HDFS からデータをロードする
StarRocks は、Broker Load を使用して HDFS からデータを一括ロードすることができます。
Broker Load は非同期モードで動作します。非同期の Broker Load プロセスは、GCS への接続を確立し、データを取得し、StarRocks にデータを保存する処理を行います。
Broker Load は Parquet、ORC、CSV ファイル形式をサポートしています。
Broker Load の利点
- Broker Load はバックグラウンドで実行され、クライアントはジョブが続行するために接続を維持する必要がありません。
- Broker Load は長時間実行されるジョブに適しており、デフォルトのタイムアウトは 4 時間に設定されています。
- Parquet と ORC ファイル形式に加えて、Broker Load �は CSV ファイルもサポートしています。
データフロー
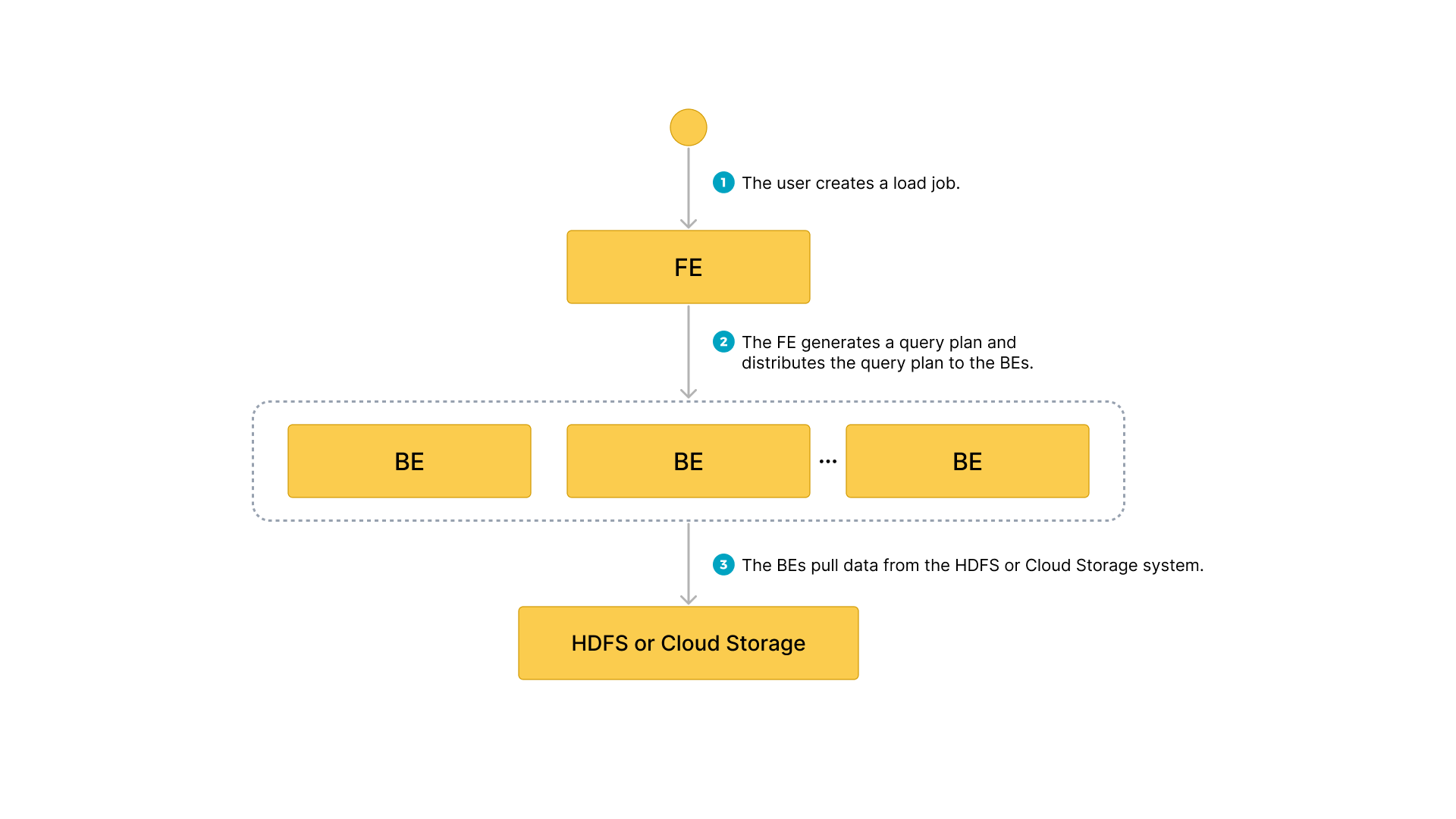
- ユーザーがロードジョブを作成します。
- フロントエンド (FE) がクエリプランを作成し、そのプランをバックエンドノード (BEs) またはコンピュートノード (CNs) に配布します。
- BEs または CNs がソースからデータを取得し、StarRocks にデータをロードします。
始める前に
ソースデータを準備する
StarRocks にロードしたいソースデータが HDFS クラスターに適切に保存されていることを確認してください。このトピックでは、HDFS から /user/amber/user_behavior_ten_million_rows.parquet を StarRocks にロードすることを前提としています。
権限を確認する
StarRocks テーブルにデータを ロード できるのは、これらの StarRocks テーブルに対して INSERT 権限を持つユーザーのみです。INSERT 権限を持っていない場合は、 GRANT に記載されている手順に従って、StarRocks クラスターに接続するために使用するユーザーに INSERT 権限を付与してください。
認証情報を収集する
HDFS クラスターとの接続を確立するために、シンプルな認証方法を使用できます。シンプルな認証を使用するには、HDFS クラスターの NameNode にアクセスするためのアカウントのユーザー名とパスワードを収集する必要があります。
典型的な例
テーブルを作成し、HDFS からデータファイル /user/amber/user_behavior_ten_million_rows.parquet を取得するロードプロセスを開始し、データロードの進捗と成功を確認します。
データベースとテーブルを作成する
データベースを作成し、そこに切り替えます:
CREATE DATABASE IF NOT EXISTS mydatabase;
USE mydatabase;
手動でテーブルを作成します(HDFS からロードしたい Parquet ファイルと同じスキーマを持つことをお勧めします):
CREATE TABLE user_behavior
(
UserID int(11),
ItemID int(11),
CategoryID int(11),
BehaviorType varchar(65533),
Timestamp datetime
)
ENGINE = OLAP
DUPLICATE KEY(UserID)
DISTRIBUTED BY HASH(UserID);
Broker Load を開始する
以下のコマンドを実行して、HDFS のデータファイル /user/amber/user_behavior_ten_million_rows.parquet から user_behavior テーブルにデータをロードする Broker Load ジョブを開始します:
LOAD LABEL user_behavior
(
DATA INFILE("hdfs://<hdfs_ip>:<hdfs_port>/user/amber/user_behavior_ten_million_rows.parquet")
INTO TABLE user_behavior
FORMAT AS "parquet"
)
WITH BROKER
(
"hadoop.security.authentication" = "simple",
"username" = "<hdfs_username>",
"password" = "<hdfs_password>"
)
PROPERTIES
(
"timeout" = "72000"
);
このジョブには 4 つの主要なセクションがあります:
LABEL: ロードジョブの状態をクエリする際に使用される文字列。LOAD宣言: ソース URI、ソースデータ形式、および宛先テーブル名。BROKER: ソースの接続情報。PROPERTIES: タイムアウト値およびロードジョブに適用するその他のプロパティ。
詳細な構文とパラメータの説明については、BROKER LOAD を参照してください。
ロードの進捗を確認する
information_schema.loads ビューから Broker Load ジョブの進捗をクエリできます。この機能は v3.1 以降でサポートされています。
SELECT * FROM information_schema.loads;
loads ビューで提供されるフィールドに関する情報は、Information Schema を参照してください。
複数のロードジョブを送信した場合は、ジョブに関連付けられた LABEL でフィルタリングできます。例:
