ロードオプション
データロードは、ビジネス要件に基づいてさまざまなデータソースから生のデータをクレンジングおよび変換し、結果のデータを StarRocks にロードして分析を容易にするプロセスです。
StarRocks は、データロードのためのさまざまなオプションを提供しています。
- ロード方法: Insert、Stream Load、Broker Load、Pipe、Routine Load、Spark Load
- エコシステムツール: StarRocks Connector for Apache Kafka®(Kafka コネクタ)、StarRocks Connector for Apache Spark™(Spark コネクタ)、StarRocks Connector for Apache Flink®(Flink コネクタ)、および SMT、DataX、CloudCanal、Kettle Connector などの他のツール
- API: Stream Load トランザクションインターフェース
これらのオプションはそれぞれ独自の利点を持ち、独自のデータソースシステムをサポートしています。
このトピックでは、これらのオプションの概要を提供し、データソース、ビジネスシナリオ、データ量、データファイル形式、ロード頻度に基づいて選択するロードオプションを決定するのに役立つ比較を行います。
ロードオプションの紹介
このセクションでは、StarRocks で利用可能なロードオプションの特徴とビジネスシナリオについて主に説明します。
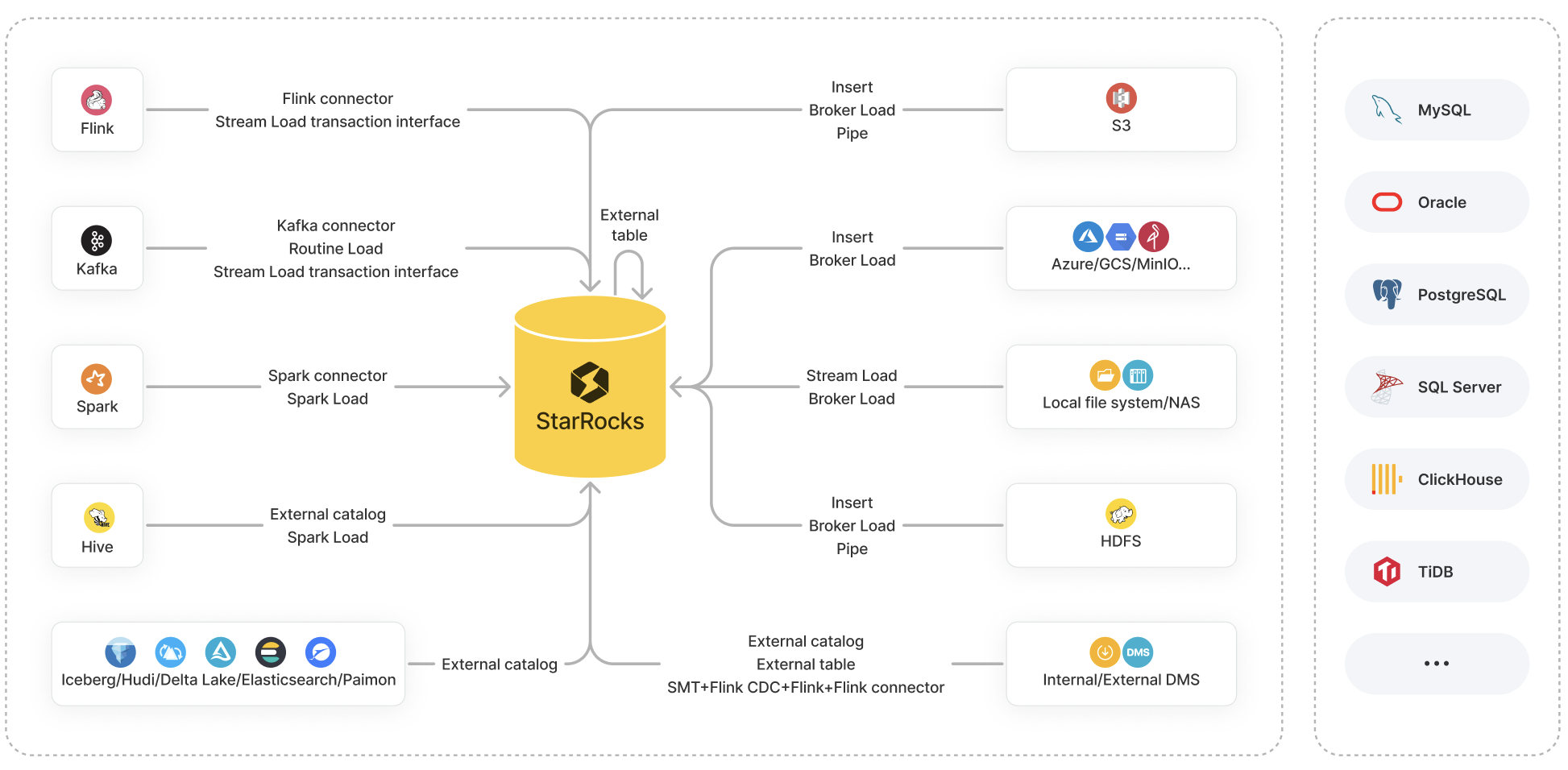
以下のセクションでは、「バッチ」または「バッチロード」は、指定されたソースから大量のデータを一度に StarRocks にロードすることを指し、「ストリーム」または「ストリーミング」は、リアルタイムでデータを継続的にロードすることを指します。
ロード方法
Insert
ビジネスシナリオ:
- INSERT INTO VALUES: 少量のデータを内部テーブルに追加。
- INSERT INTO SELECT:
-
INSERT INTO SELECT FROM
<table_name>: 内部または外部テーブルでのクエリ結果をテーブルに追加。 -
INSERT INTO SELECT FROM FILES(): リモートストレージ内のデータファイルでのクエリ結果をテーブルに追加。
注記AWS S3 では、この機能は v3.1 以降でサポートされています。HDFS、Microsoft Azure Storage、Google GCS、および S3 互換ストレージ(MinIO など)では、この機能は v3.2 以降でサポートされています。
-
ファイル形式:
- INSERT INTO VALUES: SQL
- INSERT INTO SELECT:
- INSERT INTO SELECT FROM
<table_name>: StarRocks テーブル - INSERT INTO SELECT FROM FILES(): Parquet および ORC
- INSERT INTO SELECT FROM
データ量: 固定されていない(データ量はメモリサイズに基づいて変動します。)
Stream Load
ビジネスシナリオ: ローカルファイルシステムからのバッチデータロード。
ファイル形式: CSV および JSON
