ストレージとコンピュートの分離
ストレージとコンピュートを分離したシステムでは、データはAmazon S3、Google Cloud Storage、Azure Blob Storage、MinIOのような他のS3互換ストレージといった低コストで信頼性の高いリモートストレージシステムに保存されます。ホットデータはローカルにキャッシュされ、キャッシュがヒットすると、クエリパフォーマンスはストレージとコンピュートが結合されたアーキテクチャと同等になります。コンピュートノード (CN) は、数秒でオンデマンドで追加または削除できます。このアーキテクチャはストレージコストを削減し、リソースの分離を改善し、弾力性とスケーラビリティを提供します。
このチュートリアルでは以下をカバーします:
- DockerコンテナでのStarRocksの実行
- オブジェクトストレージとしてのMinIOの使用
- StarRocksの共有データ用の設定
- 2つの公開データセットのロード
- SELECTとJOINを使用したデータの分析
- 基本的なデータ変換 (ETLのT)
使用されるデータはNYC OpenDataとNOAAのNational Centers for Environmental Informationから提供されています。
これらのデータセットは非常に大きいため、このチュートリアルはStarRocksの操作に慣れることを目的としており、過去120年間のデータをロ�ードすることはありません。Dockerイメージを実行し、このデータをDockerに4 GBのRAMを割り当てたマシンでロードできます。より大規模でフォールトトレラントなスケーラブルなデプロイメントについては、他のドキュメントを用意しており、後で提供します。
このドキュメントには多くの情報が含まれており、ステップバイステップの内容が最初に、技術的な詳細が最後に提示されています。これは以下の目的を順に果たすためです:
- 読者が共有データデプロイメントでデータをロードし、そのデータを分析できるようにする。
- 共有データデプロイメントの設定詳細を提供する。
- ロード中のデータ変換の基本を説明する。
前提条件
Docker
- Docker
- Dockerに割り当てられた4 GBのRAM
- Dockerに割り当てられた10 GBの空きディスクスペース
SQLクライアント
Docker環境で提供されるSQLクライアントを使用するか、システム上のクライ��アントを使用できます。多くのMySQL互換クライアントが動作し、このガイドではDBeaverとMySQL WorkBenchの設定をカバーしています。
curl
curl はStarRocksへのデータロードジョブの発行とデータセットのダウンロードに使用されます。OSのプロンプトで curl または curl.exe を実行してインストールされているか確認してください。curlがインストールされていない場合は、こちらからcurlを入手してください。
用語
FE
フロントエンドノードはメタデータ管理、クライアント接続管理、クエリプランニング、クエリスケジューリングを担当します。各FEはメモリ内にメタデータの完全なコピーを保存および維持し、FEs間でのサービスの無差別性を保証します。
CN
コンピュートノードは、共有データデプロイメントでクエリプランを実行する役割を担っています。
BE
バックエンドノードは、共有なしデプロイメントでデータストレージとクエリプランの実行の両方を担当します。
このガイドではBEsを使用しませんが、BEsとCNsの違いを理解するためにこの情報を含めています。
StarRocksの起動
オブジェクトストレージを使用して共有データでStarRocksを実行するには、以下が必要です:
- フロントエンドエンジン (FE)
- コンピュートノード (CN)
- オブジェクトストレージ
このガイドでは、GNU Affero General Public Licenseの下で提供されるS3互換のオブジェクトストレージであるMinIOを使用します。
3つの必要なコンテナを提供する環境を用意するために、StarRocksはDocker composeフ�ァイルを提供します。
mkdir quickstart
cd quickstart
curl -O https://raw.githubusercontent.com/StarRocks/demo/master/documentation-samples/quickstart/docker-compose.yml
docker compose up -d
サービスの進行状況を確認します。FEとCNが正常になるまで約30秒かかります。MinIOコンテナは健康状態のインジケータを表示しませんが、MinIOのWeb UIを使用してその健康状態を確認します。
FEとCNが healthy のステータスを�示すまで docker compose ps を実行します:
docker compose ps
SERVICE CREATED STATUS PORTS
starrocks-cn 25 seconds ago Up 24 seconds (healthy) 0.0.0.0:8040->8040/tcp
starrocks-fe 25 seconds ago Up 24 seconds (healthy) 0.0.0.0:8030->8030/tcp, 0.0.0.0:9020->9020/tcp, 0.0.0.0:9030->9030/tcp
minio 25 seconds ago Up 24 seconds 0.0.0.0:9000-9001->9000-9001/tcp
MinIOのクレデンシャルを生成する
StarRocksでMinIOをオブジェクトストレージとして使用するには、アクセスキーを生成する必要があります。
