Hive catalog
A Hive catalog is a kind of external catalog that is supported by StarRocks from v2.4 onwards. Within Hive catalogs, you can:
- Directly query data stored in Hive without the need to manually create tables.
- Use INSERT INTO or asynchronous materialized views (which are supported from v2.5 onwards) to process data stored in Hive and load the data into StarRocks.
- Perform operations on StarRocks to create or drop Hive databases and tables, or sink data from StarRocks tables to Parquet-formatted Hive tables by using INSERT INTO (this feature is supported from v3.2 onwards).
To ensure successful SQL workloads on your Hive cluster, your StarRocks cluster must be able to access the storage system and metastore of your Hive cluster. StarRocks supports the following storage systems and metastores:
-
Distributed file system (HDFS) or object storage like AWS S3, Microsoft Azure Storage, Google GCS, or other S3-compatible storage system (for example, MinIO)
-
Metastore like Hive metastore or AWS Glue
noteIf you choose AWS S3 as storage, you can use HMS or AWS Glue as metastore. If you choose any other storage system, you can only use HMS as metastore.
Usage notes
-
The file formats of Hive that StarRocks supports are Parquet, ORC, Textfile, Avro, RCFile, and SequenceFile:
- Parquet files support the following compression formats: SNAPPY, LZ4, ZSTD, GZIP, and NO_COMPRESSION. From v3.1.5 onwards, Parquet files also support the LZO compression format.
- ORC files support the following compression formats: ZLIB, SNAPPY, LZO, LZ4, ZSTD, and NO_COMPRESSION.
- Textfile files support the LZO compression format from v3.1.5 onwards.
-
The data types of Hive that StarRocks does not support are INTERVAL, BINARY, and UNION. Additionally, StarRocks does not support the MAP and STRUCT data types for Textfile-formatted Hive tables.
Integration preparations
Before you create a Hive catalog, make sure your StarRocks cluster can integrate with the storage system and metastore of your Hive cluster.
AWS IAM
If your Hive cluster uses AWS S3 as storage or AWS Glue as metastore, choose your suitable authentication method and make the required preparations to ensure that your StarRocks cluster can access the related AWS cloud resources.
The following authentication methods are recommended:
- Instance profile
- Assumed role
- IAM user
Of the above-mentioned three authentication methods, instance profile is the most widely used.
For more information, see Preparation for authentication in AWS IAM.
HDFS
If you choose HDFS as storage, configure your StarRocks cluster as follows:
-
(Optional) Set the username that is used to access your HDFS cluster and Hive metastore. By default, StarRocks uses the username of the FE and BE or CN processes to access your HDFS cluster and Hive metastore. You can also set the username by adding
export HADOOP_USER_NAME="<user_name>"at the beginning of the fe/conf/hadoop_env.sh file of each FE and at the beginning of the be/conf/hadoop_env.sh file of each BE or the cn/conf/hadoop_env.sh file of each CN. After you set the username in these files, restart each FE and each BE or CN to make the parameter settings take effect. You can set only one username for each StarRocks cluster. -
When you query Hive data, the FEs and BEs or CNs of your StarRocks cluster use the HDFS client to access your HDFS cluster. In most cases, you do not need to configure your StarRocks cluster to achieve that purpose, and StarRocks starts the HDFS client using the default configurations. You need to configure your StarRocks cluster only in the following situations:
- High availability (HA) is enabled for your HDFS cluster: Add the hdfs-site.xml file of your HDFS cluster to the $FE_HOME/conf path of each FE and to the $BE_HOME/conf path of each BE or the $CN_HOME/conf path of each CN.
- View File System (ViewFs) is enabled for your HDFS cluster: Add the core-site.xml file of your HDFS cluster to the $FE_HOME/conf path of each FE and to the $BE_HOME/conf path of each BE or the $CN_HOME/conf path of each CN.
If an error indicating an unknown host is returned when you send a query, you must add the mapping between the host names and IP addresses of your HDFS cluster nodes to the /etc/hosts path.
Kerberos authentication
If Kerberos authentication is enabled for your HDFS cluster or Hive metastore, configure your StarRocks cluster as follows:
- Run the
kinit -kt keytab_path principalcommand on each FE and each BE or CN to obtain Ticket Granting Ticket (TGT) from Key Distribution Center (KDC). To run this command, you must have the permissions to access your HDFS cluster and Hive metastore. Note that accessing KDC with this command is time-sensitive. Therefore, you need to use cron to run this command periodically. - Add
JAVA_OPTS="-Djava.security.krb5.conf=/etc/krb5.conf"to the $FE_HOME/conf/fe.conf file of each FE and to the $BE_HOME/conf/be.conf file of each BE or the $CN_HOME/conf/cn.conf file of each CN. In this example,/etc/krb5.confis the save path of the krb5.conf file. You can modify the path based on your needs.
