データレイクハウス
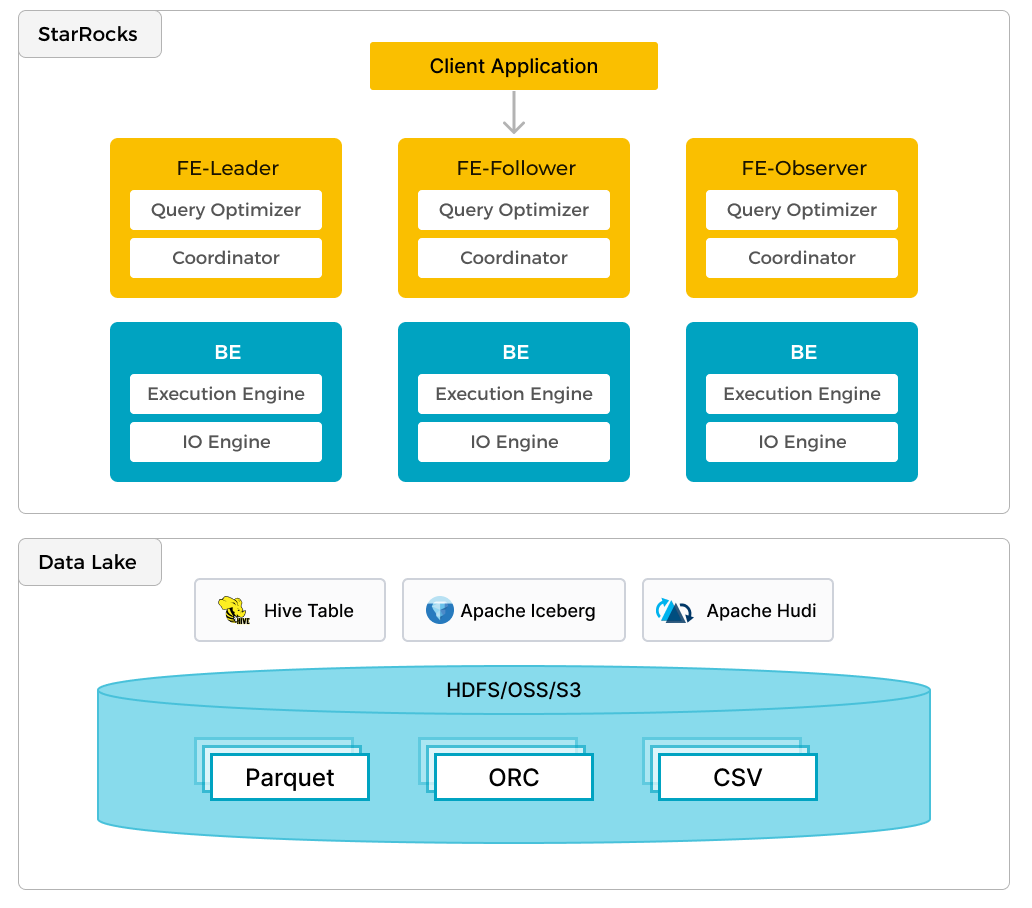
In addition to efficient analytics of local data, StarRocks can work as the compute engine to analyze data stored in data lakes such as Apache Hudi, Apache Iceberg, and Delta Lake. One of the key features of StarRocks is its external catalog, which acts as the linkage to an externally maintained metastore. This functionality provides users with the capability to query external data sources seamlessly, eliminating the need for data migration. As such, users can analyze data from different systems such as HDFS and Amazon S3, in various file formats such as Parquet, ORC, and CSV, etc.
The preceding figure shows a data lake analytics scenario where StarRocks is responsible for data computing and analysis, and the data lake is responsible for data storage, organization, and maintenance. Data lakes allow users to store data in open storage formats and use flexible schemas to produce reports on "single source of truth" for various BI, AI, ad-hoc, and reporting use cases. StarRocks fully leverages the advantages of its vectorization engine and CBO, significantly improving the performance of data lake analytics.