MinIO Web UIを開く
http://localhost:9001/access-keys にアクセスします。ユーザー名とパスワードはDocker composeファイルで指定されており、minioadmin と minioadmin です。まだアクセスキーがないことが確認できます。Create access key + をクリックします。
MinIOがキーを生成します。Create をクリックしてキーをダウンロードします。
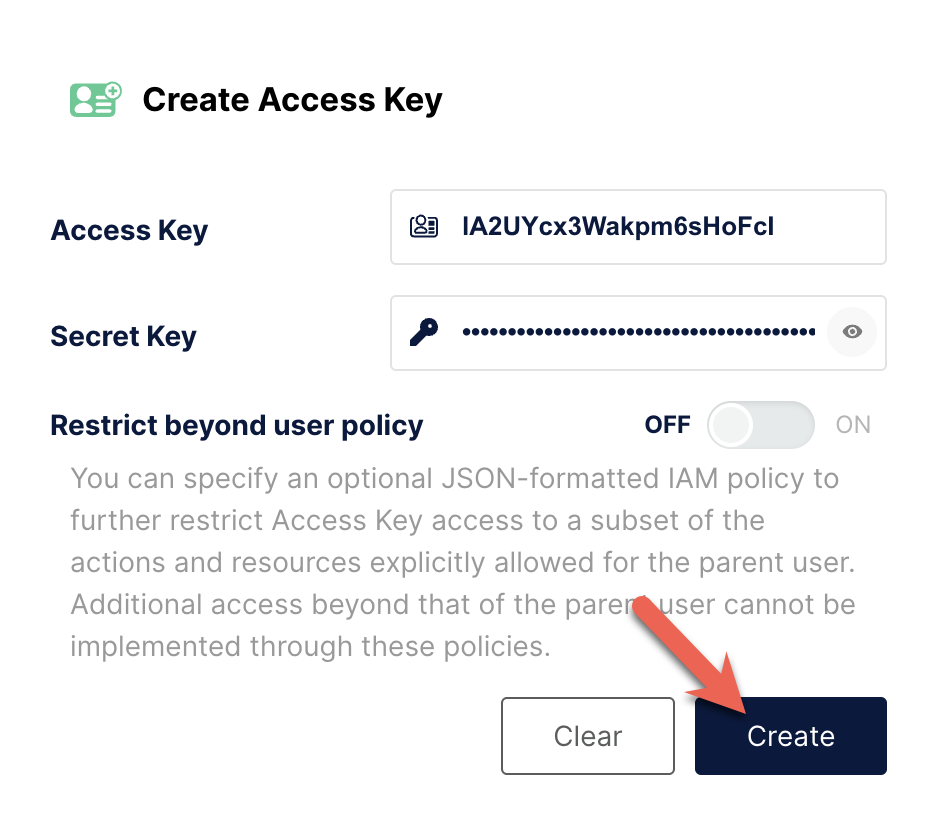
アクセスキーは Create をクリックするまで保存されません。キーをコピーしてページから離れないでください。
SQLクライアント
これらの3つのクライアントはこのチュートリアルでテストされていますが、1つだけ使用すれば大丈夫です。
- mysql CLI: Docker環境またはあなたのマシンから実行できます。
- DBeaver はコミュニティ版とPro版があります。
- MySQL Workbench
クライアントの設定
- mysql CLI
- DBeaver
- MySQL Workbench
mysql CLIを使用する最も簡単な方法は、StarRocksコンテナ starrocks-fe から実行することです。
docker compose exec starrocks-fe \
mysql -P 9030 -h 127.0.0.1 -u root --prompt="StarRocks > "
すべての docker compose コマンドは、docker-compose.yml ファイルを含むディレクトリから実行する必要があります。
mysql CLIをインストールしたい場合は、以下の mysql client install を展開してください。
mysql client install
- macOS: Homebrewを使用していて、MySQL Serverが不要な場合は、
brew install mysqlを実行してCLIをインストールします。 - Linux:
mysqlクライアントのためにリポジトリシステムを確認してください。例えば、yum install mariadb。 - Microsoft Windows: MySQL Community Server をインストールし、提供されたクライアントを実行するか、WSLから
mysqlを実行します。
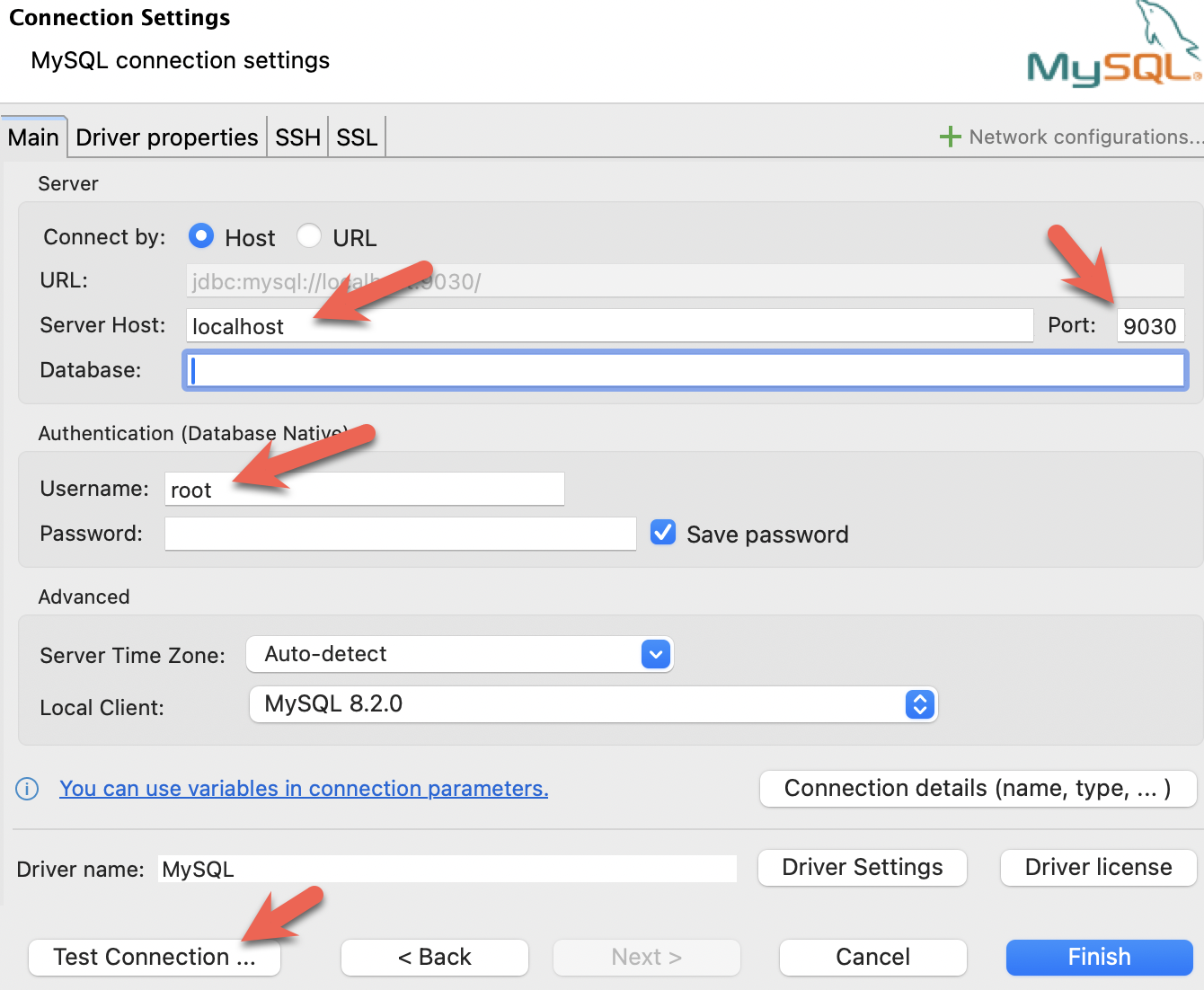
- DBeaver をインストールし、接続を追加します。

- ポート、IP、ユーザー名を設定します。接続をテストし、テストが成功したらFinishをクリックします。
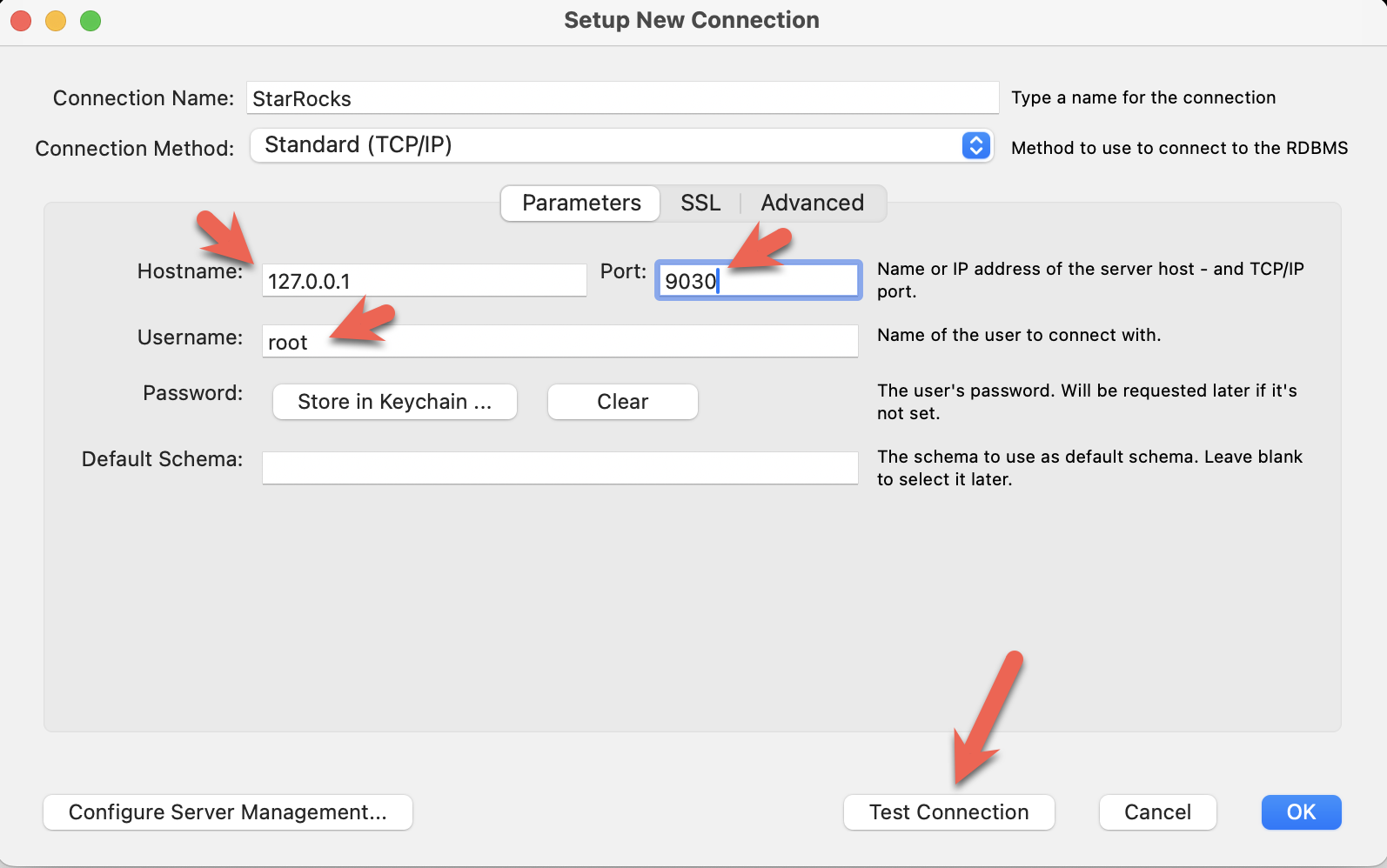
- MySQL Workbench をインストールし、接続を追加します。
- ポート、IP、ユーザー名を設定し、接続をテストします。
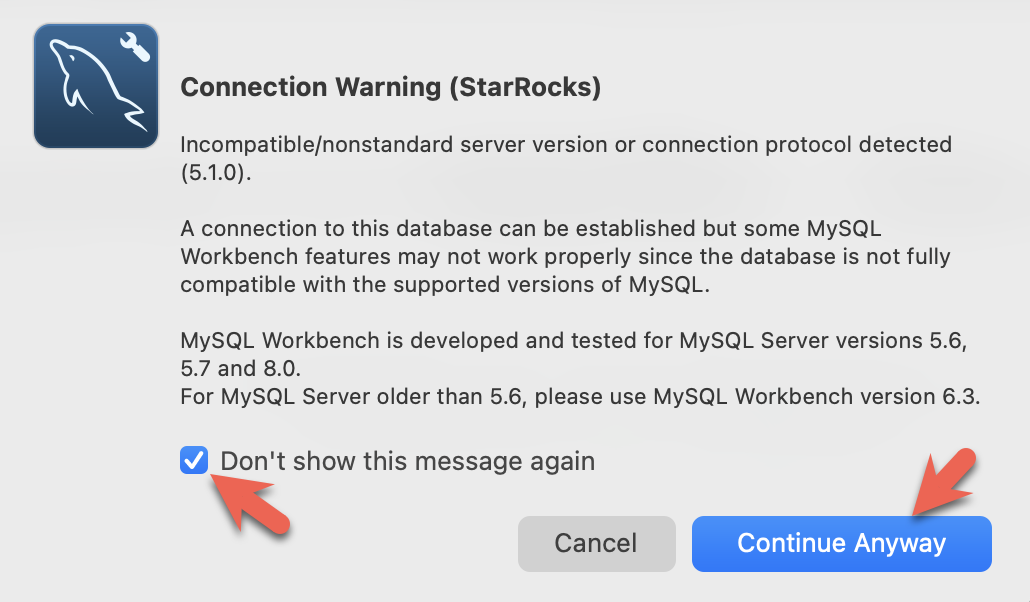
- Workbenchは特定のMySQLバージョンをチェックするため、警告が表示されます。警告を無視し、プロンプトが表示されたら、Workbenchが警告を表示しないように設定できます。
データのダウンロード
これらの2つのデータセットをFEコンテナにダウンロードします。
FEコンテナでシェルを開く
シェルを開き、ダウンロードしたファイル用のディレクトリを作成します:
docker compose exec starrocks-fe bash
mkdir quickstart
cd quickstart
ニューヨーク市のクラッシュデータ
curl -O https://raw.githubusercontent.com/StarRocks/demo/master/documentation-samples/quickstart/datasets/NYPD_Crash_Data.csv
天気データ
curl -O https://raw.githubusercontent.com/StarRocks/demo/master/documentation-samples/quickstart/datasets/72505394728.csv
StarRocksの共有データ用設定
この時点でStarRocksが実行されており、MinIOも実行されています。MinIOアクセスキーはStarRocksとMinIOを接続するために使用されます。
SQLクライアントでStarRocksに接続する
docker-compose.yml ファイルを含むディレクトリからこのコマンドを実行します。
mysql CLI以外のクライアントを使用している場合は、今それを開いてください。
docker compose exec starrocks-fe \
mysql -P9030 -h127.0.0.1 -uroot --prompt="StarRocks > "
ストレージボリュームを作成する
以下の設定の詳細:
- MinIOサーバーはURL
http://minio:9000で利用可能 - 上記で作成されたバケットは
starrocksという名前 - このボリュームに書き込まれたデータは、バケット
starrocks内のsharedというフォルダに保存されます
フォルダ shared は、データがボリュームに初めて書き込まれたときに作成されます
- MinIOサーバーはSSLを使用していません
- MinIOキーとシークレットは
aws.s3.access_keyとaws.s3.secret_keyとして入力されます。以前にMinIO Web UIで作成したアクセスキーを使用します。 - ボリューム
sharedはデフォルトのボリュームです
