data.
+---------+--------+------------+---------------+-------------------+
| Crashes | Temp_F | Visibility | Precipitation | Hour |
+---------+--------+------------+---------------+-------------------+
| 192 | 34 | 1.5 | 0.09 | 18 Jan 2015 08:00 |
| 170 | 21 | NULL | | 21 Jan 2014 10:00 |
| 145 | 19 | NULL | | 21 Jan 2014 11:00 |
| 138 | 33.5 | 5 | 0.02 | 18 Jan 2015 07:00 |
| 137 | 21 | NULL | | 21 Jan 2014 09:00 |
| 129 | 32 | 0.25 | 0.12 | 03 Feb 2014 08:00 |
| 114 | 32 | 0.25 | 0.12 | 03 Feb 2014 09:00 |
| 104 | 23 | 0.7 | 0.04 | 09 Jan 2015 08:00 |
| 98 | 16 | 8 | 0.00 | 06 Mar 2015 08:00 |
| 96 | 26.3 | 0.33 | 0.07 | 01 Mar 2015 14:00 |
Drive carefully!
StarRocksの共有データ用設定
StarRocksを共有データで使用する経験を積んだ今、設定を理解することが重要です。
CN設定
ここで使用されるCN設定はデフォルトです。CNは共有データの使用を目的として設計されています。デフォルトの設定は以下の通りです。変更する必要はありません。
sys_log_level = INFO
# ports for admin, web, heartbeat service
be_port = 9060
be_http_port = 8040
heartbeat_service_port = 9050
brpc_port = 8060
starlet_port = 9070
FE設定
FE設定はデフォルトとは少し異なります。FEはデータがBEノードのローカルディスクではなくオブジェクトストレージに保存されることを期待するように設定する必要があります。
docker-compose.yml ��ファイルは command でFE設定を生成します。
# enable shared data, set storage type, set endpoint
run_mode = shared_data
cloud_native_storage_type = S3
aws_s3_endpoint = minio:9000
# set the path in MinIO
aws_s3_path = starrocks
# credentials for MinIO object read/write
aws_s3_access_key = AAAAAAAAAAAAAAAAAAAA
aws_s3_secret_key = BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB
aws_s3_use_instance_profile = false
aws_s3_use_aws_sdk_default_behavior = false
# Set this to false if you do not want default
# storage created in the object storage using
# the details provided above
enable_load_volume_from_conf = true
この設定ファイルにはFEのデフォルトエントリは含まれていません。共有データ設定のみが示されています。
デフォルトではないFE設定:
多くの設定パラメータは s3_ で始まります。このプレフィックスは、すべてのAmazon S3互換ストレージタイプ(例:S3、GCS、MinIO)に使用されます。Azure Blob Storageを使用する場合、プレフィックスは azure_ です。
run_mode=shared_data
これは共有データの使用を有効にします。
cloud_native_storage_type=S3
これはS3互換ストレージまたはAzure Blob Storageが使用されるかどうかを指定します。MinIOの場合、常にS3です。
aws_s3_endpoint=minio:9000
ポート番号を含むMinIOエンドポイント。
aws_s3_path=starrocks
バケット名。
aws_s3_access_key=AA
MinIOアクセスキー。
aws_s3_secret_key=BB
MinIOアクセスキーシークレット。
aws_s3_use_instance_profile=false
MinIOを使用する場合、アクセスキーが使用されるため、インスタンスプロファイルはMinIOでは使用されません。
aws_s3_use_aws_sdk_default_behavior=false
MinIOを使用する場合、このパラメータは常にfalseに設定されます。
enable_load_volume_from_conf=true
これがtrueの場合、MinIOオブジェクトストレージを使用して builtin_storage_volume という名前のStarRocksストレージボリュームが作成され、作成するテーブルのデフォルトストレージボリュームとして設定されます。
FQDNモードの設定
FEを起動するコマンドも変更されています。Docker ComposeファイルのFEサービスコマンドには、--host_type FQDN オプションが追加されています。host_type を FQDN に設定することで、Stream LoadジョブがCNポッドの完全修飾ドメイン名に転送されます。これは、IPアドレスがDocker環境に割り当てられた範囲内にあり、通常ホストマシンから利用できないためです。
これら3つの変更により、CNがホストネットワークに転送されることが可能になります:
--host_typeをFQDNに設定- CNポート8040をホストネットワークに公開
127.0.0.1を指すstarrocks-cnのエントリをホストファイルに追加
まとめ
このチュートリアルでは以下を行いました:
- DockerでStarRocksとMinIOをデプロイ
- MinIOアクセスキーを作成
- MinIOを使用するStarRocksストレージボリュームを設定
- ニューヨーク市が提供するクラッシュデータとNOAAが提供する気象データをロード
- SQL JOINを使用して、視界が悪いまたは氷結した道路での運転が悪い考えであることを発見
