Hive catalog
Hive catalog は、Apache Hive™ からデータを取り込まずにクエリを実行できる外部 catalog の一種です。
また、Hive catalogs を基に INSERT INTO を使用して、Hive からデータを直接変換してロードすることもできます。StarRocks は v2.4 以降の Hive catalogs をサポートしています。
Hive クラスターで SQL ワークロードを成功させるためには、StarRocks クラスターが Hive クラスターのストレージシステムとメタストアにアクセスできる必要があります。StarRocks は以下のストレージシステムとメタストアをサポートしています。
- AWS S3 や HDFS のようなオブジェクトストレージまたは分散ファイルシステム
- Hive メタストアや AWS Glue のようなメタストア
使用上の注意
-
StarRocks がサポートする Hive のファイル形式は Parquet、ORC、Textfile です。
- Parquet ファイルは以下の圧縮形式をサポートします: SNAPPY、LZ4、ZSTD、GZIP、NO_COMPRESSION。
- ORC ファイルは以下の圧縮形式をサポートします: ZLIB、SNAPPY、LZO、LZ4、ZSTD、NO_COMPRESSION。
-
StarRocks がサポートしない Hive のデータ型は INTERVAL、BINARY、UNION です。さらに、StarRocks は Textfile 形式の Hive テーブルに対して MAP と STRUCT データ型をサポートしていません。
-
Hive catalogs はデータのクエリにのみ使用できます。Hive catalogs を使用して Hive クラスター内のデータを削除、削除、または挿入することはできません。
統合準備
Hive catalog を作成する前に、StarRocks クラスターが Hive クラスターのストレージシステムとメタストアと統合できることを確認してください。
AWS IAM
Hive クラスターが AWS S3 をストレージとして使用している場合、または AWS Glue をメタストアとして使用している場合、適切な認証方法を選択し、StarRocks クラスターが関連する AWS クラウドリソースにアクセスできるように必要な準備を行ってください。
以下の認証方法が推奨されます。
- インスタンスプロファイル
- アサームドロール
- IAM ユーザー
上記の3つの認証方法の中で、インスタンスプロファイルが最も広く使用されています。
詳細については、AWS IAM での認証準備を参照してください。
HDFS
HDFS をストレージとして選択する場合、StarRocks クラスターを次のように構成します。
-
(オプション) HDFS クラスターおよび Hive メタストアにアクセスするために使用されるユーザー名を設定します。デフォルトでは、StarRocks は HDFS クラスターおよび Hive メタストアにアクセスするために FE および BE プロセスのユーザー名を使用します。また、各 FE の fe/conf/hadoop_env.sh ファイルおよび各 BE の be/conf/hadoop_env.sh ファイルの先頭に
export HADOOP_USER_NAME="<user_name>"を追加してユーザー名を設定することもできます。これらのファイルでユーザー名を設定した後、各 FE および各 BE を再起動してパラメータ設定を有効にします。StarRocks クラスターごとに1つのユーザー名しか設定できません。 -
Hive データをクエリする際、StarRocks クラスターの FEs および BEs は HDFS クライアントを使用して HDFS クラスターにアクセスします。ほとんどの場合、その目的を達成するために StarRocks クラスターを構成する必要はなく、StarRocks はデフォルトの構成を使用して HDFS クライアントを起動します。次の状況でのみ StarRocks クラスターを構成する必要があります。
- HDFS クラスターに高可用性 (HA) が有効になっている場合: HDFS クラスターの hdfs-site.xml ファイルを各 FE の $FE_HOME/conf パスおよび各 BE の $BE_HOME/conf パスに追加します。
- HDFS クラスターに View File System (ViewFs) が有効になっている場合: HDFS クラスターの core-site.xml ファイルを各 FE の $FE_HOME/conf パスおよび各 BE の $BE_HOME/conf パスに追加します。