コマンドを実行する前に編集し、MinIOで作成したアクセスキーとシークレットに置き換えてください。
CREATE STORAGE VOLUME shared
TYPE = S3
LOCATIONS = ("s3://starrocks/shared/")
PROPERTIES
(
"enabled" = "true",
"aws.s3.endpoint" = "http://minio:9000",
"aws.s3.use_aws_sdk_default_behavior" = "false",
"aws.s3.enable_ssl" = "false",
"aws.s3.use_instance_profile" = "false",
"aws.s3.access_key" = "IA2UYcx3Wakpm6sHoFcl",
"aws.s3.secret_key" = "E33cdRM9MfWpP2FiRpc056Zclg6CntXWa3WPBNMy"
);
SET shared AS DEFAULT STORAGE VOLUME;
DESC STORAGE VOLUME shared\G
このドキュメントの一部のSQLやStarRocksドキュメントの多くのドキュメントでは、セミコロンの代わりに \G を使用しています。\G はmysql CLIにクエリ結果を縦に表示させます。
多くのSQLクライアントは縦書きのフォーマット出力を解釈しないため、\G を ; に置き換える必要があります。
*************************** 1. row ***************************
Name: shared
Type: S3
IsDefault: true
Location: s3://starrocks/shared/
Params: {"aws.s3.access_key":"******","aws.s3.secret_key":"******","aws.s3.endpoint":"http://minio:9000","aws.s3.region":"us-east-1","aws.s3.use_instance_profile":"false","aws.s3.use_aws_sdk_default_behavior":"false"}
Enabled: true
Comment:
1 row in set (0.03 sec)
フォルダ shared は、データがバケットに書き込まれるまでMinIOオブジェクトリストに表示されません。
テーブルを作成する
データベースの作成
StarRocks > プロンプトで次の2行を入力し、それぞれの後にエンターキーを押します。
CREATE DATABASE IF NOT EXISTS quickstart;
USE quickstart;
2つのテーブルを作成
Crashdata
クラッシュデータセットにはこれより多くのフィールドが含まれていますが、スキーマは天候が運転条件に与える影響に関する質問に役立つ可能性のあるフィールドのみを含むように縮小されています。
CREATE TABLE IF NOT EXISTS crashdata (
CRASH_DATE DATETIME,
BOROUGH STRING,
ZIP_CODE STRING,
LATITUDE INT,
LONGITUDE INT,
LOCATION STRING,
ON_STREET_NAME STRING,
CROSS_STREET_NAME STRING,
OFF_STREET_NAME STRING,
CONTRIBUTING_FACTOR_VEHICLE_1 STRING,
CONTRIBUTING_FACTOR_VEHICLE_2 STRING,
COLLISION_ID INT,
VEHICLE_TYPE_CODE_1 STRING,
VEHICLE_TYPE_CODE_2 STRING
);
Weatherdata
クラッシュデータと同様に、天候データセットにはさらに多くの列(合計125列)があり、質問に答えると予想されるものだけがデータベースに含まれています。
CREATE TABLE IF NOT EXISTS weatherdata (
DATE DATETIME,
NAME STRING,
HourlyDewPointTemperature STRING,
HourlyDryBulbTemperature STRING,
HourlyPrecipitation STRING,
HourlyPresentWeatherType STRING,
HourlyPressureChange STRING,
HourlyPressureTendency STRING,
HourlyRelativeHumidity STRING,
HourlySkyConditions STRING,
HourlyVisibility STRING,
HourlyWetBulbTemperature STRING,
HourlyWindDirection STRING,
HourlyWindGustSpeed STRING,
HourlyWindSpeed STRING
);
2つのデータセットをロードする
StarRocksにデータをロードする方法はたくさんあります。このチュートリアルでは、最も簡単な方法としてcurlとStarRocks Stream Loadを使用します。
これらのcurlコマンドは、データセットをダウンロードしたディレクトリのFEシェルから実行します。
パスワードを求められます。MySQLの root ユーザーにパスワードを割り当てていない場合は、Enterキーを押してください。
curl コマンドは複雑に見えますが、チュートリアルの最後で詳細に説明されています。今は、コマンドを実行してデータを分析するためのSQLを実行し、その後にデータロードの詳細を読むことをお勧めします。
