Cluster Snapshot
This topic describes how to use Cluster Snapshot for disaster recovery on shared-data clusters.
This feature is supported from v3.4.2 onwards and only available on shared-data clusters.
Overview
The fundamental idea of disaster recovery for shared-data clusters is to ensure that the full cluster state (including data and metadata) is stored in object storage. This way, if the cluster encounters a failure, it can be restored from the object storage as long as the data and metadata remain intact. Additionally, features like backups and cross-region replication offered by cloud providers can be used to achieve remote recovery and cross-region disaster recovery.
In shared-data clusters, the CN state (data) is stored in object storage, but the FE state (metadata) remains local. To ensure that object storage has all the cluster state for restoration, StarRocks now supports Cluster Snapshot for both data and metadata in object storage.
Workflow
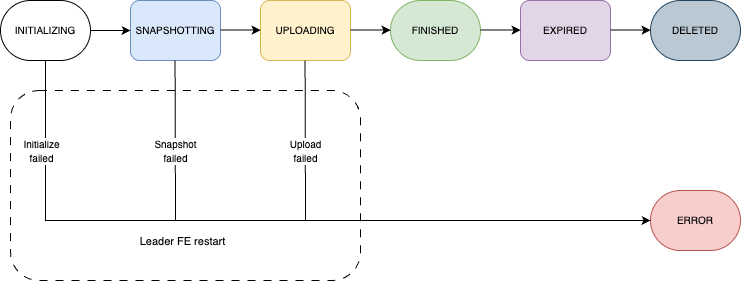
Terms
-
Cluster snapshot
A cluster snapshot refers to a snapshot of the cluster state at a certain moment. It contains all the objects in the cluster, such as catalogs, databases, tables, users & privileges, loading tasks, and more. It does not include all external dependent objects, such as configuration files of external catalogs, and local UDF JAR packages.
-
Generating cluster snapshot
The system automatically maintains a snapshot closely following the latest cluster state. Historical snapshots will be dropped right after the latest one is created, keeping only one snapshot available all the time.
-
Cluster Restore
Restore the cluster from a snapshot.
Automated cluster snapshot
Automated Cluster Snapshot is disabled by default.
Use the following statement to enable this feature:
Syntax:
ADMIN SET AUTOMATED CLUSTER SNAPSHOT ON
[STORAGE VOLUME <storage_volume_name>]
Parameter:
storage_volume_name: Specifies the storage volume used to store the snapshot. If this parameter is not specified, the default storage volume will be used. For details on creating a storage volume, see CREATE STORAGE VOLUME.
Each time FE creates a new metadata image after completing a metadata checkpoint, it automatically creates a snapshot. The name of the snapshot is generated by the system, following the format automated_cluster_snapshot_{timestamp}.
Metadata snapshots are stored under /{storage_volume_locations}/{service_id}/meta/image/automated_cluster_snapshot_timestamp. Data snapshots are stored in the same location as the original data.
FE configuration item automated_cluster_snapshot_interval_seconds controls the snapshot automation cycle. The default value is 600 seconds (10 minutes).
Disable automated cluster snapshot
Use the following statement to disable automated cluster snapshot:
ADMIN SET AUTOMATED CLUSTER SNAPSHOT OFF
Once Automated Cluster Snapshot is disabled, the system will automatically purge the historical snapshot.
View cluster snapshot
You can query the view information_schema.cluster_snapshots to view the latest cluster snapshot and the snapshots yet to be dropped.
SELECT * FROM information_schema.cluster_snapshots;
Return:
| Field | Description |
|---|---|
| snapshot_name | The name of the snapshot. |
| snapshot_type | The type of the snapshot. Valid values: automated and manual. |
| created_time | The time at which the snapshot was created. |
| fe_journal_id | The ID of the FE journal. |
| starmgr_journal_id | The ID of the StarManager journal. |
| properties | Applies to a feature not yet available. |
| storage_volume | The storage volume where the snapshot is stored. |
| storage_path | The storage path under which the snapshot is stored. |
View cluster snapshot job
You can query the view information_schema.cluster_snapshot_jobs to view the job information of cluster snapshots.