注意
クエリを送信した際に不明なホストを示すエラーが返された場合、HDFS クラスターのノードのホスト名と IP アドレスのマッピングを /etc/hosts パスに追加する必要があります。
Kerberos 認証
HDFS クラスターまたは Hive メタストアに Kerberos 認証が有効になっている場合、StarRocks クラスターを次のように構成します。
- 各 FE および各 BE で
kinit -kt keytab_path principalコマンドを実行して、Key Distribution Center (KDC) から Ticket Granting Ticket (TGT) を取得します。このコマンドを実行するには、HDFS クラスターおよび Hive メタストアにアクセスする権限が必要です。このコマンドを使用して KDC にアクセスすることは時間に敏感です。したがって、このコマンドを定期的に実行するために cron を使用する必要があります。 - 各 FE の $FE_HOME/conf/fe.conf ファイルおよび各 BE の $BE_HOME/conf/be.conf ファイルに
JAVA_OPTS="-Djava.security.krb5.conf=/etc/krb5.conf"を追加します。この例では、/etc/krb5.confは krb5.conf ファイルの保存パスです。必要に応じてパスを変更できます。
Hive catalog を作成する
構文
CREATE EXTERNAL CATALOG <catalog_name>
[COMMENT <comment>]
PROPERTIES
(
"type" = "hive",
GeneralParams,
MetastoreParams,
StorageCredentialParams,
MetadataUpdateParams
)
パラメータ
catalog_name
Hive catalog の名前です。命名規則は次のとおりです。
- 名前には文字、数字 (0-9)、アンダースコア (_) を含めることができます。名前は文字で始まる必要があります。
- 名前は大文字と小文字を区別し、長さは1023文字を超えることはできません。
comment
Hive catalog の説明です。このパラメータはオプションです。
type
データソースのタイプです。値を hive に設定します。
GeneralParams
一般的なパラメータのセットです。
GeneralParams で構成できるパラメータを次の表に示します。
| パラメータ | 必須 | 説明 |
|---|---|---|
| enable_recursive_listing | いいえ | StarRocks がテーブルとそのパーティション、およびテーブルとそのパーティションの物理的な場所内のサブディレクトリからデータを読み取るかどうかを指定します。有効な値: true および false。デフォルト値: true。値 true はサブディレクトリを再帰的にリストすることを指定し、値 false はサブディレクトリを無視することを指定します。 |
MetastoreParams
StarRocks がデータソースのメタストアと統合する方法に関するパラメータのセットです。
Hive メタストア
データソースのメタストアとして Hive メタストアを選択する場合、MetastoreParams を次のように構成します。
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "<hive_metastore_uri>"
注意
Hive データをクエリする前に、Hive メタストアノードのホスト名と IP アドレスのマッピングを
/etc/hostsパスに追加する必要があります。そうしないと、クエリを開始したときに StarRocks が Hive メタストアにアクセスできない可能性があります。
MetastoreParams で構成する必要があるパラメータを次の表に示します。
| パラメータ | 必須 | 説明 |
|---|---|---|
| hive.metastore.type | はい | Hive クラスターで使用するメタストアのタイプです。値を hive に設定します。 |
| hive.metastore.uris | はい | Hive メタストアの URI です。形式: thrift://<metastore_IP_address>:<metastore_port>。Hive メタストアに高可用性 (HA) が有効になっている場合、複数のメタストア URI を指定し、カンマ ( ,) で区切ることができます。例: "thrift://<metastore_IP_address_1>:<metastore_port_1>,thrift://<metastore_IP_address_2>:<metastore_port_2>,thrift://<metastore_IP_address_3>:<metastore_port_3>"。 |