学ぶべきことはまだあります。Stream Load中に行われたデータ変換については意図的に詳しく説明していません。curlコマンドのメモにその詳細があります。
curlコマンドのメモ
StarRocks Stream Load and curl take many arguments. Only the ones used in this tutorial are described here, the rest will be linked to in the more information section.
--location-trusted
This configures curl to pass credentials to any redirected URLs.
-u root
The username used to log in to StarRocks
-T filename
T is for transfer, the filename to transfer.
label:name-num
The label to associate with this Stream Load job. The label must be unique, so if you run the job multiple times you can add a number and keep incrementing that.
column_separator:,
If you load a file that uses a single , then set it as shown above, if you use a different delimiter then set that delimiter here. Common choices are \t, ,, and |.
skip_header:1
Some CSV files have a single header row with all of the column names listed, and some add a second line with datatypes. Set skip_header to 1 or 2 if you have one or two header lines, and set it to 0 if you have none.
enclose:\"
It is common to enclose strings that contain embedded commas with double-quotes. The sample datasets used in this tutorial have geo locations that contain commas and so the enclose setting is set to \". Remember to escape the " with a \.
max_filter_ratio:1
This allows some errors in the data. Ideally this would be set to 0 and the job would fail with any errors. It is set to 1 to allow all rows to fail during debugging.
columns:
The mapping of CSV file columns to StarRocks table columns. You will notice that there are many more columns in the CSV files than columns in the table. Any columns that are not included in the table are skipped.
You will also notice that there is some transformation of data included in the columns: line for the crash dataset. It is very common to find dates and times in CSV files that do not conform to standards. This is the logic for converting the CSV data for the time and date of the crash to a DATETIME type:
The columns line
This is the beginning of one data record. The date is in MM/DD/YYYY format, and the time is HH:MI. Since DATETIME is generally YYYY-MM-DD HH:MI:SS we need to transform this data.
08/05/2014,9:10,BRONX,10469,40.8733019,-73.8536375,"(40.8733019, -73.8536375)",
This is the beginning of the columns: parameter:
-H "columns:tmp_CRASH_DATE, tmp_CRASH_TIME, CRASH_DATE=str_to_date(concat_ws(' ', tmp_CRASH_DATE, tmp_CRASH_TIME), '%m/%d/%Y %H:%i')
This instructs StarRocks to:
- Assign the content of the first column of the CSV file to
tmp_CRASH_DATE - Assign the content of the second column of the CSV file to
tmp_CRASH_TIME concat_ws()concatenatestmp_CRASH_DATEandtmp_CRASH_TIMEtogether with a space between themstr_to_date()creates a DATETIME from the concatenated string- store the resulting DATETIME in the column
CRASH_DATE
さらなる情報
Motor Vehicle Collisions - Crashes データセットは、ニューヨーク市によってこれらの利用規約およびプライバシーポリシーに基づいて提供されています。
Local Climatological Data (LCD) は、NOAAによってこの免責事項およびこのプライバシーポリシーと共に提供されています。
