クエリ分析
クエリパフォーマンスを最適化する方法は、よくある質問です。遅いクエリは、ユーザーエクスペリエンスやクラスターのパフォーマンスに悪影響を与えます。クエリパフォーマンスを分析し、最適化することが重要です。
クエリ情報は fe/log/fe.audit.log で確認できます。各クエリには QueryID が対応しており、これを使用してクエリの QueryPlan と Profile を検索できます。QueryPlan は、FE が SQL 文を解析して生成する実行計画です。Profile は BE の実行結果で、各ステップで消費された時間や処理されたデータ量などの情報を含みます。
プラン分析
StarRocks では、SQL 文のライフサイクルはクエリ解析、クエリプランニング、クエリ実行の3つのフェーズに分けられます。分析ワークロードに必要な QPS は高くないため、クエリ解析は一般的にボトルネックにはなりません。
StarRocks のクエリパフォーマンスは、クエリプランニングとクエリ実行によって決まります。クエリプランニングはオペレーター (Join/Order/Aggregate) を調整し、クエリ実行は具体的な操作を実行します。
クエリプランは、DBA にクエリ情報をマクロ的にアクセスするための手段を提供します。クエリプランはクエリパフォーマンスの鍵であり、DBA が参照するための良いリソースです。以下のコードスニペットは、TPCDS query96 を例に、クエリプランの表示方法を示しています。
-- query96.sql
select count(*)
from store_sales
,household_demographics
,time_dim
, store
where ss_sold_time_sk = time_dim.t_time_sk
and ss_hdemo_sk = household_demographics.hd_demo_sk
and ss_store_sk = s_store_sk
and time_dim.t_hour = 8
and time_dim.t_minute >= 30
and household_demographics.hd_dep_count = 5
and store.s_store_name = 'ese'
order by count(*) limit 100;
クエリプランには2種類あります。論理クエリプランと物理クエリプランです。ここで説明するクエリプランは論理クエリプランを指します。TPCDS query96.sql に対応するクエリプランは以下の通りです。
+------------------------------------------------------------------------------+
| Explain String |
+------------------------------------------------------------------------------+
| PLAN FRAGMENT 0 |
| OUTPUT EXPRS:<slot 11> |
| PARTITION: UNPARTITIONED |
| RESULT SINK |
| 12:MERGING-EXCHANGE |
| limit: 100 |
| tuple ids: 5 |
| |
| PLAN FRAGMENT 1 |
| OUTPUT EXPRS: |
| PARTITION: RANDOM |
| STREAM DATA SINK |
| EXCHANGE ID: 12 |
| UNPARTITIONED |
| |
| 8:TOP-N |
| | order by: <slot 11> ASC |
| | offset: 0 |
| | limit: 100 |
| | tuple ids: 5 |
| | |
| 7:AGGREGATE (update finalize) |
| | output: count(*) |
| | group by: |
| | tuple ids: 4 |
| | |
| 6:HASH JOIN |
| | join op: INNER JOIN (BROADCAST) |
| | hash predicates: |
| | colocate: false, reason: left hash join node can not do colocate |
| | equal join conjunct: `ss_store_sk` = `s_store_sk` |
| | tuple ids: 0 2 1 3 |
| | |
| |----11:EXCHANGE |
| | tuple ids: 3 |
| | |
| 4:HASH JOIN |
| | join op: INNER JOIN (BROADCAST) |
| | hash predicates: |
| | colocate: false, reason: left hash join node can not do colocate |