AWS Glue
データソースのメタストアとして AWS Glue を選択する場合、次のいずれかの操作を行います。
-
インスタンスプロファイルベースの認証方法を選択するには、
MetastoreParamsを次のように構成します。"hive.metastore.type" = "glue",
"aws.glue.use_instance_profile" = "true",
"aws.glue.region" = "<aws_glue_region>" -
アサームドロールベースの認証方法を選択するには、
MetastoreParamsを次のように構成します。"hive.metastore.type" = "glue",
"aws.glue.use_instance_profile" = "true",
"aws.glue.iam_role_arn" = "<iam_role_arn>",
"aws.glue.region" = "<aws_glue_region>" -
IAM ユーザーベースの認証方法を選択するには、
MetastoreParamsを次のように構成します。"hive.metastore.type" = "glue",
"aws.glue.use_instance_profile" = "false",
"aws.glue.access_key" = "<iam_user_access_key>",
"aws.glue.secret_key" = "<iam_user_secret_key>",
"aws.glue.region" = "<aws_s3_region>"
MetastoreParams で構成する必要があるパラメータを次の表に示します。
| パラメータ | 必須 | 説明 |
|---|---|---|
| hive.metastore.type | はい | Hive クラスターで使用するメタストアのタイプです。値を glue に設定します。 |
| aws.glue.use_instance_profile | はい | インスタンスプロファイルベースの認証方法とアサームドロールベースの認証を有効にするかどうかを指定します。有効な値: true および false。デフォルト値: false。 |
| aws.glue.iam_role_arn | いいえ | AWS Glue Data Catalog に対する権限を持つ IAM ロールの ARN です。AWS Glue にアクセスするためにアサームドロールベースの認証方法を使用する場合、このパラメータを指定する必要があります。 |
| aws.glue.region | はい | AWS Glue Data Catalog が存在するリージョンです。例: us-west-1。 |
| aws.glue.access_key | いいえ | AWS IAM ユーザーのアクセスキーです。IAM ユーザーベースの認証方法を使用して AWS Glue にアクセスする場合、このパラメータを指定する必要があります。 |
| aws.glue.secret_key | いいえ | AWS IAM ユーザーのシークレットキーです。IAM ユーザーベースの認証方法を使用して AWS Glue にアクセスする場合、このパラメータを指定する必要があります。 |
AWS Glue にアクセスするための認証方法の選択方法と AWS IAM コンソールでのアクセス制御ポリシーの構成方法については、AWS Glue へのアクセスのための認証パラメータを参照してください。
StorageCredentialParams
StarRocks がストレージシステムと統合する方法に関するパラメータのセットです。このパラメータセットはオプションです。
Hive クラスターが AWS S3 をストレージとして使用している場合にのみ StorageCredentialParams を構成する必要があります。
Hive クラスターが他のストレージシステムを使用している場合、StorageCredentialParams を無視できます。
AWS S3
Hive クラスターのストレージとして AWS S3 を選択する場合、次のいずれかの操作を行います。
-
インスタンスプロファイルベースの認証方法を選択するには、
StorageCredentialParamsを次のように構成します。"aws.s3.use_instance_profile" = "true",