Create a Hive catalog
Syntax
CREATE EXTERNAL CATALOG <catalog_name>
[COMMENT <comment>]
PROPERTIES
(
"type" = "hive",
GeneralParams,
MetastoreParams,
StorageCredentialParams,
MetadataUpdateParams
)
Parameters
catalog_name
The name of the Hive catalog. The naming conventions are as follows:
- The name can contain letters, digits (0-9), and underscores (_). It must start with a letter.
- The name is case-sensitive and cannot exceed 1023 characters in length.
comment
The description of the Hive catalog. This parameter is optional.
type
The type of your data source. Set the value to hive.
GeneralParams
A set of general parameters.
The following table describes the parameters you can configure in GeneralParams.
| Parameter | Required | Description |
|---|---|---|
| enable_recursive_listing | No | Specifies whether StarRocks reads data from a table and its partitions and from the subdirectories within the physical locations of the table and its partitions. Valid values: true and false. Default value: true. The value true specifies to recursively list subdirectories, and the value false specifies to ignore subdirectories. |
MetastoreParams
A set of parameters about how StarRocks integrates with the metastore of your data source.
Hive metastore
If you choose Hive metastore as the metastore of your data source, configure MetastoreParams as follows:
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "<hive_metastore_uri>"
Before querying Hive data, you must add the mapping between the host names and IP addresses of your Hive metastore nodes to the /etc/hosts path. Otherwise, StarRocks may fail to access your Hive metastore when you start a query.
The following table describes the parameter you need to configure in MetastoreParams.
| Parameter | Required | Description |
|---|---|---|
| hive.metastore.type | Yes | The type of metastore that you use for your Hive cluster. Set the value to hive. |
| hive.metastore.uris | Yes | The URI of your Hive metastore. Format: thrift://<metastore_IP_address>:<metastore_port>.If high availability (HA) is enabled for your Hive metastore, you can specify multiple metastore URIs and separate them with commas ( ,), for example, "thrift://<metastore_IP_address_1>:<metastore_port_1>,thrift://<metastore_IP_address_2>:<metastore_port_2>,thrift://<metastore_IP_address_3>:<metastore_port_3>". |
AWS Glue
If you choose AWS Glue as the metastore of your data source, which is supported only when you choose AWS S3 as storage, take one of the following actions:
-
To choose the instance profile-based authentication method, configure
MetastoreParamsas follows:"hive.metastore.type" = "glue",
"aws.glue.use_instance_profile" = "true",
"aws.glue.region" = "<aws_glue_region>" -
To choose the assumed role-based authentication method, configure
MetastoreParamsas follows:"hive.metastore.type" = "glue",
"aws.glue.use_instance_profile" = "true",
"aws.glue.iam_role_arn" = "<iam_role_arn>",
"aws.glue.region" = "<aws_glue_region>" -
To choose the IAM user-based authentication method, configure
MetastoreParamsas follows:"hive.metastore.type" = "glue",
"aws.glue.use_instance_profile" = "false",
"aws.glue.access_key" = "<iam_user_access_key>",
"aws.glue.secret_key" = "<iam_user_secret_key>",
"aws.glue.region" = "<aws_s3_region>"
The following table describes the parameters you need to configure in MetastoreParams.
| Parameter | Required | Description |
|---|---|---|
| hive.metastore.type | Yes | The type of metastore that you use for your Hive cluster. Set the value to glue. |
| aws.glue.use_instance_profile | Yes | Specifies whether to enable the instance profile-based authentication method and the assumed role-based authentication. Valid values: true and false. Default value: false. |
| aws.glue.iam_role_arn | No | The ARN of the IAM role that has privileges on your AWS Glue Data Catalog. If you use the assumed role-based authentication method to access AWS Glue, you must specify this parameter. |
| aws.glue.region | Yes | The region in which your AWS Glue Data Catalog resides. Example: us-west-1. |
| aws.glue.access_key | No | The access key of your AWS IAM user. If you use the IAM user-based authentication method to access AWS Glue, you must specify this parameter. |
| aws.glue.secret_key | No | The secret key of your AWS IAM user. If you use the IAM user-based authentication method to access AWS Glue, you must specify this parameter. |
For information about how to choose an authentication method for accessing AWS Glue and how to configure an access control policy in the AWS IAM Console, see Authentication parameters for accessing AWS Glue.
StorageCredentialParams
A set of parameters about how StarRocks integrates with your storage system. This parameter set is optional.
If you use HDFS as storage, you do not need to configure StorageCredentialParams.