| | equal join conjunct: `ss_hdemo_sk`=`household_demographics`.`hd_demo_sk`|
| | tuple ids: 0 2 1 |
| | |
| |----10:EXCHANGE |
| | tuple ids: 1 |
| | |
| 2:HASH JOIN |
| | join op: INNER JOIN (BROADCAST) |
| | hash predicates: |
| | colocate: false, reason: table not in same group |
| | equal join conjunct: `ss_sold_time_sk` = `time_dim`.`t_time_sk` |
| | tuple ids: 0 2 |
| | |
| |----9:EXCHANGE |
| | tuple ids: 2 |
| | |
| 0:OlapScanNode |
| TABLE: store_sales |
| PREAGGREGATION: OFF. Reason: `ss_sold_time_sk` is value column |
| partitions=1/1 |
| rollup: store_sales |
| tabletRatio=0/0 |
| tabletList= |
| cardinality=-1 |
| avgRowSize=0.0 |
| numNodes=0 |
| tuple ids: 0 |
| |
| PLAN FRAGMENT 2 |
| OUTPUT EXPRS: |
| PARTITION: RANDOM |
| |
| STREAM DATA SINK |
| EXCHANGE ID: 11 |
| UNPARTITIONED |
| |
| 5:OlapScanNode |
| TABLE: store |
| PREAGGREGATION: OFF. Reason: null |
| PREDICATES: `store`.`s_store_name` = 'ese' |
| partitions=1/1 |
| rollup: store |
| tabletRatio=0/0 |
| tabletList= |
| cardinality=-1 |
| avgRowSize=0.0 |
| numNodes=0 |
| tuple ids: 3 |
| |
| PLAN FRAGMENT 3 |
| OUTPUT EXPRS: |
| PARTITION: RANDOM |
| STREAM DATA SINK |
| EXCHANGE ID: 10 |
| UNPARTITIONED |
| |
| 3:OlapScanNode |
| TABLE: household_demographics |
| PREAGGREGATION: OFF. Reason: null |
| PREDICATES: `household_demographics`.`hd_dep_count` = 5 |
| partitions=1/1 |
| rollup: household_demographics |
| tabletRatio=0/0 |
| tabletList= |
| cardinality=-1 |
| avgRowSize=0.0 |
| numNodes=0 |
| tuple ids: 1 |
| |
| PLAN FRAGMENT 4 |
| OUTPUT EXPRS: |
| PARTITION: RANDOM |
| STREAM DATA SINK |
| EXCHANGE ID: 09 |
| UNPARTITIONED |
| |
| 1:OlapScanNode |
| TABLE: time_dim |
| PREAGGREGATION: OFF. Reason: null |
| PREDICATES: `time_dim`.`t_hour` = 8, `time_dim`.`t_minute` >= 30 |
| partitions=1/1 |
| rollup: time_dim |
| tabletRatio=0/0 |
| tabletList= |
| cardinality=-1 |
| avgRowSize=0.0 |
| numNodes=0 |
| tuple ids: 2 |
+------------------------------------------------------------------------------+
128 rows in set (0.02 sec)
クエリ 96 は、いくつかの StarRocks の概念を含むクエリプランを示しています。
| 名前 | 説明 |
|---|---|
| avgRowSize | スキャンされたデータ行の平均サイズ |
| cardinality | スキャンされたテーブルのデータ行の総数 |
| colocate | テーブルがコロケートモードかどうか |
| numNodes | スキャンされるノードの数 |
| rollup | マテリアライズドビュー |