"aws.s3.region" = "<aws_s3_region>" -
アサームドロールベースの認証方法を選択するには、
StorageCredentialParamsを次のように構成します。"aws.s3.use_instance_profile" = "true",
"aws.s3.iam_role_arn" = "<iam_role_arn>",
"aws.s3.region" = "<aws_s3_region>" -
IAM ユーザーベースの認証方法を選択するには、
StorageCredentialParamsを次のように構成します。"aws.s3.use_instance_profile" = "false",
"aws.s3.access_key" = "<iam_user_access_key>",
"aws.s3.secret_key" = "<iam_user_secret_key>",
"aws.s3.region" = "<aws_s3_region>"
StorageCredentialParams で構成する必要があるパラメータを次の表に示します。
| パラメータ | 必須 | 説明 |
|---|---|---|
| aws.s3.use_instance_profile | はい | インスタンスプロファイルベースの認証方法とアサームドロールベースの認証方法を有効にするかどうかを指定します。有効な値: true および false。デフォルト値: false。 |
| aws.s3.iam_role_arn | いいえ | AWS S3 バケットに対する権限を持つ IAM ロールの ARN です。AWS S3 にアクセスするためにアサームドロールベースの認証方法を使用する場合、このパラメータを指定する必要があります。 |
| aws.s3.region | はい | AWS S3 バケットが存在するリージョンです。例: us-west-1。 |
| aws.s3.access_key | いいえ | IAM ユーザーのアクセスキーです。IAM ユーザーベースの認証方法を使用して AWS S3 にアクセスする場合、このパラメータを指定する必要があります。 |
| aws.s3.secret_key | いいえ | IAM ユーザーのシークレットキーです。IAM ユーザーベースの認証方法を使用して AWS S3 にアクセスする場合、このパラメータを指定する必要があります。 |
AWS S3 にアクセスするための認証方法の選択方法と AWS IAM コンソールでのアクセス制御ポリシーの構成方法については、AWS S3 へのアクセスのための認証パラメータを参照してください。
S3 互換ストレージシステム
Hive catalogs は v2.5 以降で S3 互換ストレージシステムをサポートしています。
S3 互換ストレージシステム (例: MinIO) を Hive クラスターのストレージとして選択する場合、StorageCredentialParams を次のように構成して、統合を成功させます。
"aws.s3.enable_ssl" = "{true | false}",
"aws.s3.enable_path_style_access" = "{true | false}",
"aws.s3.endpoint" = "<s3_endpoint>",
"aws.s3.access_key" = "<iam_user_access_key>",
"aws.s3.secret_key" = "<iam_user_secret_key>"
StorageCredentialParams で構成する必要があるパラメータを次の表に示します。
| パラメータ | 必須 | 説明 |
|---|---|---|
| aws.s3.enable_ssl | はい | SSL 接続を有効にするかどうかを指定します。 有効な値: true および false。デフォルト値: true。 |
| aws.s3.enable_path_style_access | はい | パススタイルアクセスを有効にするかどうかを指定します。 有効な値: true および false。デフォルト値: false。MinIO の場合、値を true に設定する必要があります。パススタイル URL は次の形式を使用します: https://s3.<region_code>.amazonaws.com/<bucket_name>/<key_name>。たとえば、US West (オレゴン) リージョンに DOC-EXAMPLE-BUCKET1 という名前のバケットを作成し、そのバケット内の alice.jpg オブジェクトにアクセスしたい場合、次のパススタイル URL を使用できます: https://s3.us-west-2.amazonaws.com/DOC-EXAMPLE-BUCKET1/alice.jpg。 |