ニューヨーク市の衝突データ - クラッシュ
curl --location-trusted -u root \
-T ./NYPD_Crash_Data.csv \
-H "label:crashdata-0" \
-H "column_separator:," \
-H "skip_header:1" \
-H "enclose:\"" \
-H "max_filter_ratio:1" \
-H "columns:tmp_CRASH_DATE, tmp_CRASH_TIME, CRASH_DATE=str_to_date(concat_ws(' ', tmp_CRASH_DATE, tmp_CRASH_TIME), '%m/%d/%Y %H:%i'),BOROUGH,ZIP_CODE,LATITUDE,LONGITUDE,LOCATION,ON_STREET_NAME,CROSS_STREET_NAME,OFF_STREET_NAME,NUMBER_OF_PERSONS_INJURED,NUMBER_OF_PERSONS_KILLED,NUMBER_OF_PEDESTRIANS_INJURED,NUMBER_OF_PEDESTRIANS_KILLED,NUMBER_OF_CYCLIST_INJURED,NUMBER_OF_CYCLIST_KILLED,NUMBER_OF_MOTORIST_INJURED,NUMBER_OF_MOTORIST_KILLED,CONTRIBUTING_FACTOR_VEHICLE_1,CONTRIBUTING_FACTOR_VEHICLE_2,CONTRIBUTING_FACTOR_VEHICLE_3,CONTRIBUTING_FACTOR_VEHICLE_4,CONTRIBUTING_FACTOR_VEHICLE_5,COLLISION_ID,VEHICLE_TYPE_CODE_1,VEHICLE_TYPE_CODE_2,VEHICLE_TYPE_CODE_3,VEHICLE_TYPE_CODE_4,VEHICLE_TYPE_CODE_5" \
-XPUT http://localhost:8030/api/quickstart/crashdata/_stream_load
上記のコマンドの出力です。最初のハイライトされたセクションは、期待される出力 (OKと1行を除くすべての行が挿入されたこと) を示しています。1行は正しい列数を含んでいないためフィルタリングされました。
Enter host password for user 'root':
{
"TxnId": 2,
"Label": "crashdata-0",
"Status": "Success",
"Message": "OK",
"NumberTotalRows": 423726,
"NumberLoadedRows": 423725,
"NumberFilteredRows": 1,
"NumberUnselectedRows": 0,
"LoadBytes": 96227746,
"LoadTimeMs": 1013,
"BeginTxnTimeMs": 21,
"StreamLoadPlanTimeMs": 63,
"ReadDataTimeMs": 563,
"WriteDataTimeMs": 870,
"CommitAndPublishTimeMs": 57,
"ErrorURL": "http://10.5.0.3:8040/api/_load_error_log?file=error_log_da41dd88276a7bfc_739087c94262ae9f"
}%
エラーが発生した場合、出力にはエラーメッセージを確認するためのURLが提供されます。コンテナにはプライベートIPアドレスがあるため、コンテナからcurlを実行して表示する必要があります。
curl http://10.5.0.3:8040/api/_load_error_log<details from ErrorURL>
このチュートリアルの開発中に見られた内容を展開して表示します:
ブラウザでエラーメッセージを読む
Error: Value count does not match column count. Expect 29, but got 32.
Column delimiter: 44,Row delimiter: 10.. Row: 09/06/2015,14:15,,,40.6722269,-74.0110059,"(40.6722269, -74.0110059)",,,"R/O 1 BEARD ST. ( IKEA'S
09/14/2015,5:30,BRONX,10473,40.814551,-73.8490955,"(40.814551, -73.8490955)",TORRY AVENUE ,NORTON AVENUE ,,0,0,0,0,0,0,0,0,Driver Inattention/Distraction,Unspecified,,,,3297457,PASSENGER VEHICLE,PASSENGER VEHICLE,,,
天気データ
クラッシュデータをロードしたのと同様に、天気データセットをロードします。
curl --location-trusted -u root \
-T ./72505394728.csv \
-H "label:weather-0" \
-H "column_separator:," \
-H "skip_header:1" \
-H "enclose:\"" \
-H "max_filter_ratio:1" \