SELECT * FROM information_schema.loads WHERE LABEL = 'user_behavior';
以下の出力には、ロードジョブ user_behavior に対する 2 つのエントリがあります:
- 最初のレコードは
CANCELLED状態を示しています。ERROR_MSGまでスクロールすると、listPath failedによりジョブが失敗したことがわかります。 - 2 番目のレコードは
FINISHED状態を示しており、ジョブが成功したことを意味します。
JOB_ID|LABEL |DATABASE_NAME|STATE |PROGRESS |TYPE |PRIORITY|SCAN_ROWS|FILTERED_ROWS|UNSELECTED_ROWS|SINK_ROWS|ETL_INFO|TASK_INFO |CREATE_TIME |ETL_START_TIME |ETL_FINISH_TIME |LOAD_START_TIME |LOAD_FINISH_TIME |JOB_DETAILS |ERROR_MSG |TRACKING_URL|TRACKING_SQL|REJECTED_RECORD_PATH|
------+-------------------------------------------+-------------+---------+-------------------+------+--------+---------+-------------+---------------+---------+--------+----------------------------------------------------+-------------------+-------------------+-------------------+-------------------+-------------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+--------------------------------------+------------+------------+--------------------+
10121|user_behavior |mydatabase |CANCELLED|ETL:N/A; LOAD:N/A |BROKER|NORMAL | 0| 0| 0| 0| |resource:N/A; timeout(s):72000; max_filter_ratio:0.0|2023-08-10 14:59:30| | | |2023-08-10 14:59:34|{"All backends":{},"FileNumber":0,"FileSize":0,"InternalTableLoadBytes":0,"InternalTableLoadRows":0,"ScanBytes":0,"ScanRows":0,"TaskNumber":0,"Unfinished backends":{}} |type:ETL_RUN_FAIL; msg:listPath failed| | | |
10106|user_behavior |mydatabase |FINISHED |ETL:100%; LOAD:100%|BROKER|NORMAL | 86953525| 0| 0| 86953525| |resource:N/A; timeout(s):72000; max_filter_ratio:0.0|2023-08-10 14:50:15|2023-08-10 14:50:19|2023-08-10 14:50:19|2023-08-10 14:50:19|2023-08-10 14:55:10|{"All backends":{"a5fe5e1d-d7d0-4826-ba99-c7348f9a5f2f":[10004]},"FileNumber":1,"FileSize":1225637388,"InternalTableLoadBytes":2710603082,"InternalTableLoadRows":86953525,"ScanBytes":1225637388,"ScanRows":86953525,"TaskNumber":1,"Unfinished backends":{"a5| | | | |
ロードジョブが完了したことを確認した後、宛先テーブルの一部をチェックしてデータが正常にロードされたかどうかを確認できます。例:
SELECT * from user_behavior LIMIT 3;
以下のクエリ結果が返され、データが正常にロードされたことを示しています:
+--------+---------+------------+--------------+---------------------+
| UserID | ItemID | CategoryID | BehaviorType | Timestamp |
+--------+---------+------------+--------------+---------------------+
| 142 | 2869980 | 2939262 | pv | 2017-11-25 03:43:22 |
| 142 | 2522236 | 1669167 | pv | 2017-11-25 15:14:12 |
| 142 | 3031639 | 3607361 | pv | 2017-11-25 15:19:25 |
+--------+---------+------------+--------------+---------------------+