| aws.s3.endpoint | はい | AWS S3 の代わりに S3 互換ストレージシステムに接続するために使用されるエンドポイントです。 |
| aws.s3.access_key | はい | IAM ユーザーのアクセスキーです。 |
| aws.s3.secret_key | はい | IAM ユーザーのシークレットキーです。 |
MetadataUpdateParams
StarRocks が Hive のキャッシュされたメタデータを更新する方法に関するパラメータのセットです。このパラメータセットはオプションです。
StarRocks はデフォルトで 自動非同期更新ポリシー を実装しています。
ほとんどの場合、MetadataUpdateParams を無視し、その中のポリシーパラメータを調整する必要はありません。これらのパラメータのデフォルト値は、すぐに使えるパフォーマンスを提供します。
ただし、Hive のデータ更新頻度が高い場合は、これらのパラメータを調整して自動非同期更新のパフォーマンスをさらに最適化できます。
注意
ほとんどの場合、Hive データが 1 時間以下の粒度で更新される場合、データ更新頻度は高いと見なされます。
| パラメータ | 必須 | 説明 |
|---|---|---|
| enable_metastore_cache | いいえ | StarRocks が Hive テーブルのメタデータをキャッシュするかどうかを指定します。有効な値: true および false。デフォルト値: true。値 true はキャッシュを有効にし、値 false はキャッシュを無効にします。 |
| enable_remote_file_cache | いいえ | StarRocks が Hive テーブルまたはパーティションの基礎となるデータファイルのメタデータをキャッシュするかどうかを指定します。有効な値: true および false。デフォルト値: true。値 true はキャッシュを有効にし、値 false はキャッシュを無効にします。 |
| metastore_cache_refresh_interval_sec | いいえ | StarRocks が自身にキャッシュされた Hive テーブルまたはパーティションのメタデータを非同期で更新する時間間隔です。単位: 秒。デフォルト値: 7200 (2 時間)。 |
| remote_file_cache_refresh_interval_sec | いいえ | StarRocks が自身にキャッシュされた Hive テーブルまたはパーティションの基礎となるデータファイルのメタデータを非同期で更新する時間間隔です。単位: 秒。デフォルト値: 60。 |
| metastore_cache_ttl_sec | いいえ | StarRocks が自身にキャッシュされた Hive テーブルまたはパーティションのメタデータを自動的に破棄する時間間隔です。単位: 秒。デフォルト値: 86400 (24 時間)。 |
| remote_file_cache_ttl_sec | いいえ | StarRocks が自身にキャッシュされた Hive テーブルまたはパーティションの基礎となるデータファイルのメタデータを自動的に破棄する時間間隔です。単位: 秒。デフォルト値: 129600 (36 時間)。 |
| enable_cache_list_names | いいえ | StarRocks が Hive パーティション名をキャッシュするかどうかを指定します。有効な値: true および false。デフォルト値: false。値 true はキャッシュを有効にし、値 false はキャッシュを無効にします。 |
例
以下の例は、使用するメタストアのタイプに応じて、hive_catalog_hms または hive_catalog_glue という名前の Hive catalog を作成し、Hive クラスターからデータをクエリします。
HDFS
HDFS をストレージとして使用する場合、次のようなコマンドを実行します。
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083"
);
AWS S3
インスタンスプロファイルベースの認証
-
Hive クラスターで Hive メタストアを使用する場合、次のようなコマンドを実行します。
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"aws.s3.use_instance_profile" = "true",