-H "columns: STATION, DATE, LATITUDE, LONGITUDE, ELEVATION, NAME, REPORT_TYPE, SOURCE, HourlyAltimeterSetting, HourlyDewPointTemperature, HourlyDryBulbTemperature, HourlyPrecipitation, HourlyPresentWeatherType, HourlyPressureChange, HourlyPressureTendency, HourlyRelativeHumidity, HourlySkyConditions, HourlySeaLevelPressure, HourlyStationPressure, HourlyVisibility, HourlyWetBulbTemperature, HourlyWindDirection, HourlyWindGustSpeed, HourlyWindSpeed, Sunrise, Sunset, DailyAverageDewPointTemperature, DailyAverageDryBulbTemperature, DailyAverageRelativeHumidity, DailyAverageSeaLevelPressure, DailyAverageStationPressure, DailyAverageWetBulbTemperature, DailyAverageWindSpeed, DailyCoolingDegreeDays, DailyDepartureFromNormalAverageTemperature, DailyHeatingDegreeDays, DailyMaximumDryBulbTemperature, DailyMinimumDryBulbTemperature, DailyPeakWindDirection, DailyPeakWindSpeed, DailyPrecipitation, DailySnowDepth, DailySnowfall, DailySustainedWindDirection, DailySustainedWindSpeed, DailyWeather, MonthlyAverageRH, MonthlyDaysWithGT001Precip, MonthlyDaysWithGT010Precip, MonthlyDaysWithGT32Temp, MonthlyDaysWithGT90Temp, MonthlyDaysWithLT0Temp, MonthlyDaysWithLT32Temp, MonthlyDepartureFromNormalAverageTemperature, MonthlyDepartureFromNormalCoolingDegreeDays, MonthlyDepartureFromNormalHeatingDegreeDays, MonthlyDepartureFromNormalMaximumTemperature, MonthlyDepartureFromNormalMinimumTemperature, MonthlyDepartureFromNormalPrecipitation, MonthlyDewpointTemperature, MonthlyGreatestPrecip, MonthlyGreatestPrecipDate, MonthlyGreatestSnowDepth, MonthlyGreatestSnowDepthDate, MonthlyGreatestSnowfall, MonthlyGreatestSnowfallDate, MonthlyMaxSeaLevelPressureValue, MonthlyMaxSeaLevelPressureValueDate, MonthlyMaxSeaLevelPressureValueTime, MonthlyMaximumTemperature, MonthlyMeanTemperature, MonthlyMinSeaLevelPressureValue, MonthlyMinSeaLevelPressureValueDate, MonthlyMinSeaLevelPressureValueTime, MonthlyMinimumTemperature, MonthlySeaLevelPressure, MonthlyStationPressure, MonthlyTotalLiquidPrecipitation, MonthlyTotalSnowfall, MonthlyWetBulb, AWND, CDSD, CLDD, DSNW, HDSD, HTDD, NormalsCoolingDegreeDay, NormalsHeatingDegreeDay, ShortDurationEndDate005, ShortDurationEndDate010, ShortDurationEndDate015, ShortDurationEndDate020, ShortDurationEndDate030, ShortDurationEndDate045, ShortDurationEndDate060, ShortDurationEndDate080, ShortDurationEndDate100, ShortDurationEndDate120, ShortDurationEndDate150, ShortDurationEndDate180, ShortDurationPrecipitationValue005, ShortDurationPrecipitationValue010, ShortDurationPrecipitationValue015, ShortDurationPrecipitationValue020, ShortDurationPrecipitationValue