主要なアイデア
- オープンデータフォーマット: JSON、Parquet、Avro などの多様なデータタイプをサポートし、構造化データと非構造化データの両方の保存と処理を容易にします。
- メタデータ管理: Iceberg テーブルフォーマットのようなフォーマットを利用して、データを効率的に整理し管理する共有メタデータレイヤーを実装します。
- 多様なクエリエンジン: Presto や Spark の強化版など、さまざまな分析や AI のユースケースに対応する複数のエンジンを組み込みます。
- ガバナンスとセキュリティ: データのセキュリティ、プライバシー、コンプライアンスのための強力な組み込みメカニズムを備え、データの完全性と信頼性を確保します。
データレイクハウスアーキテクチャの利点
- 柔軟性とスケーラビリティ: 多様なデータタイプをシームレスに管理し、組織のニーズに応じてスケールします。
- コスト効率: 従来の方法と比較して、データの保存と処理のための経済的な代替手段を提供します。
- データガバナンスの強化: データの制御、管理、完全性を改善し、信頼性と安全性のあるデータ処理を保証します。
- AI と分析の準備: 機械学習や AI 駆動のデータ処理を含む複雑な分析タスクに最適です。
StarRocks のアプローチ
考慮すべき重要な点は次のとおりです:
- catalog またはメタデータサービスとの統合の標準化
- コンピュートノードの弾力的なスケーラビリティ
- 柔軟なキャッシングメカニズム
Catalogs
StarRocks には、内部と外部の 2 種類の catalogs があります。内部 catalog には、StarRocks データベース内に保存されているデータのメタデータが含まれています。外部 catalogs は、Hive、Iceberg、Delta Lake、Hudi によって管理されるデータを含む、外部に保存されているデータを操作するために使用されます。他にも多くの外部システムがあり、リンクはページ下部の「More Information」セクションにあります。
コンピュートノード (CN) のスケーリング
ストレージとコンピュートの分離により、スケーリングの複雑さが軽減されます。StarRocks のコンピュートノードはローカルキャッシュのみを保存しているため、ロードに応じてノードを追加または削除できます。
データキャッシュ
コンピュートノード上のキャッシュはオプションです。コンピュートノードが急速に変化するロードパターンに基づいて迅速にスピンアップおよびダウンしている場合、またはクエリが頻繁に最新のデータのみに対して行われる場合、データをキャッシュする意味がないかもしれません。
🗃️ Catalog
12項目
📄️ 外部テーブル
- v3.0以降、Hive、Iceberg、Hudiからデータをクエリするために、catalogを使用することを推奨します。詳細は Hive catalog、Iceberg catalog、Hudi catalog を参照してください。
📄️ ファイル外部テーブル
ファイル外部テーブルは、特別なタイプの外部テーブルです。データを StarRocks にロードすることなく、外部ストレージシステム内の Parquet および ORC データファイルを直接クエリできます。さらに、��ファイル外部テーブルはメタストアに依存しません。現在のバージョンでは、StarRocks は次の外部ストレージシステムをサポートしています: HDFS、Amazon S3、およびその他の S3 互換ストレージシステム。
📄️ Data Cache
このトピックでは、Data Cache の動作原理と、外部データのクエリパフォーマンスを向上させるために Data Cache を有効にする方法について説明します。
📄️ Data lake FAQ
このトピックでは、データレイクに関するよくある質問 (FAQ) を説明し、これらの問題に対する解決策を提供します。このトピックで言及されているいくつかのメトリクスは、SQL クエリのプロファイルからのみ取得できます。SQL クエリの��プロファイルを取得するには、set enable_profile=true を指定する必要があります。
📄️ Feature Support
バージョン v2.3 以降、StarRocks は外部カタログを介して外部データソースの管理とデータレイク内のデータ分析をサポートしています。