"aws.s3.region" = "us-west-2"
); -
Amazon EMR Hive クラスターで AWS Glue を使用する場合、次のようなコマンドを実行します。
CREATE EXTERNAL CATALOG hive_catalog_glue
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "glue",
"aws.glue.use_instance_profile" = "true",
"aws.glue.region" = "us-west-2",
"aws.s3.use_instance_profile" = "true",
"aws.s3.region" = "us-west-2"
);
アサームドロールベースの認証
-
Hive クラスターで Hive メタストアを使用する場合、次のようなコマンドを実行します。
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"aws.s3.use_instance_profile" = "true",
"aws.s3.iam_role_arn" = "arn:aws:iam::081976408565:role/test_s3_role",
"aws.s3.region" = "us-west-2"
); -
Amazon EMR Hive クラスターで AWS Glue を使用する場合、次のようなコマンドを実行します。
CREATE EXTERNAL CATALOG hive_catalog_glue
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "glue",
"aws.glue.use_instance_profile" = "true",
"aws.glue.iam_role_arn" = "arn:aws:iam::081976408565:role/test_glue_role",
"aws.glue.region" = "us-west-2",
"aws.s3.use_instance_profile" = "true",
"aws.s3.iam_role_arn" = "arn:aws:iam::081976408565:role/test_s3_role",
"aws.s3.region" = "us-west-2"
);
IAM ユーザーベースの認証
-
Hive クラスターで Hive メタストアを使用する場合、次のようなコマンドを実行します。
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"aws.s3.use_instance_profile" = "false",
"aws.s3.access_key" = "<iam_user_access_key>",
"aws.s3.secret_key" = "<iam_user_access_key>",
"aws.s3.region" = "us-west-2"
); -
Amazon EMR Hive クラスターで AWS Glue を使用する場合、次のようなコマンドを実行します。
CREATE EXTERNAL CATALOG hive_catalog_glue
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "glue",
"aws.glue.use_instance_profile" = "false",
"aws.glue.access_key" = "<iam_user_access_key>",
"aws.glue.secret_key" = "<iam_user_secret_key>",
"aws.glue.region" = "us-west-2",
"aws.s3.use_instance_profile" = "false",
"aws.s3.access_key" = "<iam_user_access_key>",
"aws.s3.secret_key" = "<iam_user_secret_key>",
"aws.s3.region" = "us-west-2"
);
S3 互換ストレージシステム
MinIO を例にとります。次のようなコマンドを実行します。
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"aws.s3.enable_ssl" = "true",
"aws.s3.enable_path_style_access" = "true",
"aws.s3.endpoint" = "<s3_endpoint>",
"aws.s3.access_key" = "<iam_user_access_key>",