データ量: 10 GB 以下
Broker Load
ビジネスシナリオ:
- HDFS または AWS S3、Microsoft Azure Storage、Google GCS、S3 互換ストレージ(MinIO など)のクラウドストレージからのバッチデータロード。
- ローカルファイルシステムまたは NAS からのバッチデータロード。
ファイル形式: CSV、Parquet、ORC、および JSON(v3.2.3 以降でサポート)
データ量: 数十 GB から数百 GB
Pipe
ビジネスシナリオ: HDFS または AWS S3 からのバッチまたはストリームデータロード。
このロード方法は v3.2 以降でサポートされています。
ファイル形式: Parquet および ORC
データ量: 100 GB から 1 TB 以上
Routine Load
ビジネスシナリオ: Kafka からのストリームデータロード。
ファイル形式: CSV、JSON、および Avro(v3.0.1 以降でサポート)
データ量: MB から GB のデータをミニバッチとして
Spark Load
ビジネスシナリオ: Spark クラスターを使用して HDFS に保存された Apache Hive™ テーブルのバッチデータ�ロード。
ファイル形式: CSV、Parquet(v2.0 以降でサポート)、および ORC(v2.0 以降でサポート)
データ量: 数十 GB から TB
エコシステムツール
Kafka コネクタ
ビジネスシナリオ: Kafka からのストリームデータロード。
Spark コネクタ
ビジネスシナリオ: Spark からのバッチデータロード。
Flink コネクタ
ビジネスシナリオ: Flink からのストリームデータロード。
SMT
ビジネスシナリオ: Flink を通じて MySQL、PostgreSQL、SQL Server、Oracle、Hive、ClickHouse、TiDB などのデータソースからデータをロード。
DataX
ビジネスシナリオ: リレーショナルデータベース(例: MySQL、Oracle)、HDFS、Hive などのさまざまな異種データソース間でデータを同期。
CloudCanal
ビジネスシナリオ: ソースデータベース(例: MySQL、Oracle、PostgreSQL)から StarRocks へのデータ移行または同期。
Kettle Connector
ビジネスシナリオ: Kettle と統合。Kettle の強力なデータ処理および変換機能と StarRocks の高性能データストレージおよび分析能力を組み合わせることで、より柔軟で効率的なデータ処理ワークフローを実現。
API
Stream Load トランザクションインターフェース
ビジネスシナリオ: Flink や Kafka などの外部システムからデータをロードするために実行されるトランザクションに対して 2 フェーズコミット (2PC) を実装し、高度に並行したストリームロードのパフォーマンスを向上させます。この機能は v2.4 以降でサポートされています。
ファイル形式: CSV および JSON
データ量: 10 GB 以下
ロードオプションの選択
このセクションでは、一般的なデータソースに利用可能なロードオプションをリストし、あなたの状況に最適なオプションを選択するのに役立ちます。
オブジェクトストレージ