| preaggregation | 事前集計 |
| predicates | 述語、クエリフィルター |
クエリ 96 のクエリプランは、0 から 4 までの5つのフラグメントに分かれています。クエリプランは、下から上に順に読み取ることができます。
フラグメント 4 は、time_dim テーブルをスキャンし、関連するクエリ条件(すなわち time_dim.t_hour = 8 and time_dim.t_minute >= 30)を事前に実行する役割を担っています。このステップは述語プッシュダウンとも呼ばれます。StarRocks は、集計テーブルに対して PREAGGREGATION を有効にするかどうかを決定します。前の図では、time_dim の事前集計は無効になっています。この場合、time_dim のすべてのディメンション列が読み取られ、テーブルに多くのディメンション列がある場合、パフォーマンスに悪影響を与える可能性があります。time_dim テーブルがデータ分割に range partition を選択した場合、クエリプランでいくつかのパーティションがヒットし、無関係なパーティションは自動的にフィルタリングされます。マテリアライズドビューがある場合、StarRocks はクエリに基づいてマテリアライズドビューを自動的に選択します。マテリアライズドビューがない場合、クエリは自動的にベーステーブルをヒットします(前の図の rollup: time_dim など)。
スキャンが完了すると、フラグメント 4 は終了します。データは、前の図で EXCHANGE ID : 09 と示されるように、受信ノードラベル 9 に他のフラグメントに渡されます。
クエリ 96 のクエリプランでは、フラグメント 2、3、および 4 は類似の機能を持っていますが、異なるテーブルのスキャンを担当しています。具体的には、クエリ内の Order/Aggregation/Join 操作はフラグメント 1 で実行されます。
フラグメント 1 は BROADCAST メソッドを使用して Order/Aggregation/Join 操作を実行します。つまり、小さなテーブルを大きなテーブルにブロードキャストします。両方のテーブルが大きい場合は、SHUFFLE メソッドを使用することをお勧めします。現在、StarRocks は HASH JOIN のみをサポートしています。colocate フィールドは、結合された2つのテーブルが同じ方法でパーティション分割およびバケット化されていることを示し、データを移動せずにローカルでジョイン操作を実行できることを示します。ジョイン操作が完了すると、上位レベルの aggregation、order by、および top-n 操作が実行されます。
特定の式を削除し(オペレーターのみを保持)、クエリプランをよりマクロ的なビューで提示することができます。以下の図に示されています。
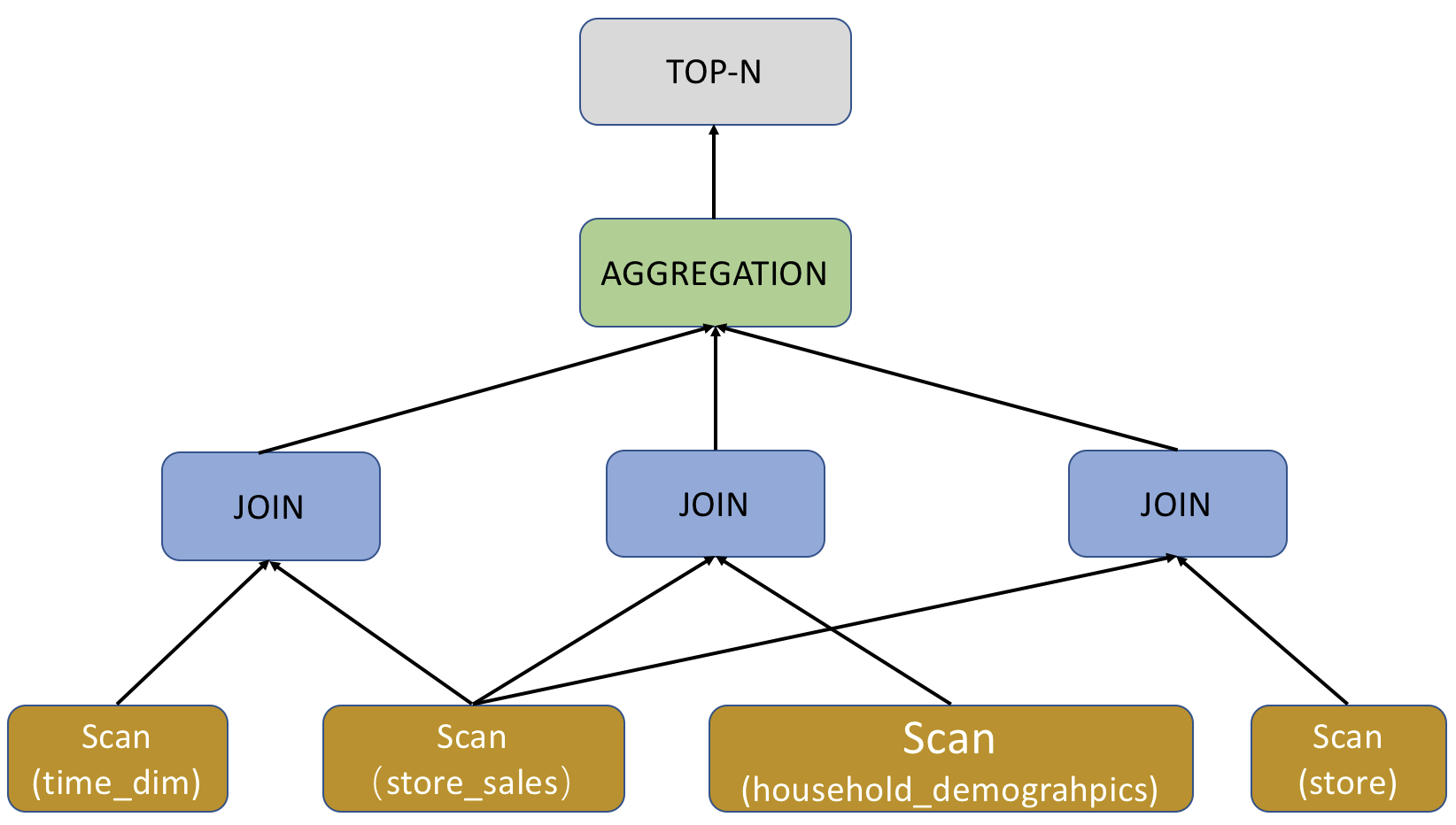
SQL フィンガープリント
SQL フィンガープリントは、遅いクエリを最適化し、システムリソースの利用を改善するために使用されます。StarRocks は、遅いクエリログ (fe.audit.log.slow_query) で SQL フィンガープリント機能を使用して SQL 文を正規化し、SQL 文を異なるタイプに分類し、各 SQL タイプの MD5 ハッシュ値を計算して遅いクエリを特定します。MD5 ハッシュ値はフィールド Digest によって指定されます。
2021-12-27 15:13:39,108 [slow_query] |Client=172.26.xx.xxx:54956|User=root|Db=default_cluster:test|State=EOF|Time=2469|ScanBytes=0|ScanRows=0|ReturnRows=6|StmtId=3|QueryId=824d8dc0-66e4-11ec-9fdc-00163e04d4c2|IsQuery=true|feIp=172.26.92.195|Stmt=select count(*) from test_basic group by id_bigint|Digest=51390da6b57461f571f0712d527320f4
SQL 文の正規化は、文のテキストをより正規化された形式に変換し、重要な文の構造のみを保持します。
-
データベースやテーブル名などのオブジェクト識別子を保持します。
-
定数を疑問符 (?) に変換します。
-
コメントを削除し、スペースをフォーマットします。
たとえば、以下の2つの SQL 文は、正規化後に同じタイプに属します。
- 正規化前の SQL 文
SELECT * FROM orders WHERE customer_id=10 AND quantity>20
SELECT * FROM orders WHERE customer_id = 20 AND quantity > 100
- 正規化後の SQL 文
SELECT * FROM orders WHERE customer_id=? AND quantity>?