"aws.s3.secret_key" = "<iam_user_secret_key>"
);
Hive テーブルのスキーマを表示する
Hive テーブルのスキーマを表示するには、次のいずれかの構文を使用します。
-
スキーマを表示
DESC[RIBE] <catalog_name>.<database_name>.<table_name> -
CREATE ステートメントからスキーマと場所を表示
SHOW CREATE TABLE <catalog_name>.<database_name>.<table_name>
Hive テーブルをクエリする
-
次の構文を使用して、Hive クラスター内のデータベースを表示します。
SHOW DATABASES FROM <catalog_name> -
次の構文を使用して、ターゲットの Hive データベースに接続します。
USE <catalog_name>.<database_name> -
次の構文を使用して、Hive テーブルをクエリします。
SELECT count(*) FROM <table_name> LIMIT 10
Hive からデータをロードする
olap_tbl という名前の OLAP テーブルがあると仮定して、次のようにデータを変換してロードできます。
INSERT INTO default_catalog.olap_db.olap_tbl SELECT * FROM hive_table
メタデータキャッシュを手動または自動で更新する
手動更新
デフォルトでは、StarRocks は Hive のメタデータをキャッシュし、パフォーマンスを向上させるために非同期モードでメタデータを自動的に更新します。さらに、Hive テーブルでいくつかのスキーマ変更やテーブル更新が行われた後、REFRESH EXTERNAL TABLE を使用してメタデータを手動で更新し、StarRocks が最新のメタデータをできるだけ早く取得し、適切な実行プランを生成できるようにすることもできます。
REFRESH EXTERNAL TABLE <table_name>
次の状況でメタデータを手動で更新する必要があります。
-
既存のパーティションのデータファイルが変更された場合 (例:
INSERT OVERWRITE ... PARTITION ...コマンドを実行した場合)。 -
Hive テーブルでスキーマ変更が行われた場合。
-
DROP ステートメントを使用して既存の Hive テーブルが削除され、削除された Hive テーブルと同じ名前の新しい Hive テーブルが作成された場合。
-
Hive catalog の作成時に
PROPERTIESで"enable_cache_list_names" = "true"を指定しており、Hive クラスターで新しく作成したパーティションをクエリしたい場合。注意
v2.5.5 以降、StarRocks は定期的な Hive メタデータキャッシュの更新機能を提供しています。詳細については、このトピックの下の「メタデータキャッシュを定期的に更新する」セクションを参照してください。この機能を有効にすると、StarRocks はデフォルトで 10 分ごとに Hive メタデータキャッシュを更新します。したがって、ほとんどの場合、手動更新は必要ありません。新しいパーティションを Hive クラスターで作成した直後にクエリしたい場合にのみ、手動更新を行う必要があります。
REFRESH EXTERNAL TABLE は、FEs にキャッシュされたテーブルとパーティションのみを更新します。
メタデータキャッシュを定期的に更新する
v2.5.5 以降、StarRocks は頻繁にアクセスされる Hive catalogs のキャッシュされたメタデータを定期的に更新してデータの変更を検知できます。次の FE パラメータ を使用して Hive メタデータキャッシュの更新を構成できます。
| 構成項目 | デフォルト | 説明 |
|---|---|---|
| enable_background_refresh_connector_metadata | true in v3.0false in v2.5 | 定期的な Hive メタデータキャッシュの更新を有効にするかどうか。これを有効にすると、StarRocks は Hive クラスターのメタストア (Hive Metastore または AWS Glue) をポーリングし、頻繁にアクセスされる Hive catalogs のキャッシュされたメタデータを更新してデータの変更を検知します。true は Hive メタデータキャッシュの更新を有効にし、false は無効にします。この項目は FE 動的パラメータ です。ADMIN SET FRONTEND CONFIG コマンドを使用して変更できます。 |