030, ShortDurationPrecipitationValue045, ShortDurationPrecipitationValue060, ShortDurationPrecipitationValue080, ShortDurationPrecipitationValue100, ShortDurationPrecipitationValue120, ShortDurationPrecipitationValue150, ShortDurationPrecipitationValue180, REM, BackupDirection, BackupDistance, BackupDistanceUnit, BackupElements, BackupElevation, BackupEquipment, BackupLatitude, BackupLongitude, BackupName, WindEquipmentChangeDate" \
-XPUT http://localhost:8030/api/quickstart/weatherdata/_stream_load
MinIOにデータが保存されていることを確認する
MinIO http://localhost:9001/browser/starrocks/ を開き、starrocks/shared/ の各ディレクトリに data、metadata、schema エントリがあることを確認します。
starrocks/shared/ �以下のフォルダ名は、データをロードするときに生成されます。shared の下に1つのディレクトリが表示され、その下にさらに2つのディレクトリが表示されるはずです。それぞれのディレクトリ内にデータ、メタデータ、スキーマエントリがあります。
質問に答える
これらのクエリは、あなたのSQLクライアントで実行できます。
NYCで1時間あたりの事故件数はどれくらいですか?
SELECT COUNT(*),
date_trunc("hour", crashdata.CRASH_DATE) AS Time
FROM crashdata
GROUP BY Time
ORDER BY Time ASC
LIMIT 200;
以下は出力の一部です。1月6日と7日に注目していますが、これは祝日ではない週の月曜日と火曜日です。元旦を見ることは、ラッシュアワーの通常の朝を示すものではないかもしれません。
| 14 | 2014-01-06 06:00:00 |
| 16 | 2014-01-06 07:00:00 |
| 43 | 2014-01-06 08:00:00 |
| 44 | 2014-01-06 09:00:00 |
| 21 | 2014-01-06 10:00:00 |
| 28 | 2014-01-06 11:00:00 |
| 34 | 2014-01-06 12:00:00 |
| 31 | 2014-01-06 13:00:00 |
| 35 | 2014-01-06 14:00:00 |
| 36 | 2014-01-06 15:00:00 |
| 33 | 2014-01-06 16:00:00 |
| 40 | 2014-01-06 17:00:00 |
| 35 | 2014-01-06 18:00:00 |
| 23 | 2014-01-06 19:00:00 |
| 16 | 2014-01-06 20:00:00 |
| 12 | 2014-01-06 21:00:00 |
| 17 | 2014-01-06 22:00:00 |
| 14 | 2014-01-06 23:00:00 |
| 10 | 2014-01-07 00:00:00 |
| 4 | 2014-01-07 01:00:00 |
| 1 | 2014-01-07 02:00:00 |
| 3 | 2014-01-07 03:00:00 |
| 2 | 2014-01-07 04:00:00 |
| 6 | 2014-01-07 06:00:00 |
| 16 | 2014-01-07 07:00:00 |
| 41 | 2014-01-07 08:00:00 |
| 37 | 2014-01-07 09:00:00 |
| 33 | 2014-01-07 10:00:00 |
月曜日または火曜日の朝のラッシュアワーでは約40件の事故が発生しているようで、17時頃も同様です。
NYCの平均気温はどれくらいですか?
SELECT avg(HourlyDryBulbTemperature),
date_trunc("hour", weatherdata.DATE) AS Time
FROM weatherdata
GROUP BY Time
ORDER BY Time ASC
LIMIT 100;
出力:
これは2014年のデータであり、最近のNYCはこれほど寒くありません。
+-------------------------------+---------------------+
| avg(HourlyDryBulbTemperature) | Time |
+-------------------------------+---------------------+
| 25 | 2014-01-01 00:00:00 |
| 25 | 2014-01-01 01:00:00 |
| 24 | 2014-01-01 02:00:00 |
| 24 | 2014-01-01 03:00:00 |
| 24 | 2014-01-01 04:00:00 |
| 24 | 2014-01-01 05:00:00 |
| 25 | 2014-01-01 06:00:00 |
| 26 | 2014-01-01 07:00:00 |
視界が悪いときにNYCで運転するのは安全ですか?