SELECT * FROM information_schema.cluster_snapshot_jobs;
Return:
| Field | Description |
|---|---|
| snapshot_name | The name of the snapshot. |
| job_id | The ID of the job. |
| created_time | The time at which the job was created. |
| finished_time | The time at which the job was finished. |
| state | The state of the job. Valid values: INITIALIZING, SNAPSHOTING, FINISHED, EXPIRED, DELETED, and ERROR. |
| detail_info | The specific progress information of the current execution stage. |
| error_message | The error message (if any) of the job. |
Restore the cluster
Follow these steps to restore the cluster with the cluster snapshot.
-
(Optional) If you want to perform a cross-cluster recovery within the region, you MUST modify the configuration file cluster_snapshot.yaml under the directory
fe/confof the Leader FE node. Otherwise, you can skip this step.To restore the data in a new cluster, all files under the original storage path must be copied to the new path. You must use the template provided in Appendix.
-
Start the Leader FE node.
./fe/bin/start_fe.sh --cluster_snapshot --daemon -
Start other FE nodes after cleaning the
metadirectories../fe/bin/start_fe.sh --helper <leader_ip>:<leader_edit_log_port> --daemon -
Start CN nodes after cleaning the
storage_root_pathdirectories../be/bin/start_cn.sh --daemon
If you have modified cluster_snapshot.yaml in the step 1, the node and storage volumes will be re-configured in the new cluster according to the information in the file.
Appendix
Template of cluster_snapshot.yaml for cross-cluster recovery:
# Information of the cluster snapshot to be downloaded for restoration.
cluster_snapshot:
# The URI of the snapshot.
# Example 1: s3://defaultbucket/test/f7265e80-631c-44d3-a8ac-cf7cdc7adec811019/meta/image/automated_cluster_snapshot_1704038400000
# Example 2: s3://defaultbucket/test/f7265e80-631c-44d3-a8ac-cf7cdc7adec811019/meta
cluster_snapshot_path: <cluster_snapshot_uri>
# The name of the storage volume to store the snapshot. You must define it in the `storage_volumes` section.
# NOTE: It must be identical with that in the original cluster.
storage_volume_name: my_s3_volume
# [Optional] Node information of the new cluster where the snapshot is to be restored.
# If this section is not specified, the new cluster after recovery only has the Leader FE node.
# CN nodes retain the information of the original cluster.
# NOTE: DO NOT include the Leader FE node in this section.
frontends:
# FE host.
- host: xxx.xx.xx.x1
# FE edit_log_port.
edit_log_port: 9010
# The FE node type. Valid values: `follower` (Default) and `observer`.
type: follower
- host: xxx.xx.xx.x2
edit_log_port: 9010
type: observer
compute_nodes:
# CN host.
- host: xxx.xx.xx.x3
# CN heartbeat_service_port.
heartbeat_service_port: 9050
- host: xxx.xx.xx.x4
heartbeat_service_port: 9050
# Information of the storage volume in the new cluster. It is used for restoring a cloned snapshot.
# NOTE: The name of the storage volume must be identical with that in the original cluster.
storage_volumes:
# Example for S3-compatible storage volume.
- name: my_s3_volume
type: S3
location: s3://defaultbucket/test/
comment: my s3 volume
properties:
- key: aws.s3.region
value: us-west-2
- key: aws.s3.endpoint
value: https://s3.us-west-2.amazonaws.com
- key: aws.s3.access_key
value: xxxxxxxxxx
- key: aws.s3.secret_key
value: yyyyyyyyyy
# Example for HDFS storage volume.
- name: my_hdfs_volume
type: HDFS
location: hdfs://127.0.0.1:9000/sr/test/
comment: my hdfs volume
properties:
- key: hadoop.security.authentication
value: simple
- key: username
value: starrocks
For more information on credentials for AWS, see Authenticate to AWS S3.
Limitations
- Currently, standby mode is not supported. The primary and secondary clusters cannot be online simultaneously. Otherwise, the normal operation of the secondary cluster cannot be guaranteed.
- Currently, only one automated cluster snapshot can be retained.