| データソース | 利用可能なロードオプション |
|---|---|
| AWS S3 |
|
| Microsoft Azure Storage |
|
| Google GCS |
|
| S3 互換ストレージ(MinIO など) |
|
ローカルファイルシステム(NAS を含む)
| データソース | 利用可能なロードオプション |
|---|---|
| ローカルファイルシステム(NAS を含む) |
|
HDFS
| データソース | 利用可能なロードオプション |
|---|---|
| HDFS |
|
Flink、Kafka、および Spark
| データソース | 利用可能なロードオプション |
|---|---|
| Apache Flink® | |
| Apache Kafka® |
ソースデータがマルチテーブルジョインや ETL 操作を必要とする場合、Flink を使用してデータを読み取り、事前処理を行い、その後 Flink コネクタ を使用してデータを StarRocks にロードできます。 |
| Apache Spark™ |
データレイク
| データソース | 利用可能なロードオプション |
|---|---|
| Apache Hive™ |
|
| Apache Iceberg | (バッチ) Iceberg catalog を作成し、その後 INSERT INTO SELECT FROM <table_name> を使用。 |
| Apache Hudi | (バッチ) Hudi catalog を作成し、その後 INSERT INTO SELECT FROM <table_name> を使用。 |
| Delta Lake | (バッチ) Delta Lake catalog を作成し、その後 INSERT INTO SELECT FROM <table_name> を使用。 |
| Elasticsearch | (バッチ) Elasticsearch catalog を作成し、その後 INSERT INTO SELECT FROM <table_name> を使用。 |
| Apache Paimon | (バッチ) Paimon catalog を作成し、その後 INSERT INTO SELECT FROM <table_name> を使用。 |
StarRocks は v3.2 以降、unified catalogs を提供しており、Hive、Iceberg、Hudi、Delta Lake のデータソースからのテーブルを統合データソースとして取り扱うことができます。
内部および外部データベース
| データソース | 利用可能なロードオプション |
|---|---|
| StarRocks | (バッチ) StarRocks external table を作成し、その後 INSERT INTO VALUES を使用して少量のデータレコードを挿入するか、INSERT INTO SELECT FROM <table_name> を使用してテーブルのデータを挿入。注意 StarRocks external tables はデータの書き込みのみをサポートし、データの読み取りはサポートしていません。 |
| MySQL |
|
| その他のデータベース(Oracle、PostgreSQL、SQL Server、ClickHouse、TiDB など) |
|