視界が悪いとき(0から1.0マイルの間)の事故件数を見てみましょう。この質問に答えるために、2つのテーブルをDATETIME列でジョインします。
SELECT COUNT(DISTINCT c.COLLISION_ID) AS Crashes,
truncate(avg(w.HourlyDryBulbTemperature), 1) AS Temp_F,
truncate(avg(w.HourlyVisibility), 2) AS Visibility,
max(w.HourlyPrecipitation) AS Precipitation,
date_format((date_trunc("hour", c.CRASH_DATE)), '%d %b %Y %H:%i') AS Hour
FROM crashdata c
LEFT JOIN weatherdata w
ON date_trunc("hour", c.CRASH_DATE)=date_trunc("hour", w.DATE)
WHERE w.HourlyVisibility BETWEEN 0.0 AND 1.0
GROUP BY Hour
ORDER BY Crashes DESC
LIMIT 100;
低視界時に1時間で最も多くの事故が発生したのは129件です。考慮すべき点はいくつかあります:
- 2014年2月3日は月曜日でした
- 午前8時はラッシュアワーです
- 雨が降っていました(その時間の降水量は0.12インチ)
- 気温は32度F(水の氷点)
- 視界は0.25マイルで、NYCの通常は10マイルです
+---------+--------+------------+---------------+-------------------+
| Crashes | Temp_F | Visibility | Precipitation | Hour |
+---------+--------+------------+---------------+-------------------+
| 129 | 32 | 0.25 | 0.12 | 03 Feb 2014 08:00 |
| 114 | 32 | 0.25 | 0.12 | 03 Feb 2014 09:00 |
| 104 | 23 | 0.33 | 0.03 | 09 Jan 2015 08:00 |
| 96 | 26.3 | 0.33 | 0.07 | 01 Mar 2015 14:00 |
| 95 | 26 | 0.37 | 0.12 | 01 Mar 2015 15:00 |
| 93 | 35 | 0.75 | 0.09 | 18 Jan 2015 09:00 |
| 92 | 31 | 0.25 | 0.12 | 03 Feb 2014 10:00 |
| 87 | 26.8 | 0.5 | 0.09 | 01 Mar 2015 16:00 |
| 85 | 55 | 0.75 | 0.20 | 23 Dec 2015 17:00 |
| 85 | 20 | 0.62 | 0.01 | 06 Jan 2015 11:00 |
| 83 | 19.6 | 0.41 | 0.04 | 05 Mar 2015 13:00 |
| 80 | 20 | 0.37 | 0.02 | 06 Jan 2015 10:00 |
| 76 | 26.5 | 0.25 | 0.06 | 05 Mar 2015 09:00 |
| 71 | 26 | 0.25 | 0.09 | 05 Mar 2015 10:00 |
| 71 | 24.2 | 0.25 | 0.04 | 05 Mar 2015 11:00 |
氷点下の条件での運転はどうですか?
水蒸気は40度Fで氷に昇華することがあります。このクエリは0から40度Fの間の気温を調べます。
SELECT COUNT(DISTINCT c.COLLISION_ID) AS Crashes,
truncate(avg(w.HourlyDryBulbTemperature), 1) AS Temp_F,
truncate(avg(w.HourlyVisibility), 2) AS Visibility,
max(w.HourlyPrecipitation) AS Precipitation,
date_format((date_trunc("hour", c.CRASH_DATE)), '%d %b %Y %H:%i') AS Hour
FROM crashdata c
LEFT JOIN weatherdata w
ON date_trunc("hour", c.CRASH_DATE)=date_trunc("hour", w.DATE)
WHERE w.HourlyDryBulbTemperature BETWEEN 0.0 AND 40.5
GROUP BY Hour
ORDER BY Crashes DESC
LIMIT 100;
凍結温度での結果は少し驚きました。寒い1月の日曜日の朝に市内であまり交通がないと思っていました。weather.com を見ると、その日は大きな嵐があり、多くの事故が発生したことがデータからもわかります。
+---------+--------+------------+---------------+-------------------+
| Crashes | Temp_F | Visibility | Precipitation | Hour |
+---------+--------+------------+---------------+-------------------+
| 192 | 34 | 1.5 | 0.09 | 18 Jan 2015 08:00 |
| 170 | 21 | NULL | | 21 Jan 2014 10:00 |
| 145 | 19 | NULL | | 21 Jan 2014 11:00 |
| 138 | 33.5 | 5 | 0.02 | 18 Jan 2015 07:00 |
| 137 | 21 | NULL | | 21 Jan 2014 09:00 |
| 129 | 32 | 0.25 | 0.12 | 03 Feb 2014 08:00 |
| 114 | 32 | 0.25 | 0.12 | 03 Feb 2014 09:00 |
| 104 | 23 | 0.7 | 0.04 | 09 Jan 2015 08:00 |
| 98 | 16 | 8 | 0.00 | 06 Mar 2015 08:00 |
| 96 | 26.3 | 0.33 | 0.07 | 01 Mar 2015 14:00 |
安全運転を心がけましょう!