| background_refresh_metadata_interval_millis | 600000 (10 分) | 2 回の連続した Hive メタデータキャッシュの更新の間隔です。単位: ミリ秒。この項目は FE 動的パラメータ です。ADMIN SET FRONTEND CONFIG コマンドを使用して変更できます。 |
| background_refresh_metadata_time_secs_since_last_access_secs | 86400 (24 時間) | Hive メタデータキャッシュ更新タスクの有効期限です。アクセスされた Hive catalog に対して、指定された時間を超えてアクセスされていない場合、StarRocks はキャッシュされたメタデータの更新を停止します。アクセスされていない Hive catalog に対して、StarRocks はキャッシュされたメタデータを更新しません。単位: 秒。この項目は FE 動的パラメータ です。ADMIN SET FRONTEND CONFIG コマンドを使用して変更できます。 |
| 定期的な Hive メタデータキャッシュの更新機能とメタデータ自動非同期更新ポリシーを組み合わせて使用することで、データアクセスが大幅に高速化され、外部データソースからの読み取り負荷が軽減され、クエリパフォーマンスが向上します。 |
付録: 自動非同期更新を理解する
自動非同期更新は、StarRocks が Hive catalogs のメタデータを更新するために使用するデフォルトのポリシーです。
デフォルトでは (enable_metastore_cache および enable_remote_file_cache パラメータが両方とも true に設定されている場合)、クエリが Hive テーブルのパーティションにヒットすると、StarRocks はそのパーティションのメタデータとそのパーティションの基礎となるデータファイルのメタデータを自動的にキャッシュします。キャッシュされたメタデータは、遅延更新ポリシーを使用して更新されます。
たとえば、table2 という名前の Hive テーブルがあり、4 つのパーティション p1、p2、p3、p4 を持っているとします。クエリが p1 にヒットすると、StarRocks は p1 のメタデータと p1 の基礎となるデータファイルのメタデータをキャッシュします。キャッシュされたメタデータを更新および破棄するデフォルトの時間間隔は次のとおりです。
metastore_cache_refresh_interval_secパラメータで指定された、p1のキャッシュされたメタデータを非同期で更新する時間間隔は 2 時間です。remote_file_cache_refresh_interval_secパラメータで指定された、p1の基礎となるデータファイルのキャッシュされたメタデータを非同期で更新する時間間隔は 60 秒です。metastore_cache_ttl_secパラメータで指定された、p1のキャッシュされたメタデータを自動的に破棄する時間間隔は 24 時間です。remote_file_cache_ttl_secパラメータで指定された、p1の基礎となるデータファイルのキャッシュされたメタデータを自動的に破棄する時間間隔は 36 時間です。
以下の図は、理解を容易にするためのタイムライン上の時間間隔を示しています。
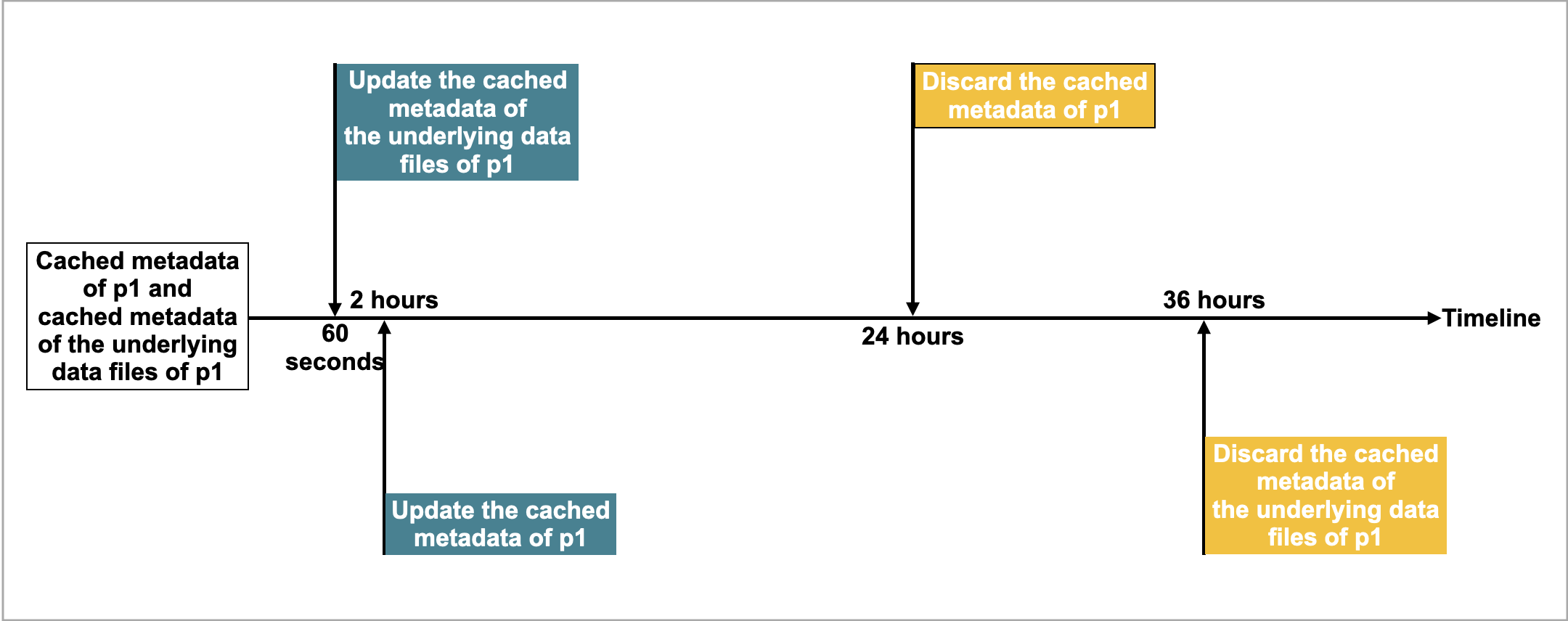
その後、StarRocks は次のルールに従ってメタデータを更新または破棄します。
- 別のクエリが再び
p1にヒットし、最後の更新からの現在の時間が 60 秒未満の場合、StarRocks はp1のキャッシュされたメタデータやp1の基礎となるデータファイルのキャッシュされたメタデータを更新しません。 - 別のクエリが再び
p1にヒットし、最後の更新からの現在の時間が 60 秒を超える場合、StarRocks はp1の基礎となるデータファイルのキャッシュされたメタデータを更新します。 - 別のクエリが再び
p1にヒットし、最後の更新からの現在の時間が 2 時間を超える場合、StarRocks はp1のキャッシュされたメタデータを更新します。 p1が最後の更新から 24 時間以内にアクセスされていない場合、StarRocks はp1のキャッシュされたメタデータを破棄します。次のクエリでメタデータがキャッシュされます。p1が最後の更新から 36 時間以内にアクセスされていない場合、StarRocks はp1の基礎となるデータファイルのキャッシュされたメタデータを破棄します。次のクエリでメタデータがキャッシュされます。