共有データ用のStarRocks設定
StarRocksを共有データで使用する経験をした今、その設定を理解することが重要です。
CN設定
ここで使用されるCN設定はデフォルトです。CNは共有データ使用のために設計されています。デフォルトの設定は以下の通りです。変更を加える必要はありません。
sys_log_level = INFO
be_port = 9060
be_http_port = 8040
heartbeat_service_port = 9050
brpc_port = 8060
FE設定
FE設定はデフォルトとは少し異なります。FEはデータがBEノードのローカルディスクではなくオブジェクトストレージに保存されることを期待するように設定する必要があります。
docker-compose.yml ファイルは command でFE設定を生成します。
command: >
bash -c "echo run_mode=shared_data >> /opt/starrocks/fe/conf/fe.conf &&
echo cloud_native_meta_port=6090 >> /opt/starrocks/fe/conf/fe.conf &&
echo aws_s3_path=starrocks >> /opt/starrocks/fe/conf/fe.conf &&
echo aws_s3_endpoint=minio:9000 >> /opt/starrocks/fe/conf/fe.conf &&
echo aws_s3_use_instance_profile=false >> /opt/starrocks/fe/conf/fe.conf &&
echo cloud_native_storage_type=S3 >> /opt/starrocks/fe/conf/fe.conf &&
echo aws_s3_use_aws_sdk_default_behavior=false >> /opt/starrocks/fe/conf/fe.conf &&
sh /opt/starrocks/fe/bin/start_fe.sh"
これにより、この設定ファイルが生成されます:
LOG_DIR = ${STARROCKS_HOME}/log
DATE = "$(date +%Y%m%d-%H%M%S)"
JAVA_OPTS="-Dlog4j2.formatMsgNoLookups=true -Xmx8192m -XX:+UseMembar -XX:SurvivorRatio=8 -XX:MaxTenuringThreshold=7 -XX:+PrintGCDateStamps -XX:+PrintGCDetails -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+CMSClassUnloadingEnabled -XX:-CMSParallelRemarkEnabled -XX:CMSInitiatingOccupancyFraction=80 -XX:SoftRefLRUPolicyMSPerMB=0 -Xloggc:${LOG_DIR}/fe.gc.log.$DATE -XX:+PrintConcurrentLocks"
JAVA_OPTS_FOR_JDK_11="-Dlog4j2.formatMsgNoLookups=true -Xmx8192m -XX:+UseG1GC -Xlog:gc*:${LOG_DIR}/fe.gc.log.$DATE:time"
sys_log_level = INFO
http_port = 8030
rpc_port = 9020
query_port = 9030
edit_log_port = 9010
mysql_service_nio_enabled = true
run_mode=shared_data
aws_s3_path=starrocks
aws_s3_endpoint=minio:9000
aws_s3_use_instance_profile=false
cloud_native_storage_type=S3
aws_s3_use_aws_sdk_default_behavior=false
この設定ファイルにはデフォルトのエントリと共有データ用の追加が含まれています。共有データ用のエントリはハイライトされています。
デフォルトではないFE設定:
多くの設定パラメータは s3_ というプレフィックスが付いています。このプレフィックスはすべてのAmazon S3互換ストレージタイプ(例:S3、GCS、MinIO)に使用されます。Azure Blob Storageを使用する場合、プレフィックスは azure_ です。
run_mode=shared_data
これにより共有データの使用が有効になります。
aws_s3_path=starrocks
バケット名です。
aws_s3_endpoint=minio:9000
ポート番号を含むMinIOエンドポイントです。
aws_s3_use_instance_profile=false
MinIOを使用する場合、アクセスキーが使用されるため、MinIOではインスタンスプロファイルは使用されません。
cloud_native_storage_type=S3
S3互換ストレージまたはAzure Blob Storageのどちらを使用するかを指定します。MinIOの場合、常にS3です。
aws_s3_use_aws_sdk_default_behavior=false
MinIOを使用する場合、このパラメータは常にfalseに設定されます。
まとめ
このチュートリアルでは:
- DockerでStarRocksとMinioをデプロイしました
- MinIOアクセスキーを作成しました
- MinIOを使用するStarRocksストレージボリュームを設定しました
- ニューヨーク市が提供するクラッシュデータとNOAA��が提供する天気データをロードしました
- SQL JOINを使用して、視界が悪い状態や凍結した道路での運転が悪いアイデアであることを分析しました
学ぶべきことはまだあります。Stream Load中に行われたデータ変換については意図的に詳しく触れていません。curlコマンドに関するメモにその詳細があります。
curlコマンドに関するメモ
StarRocks Stream Load と curl は多くの引数を取ります。このチュートリアルで使用されるものだけがここで説明されており、残りは詳細情報セクションでリンクされます。
--location-trusted
これは、リダイレクトされた URL に資格情報を渡すように curl を設定します。
-u root
StarRocks にログインするために使用されるユーザー名です。
-T filename
T は転送を意味し、転送するファイル名です。
label:name-num
この Stream Load ジョブに関連付けるラベルです。ラベルは一意である必要があるため、ジョブを複数回実行する場合は、番号を追加してそれを増やし続けることができます。
column_separator:,
ファイルが単一の , を使用している場合は、上記のように設定します。異なる区切り文字を使用している場合は、ここでその区切り文字を設定します。一般的な選択肢は \t、,、および | です。
skip_header:1
一部の CSV ファイルには、すべての列名がリストされた単一のヘッダー行があり、データ型を含む2行目を追加するものもあります。ヘッダー行が1つまたは2つある場合は skip_header を 1 または 2 に設定し、ない場合は 0 に設定します。
enclose:\"
埋め込まれたカンマを含む文字列をダブルクォートで囲むことが一般的です。このチュートリアルで使用されるサンプルデータセットにはカンマを含む地理的位置があるため、enclose 設定は \" に設定されています。" を \ でエスケープすることを忘れないでください。
max_filter_ratio:1
これはデータ内のいくつかのエラーを許可します。理想的にはこれを 0 に設定し、エラーがある場合はジョブが失敗するようにします。デバッグ中にすべての行が失敗することを許可するために 1 に設定されています。
columns:
CSV ファイルの列を StarRocks テーブルの列にマッピングします。CSV ファイルにはテーブルの列よりも多くの列があることに気付くでしょう。テーブルに含まれていない列はスキップされます。
また、クラッシュデータセットの columns: 行にデータの変換が含まれていることにも気付くでしょう。CSV ファイルには標準に準拠していない日付や時刻が含まれていることが非常に一般的です。これは、クラッシュの日時を DATETIME 型に変換するためのロジックです。
columns 行
これは1つの��データレコードの始まりです。日付は MM/DD/YYYY 形式で、時刻は HH:MI です。DATETIME は一般的に YYYY-MM-DD HH:MI:SS であるため、このデータを変換する必要があります。
08/05/2014,9:10,BRONX,10469,40.8733019,-73.8536375,"(40.8733019, -73.8536375)",
これは columns: パラメータの始まりです。
-H "columns:tmp_CRASH_DATE, tmp_CRASH_TIME, CRASH_DATE=str_to_date(concat_ws(' ', tmp_CRASH_DATE, tmp_CRASH_TIME), '%m/%d/%Y %H:%i')
これは StarRocks に次のことを指示します:
- CSV ファイルの最初の列の内容を
tmp_CRASH_DATEに割り当てる - CSV ファイルの2番目の列の内容を
tmp_CRASH_TIMEに割り当てる concat_ws()はtmp_CRASH_DATEとtmp_CRASH_TIMEをスペースで連結しますstr_to_date()は連結された文字列から DATETIME を作成します- 結果の DATETIME を
CRASH_DATE列に保存します
詳細情報
Motor Vehicle Collisions - Crashes データセットは、ニューヨーク市によってこれらの 利用規約 および プライバシーポリシー に基づいて提供されています。
Local Climatological Data (LCD) は、NOAAによってこの 免責事項 およびこの プライバシーポリシー と共に提供されています。