If you use AWS S3, other S3-compatible storage system, Microsoft Azure Storage, or Google GCS as storage, you must configure StorageCredentialParams.
AWS S3
If you choose AWS S3 as storage for your Hive cluster, take one of the following actions:
-
To choose the instance profile-based authentication method, configure
StorageCredentialParamsas follows:"aws.s3.use_instance_profile" = "true",
"aws.s3.region" = "<aws_s3_region>" -
To choose the assumed role-based authentication method, configure
StorageCredentialParamsas follows:"aws.s3.use_instance_profile" = "true",
"aws.s3.iam_role_arn" = "<iam_role_arn>",
"aws.s3.region" = "<aws_s3_region>" -
To choose the IAM user-based authentication method, configure
StorageCredentialParamsas follows:"aws.s3.use_instance_profile" = "false",
"aws.s3.access_key" = "<iam_user_access_key>",
"aws.s3.secret_key" = "<iam_user_secret_key>",
"aws.s3.region" = "<aws_s3_region>"
The following table describes the parameters you need to configure in StorageCredentialParams.
| Parameter | Required | Description |
|---|---|---|
| aws.s3.use_instance_profile | Yes | Specifies whether to enable the instance profile-based authentication method and the assumed role-based authentication method. Valid values: true and false. Default value: false. |
| aws.s3.iam_role_arn | No | The ARN of the IAM role that has privileges on your AWS S3 bucket. If you use the assumed role-based authentication method to access AWS S3, you must specify this parameter. |
| aws.s3.region | Yes | The region in which your AWS S3 bucket resides. Example: us-west-1. |
| aws.s3.access_key | No | The access key of your IAM user. If you use the IAM user-based authentication method to access AWS S3, you must specify this parameter. |
| aws.s3.secret_key | No | The secret key of your IAM user. If you use the IAM user-based authentication method to access AWS S3, you must specify this parameter. |
For information about how to choose an authentication method for accessing AWS S3 and how to configure an access control policy in AWS IAM Console, see Authentication parameters for accessing AWS S3.
S3-compatible storage system
Hive catalogs support S3-compatible storage systems from v2.5 onwards.
If you choose an S3-compatible storage system, such as MinIO, as storage for your Hive cluster, configure StorageCredentialParams as follows to ensure a successful integration:
"aws.s3.enable_ssl" = "false",
"aws.s3.enable_path_style_access" = "true",
"aws.s3.endpoint" = "<s3_endpoint>",
"aws.s3.access_key" = "<iam_user_access_key>",
"aws.s3.secret_key" = "<iam_user_secret_key>"
The following table describes the parameters you need to configure in StorageCredentialParams.
| Parameter | Required | Description |
|---|---|---|
| aws.s3.enable_ssl | Yes | Specifies whether to enable SSL connection. Valid values: true and false. Default value: true. |
| aws.s3.enable_path_style_access | Yes | Specifies whether to enable path-style access. Valid values: true and false. Default value: false. For MinIO, you must set the value to true.Path-style URLs use the following format: https://s3.<region_code>.amazonaws.com/<bucket_name>/<key_name>. For example, if you create a bucket named DOC-EXAMPLE-BUCKET1 in the US West (Oregon) Region, and you want to access the alice.jpg object in that bucket, you can use the following path-style URL: https://s3.us-west-2.amazonaws.com/DOC-EXAMPLE-BUCKET1/alice.jpg. |
| aws.s3.endpoint | Yes | The endpoint that is used to connect to your S3-compatible storage system instead of AWS S3. |
| aws.s3.access_key | Yes | The access key of your IAM user. |
| aws.s3.secret_key | Yes | The secret key of your IAM user. |
Microsoft Azure Storage
Hive catalogs support Microsoft Azure Storage from v3.0 onwards.
Azure Blob Storage
If you choose Blob Storage as storage for your Hive cluster, take one of the following actions:
-
To choose the Shared Key authentication method, configure
StorageCredentialParamsas follows:"azure.blob.storage_account" = "<storage_account_name>",
"azure.blob.shared_key" = "<storage_account_shared_key>"The following table describes the parameters you need to configure in
StorageCredentialParams.Parameter Required Description azure.blob.storage_account Yes The username of your Blob Storage account. azure.blob.shared_key Yes The shared key of your Blob Storage account. -
To choose the SAS Token authentication method, configure
StorageCredentialParamsas follows:"azure.blob.storage_account" = "<storage_account_name>",
"azure.blob.container" = "<container_name>",
"azure.blob.sas_token" = "<storage_account_SAS_token>"The following table describes the parameters you need to configure in
StorageCredentialParams.Parameter Required Description azure.blob.storage_account Yes The username of your Blob Storage account. azure.blob.container Yes The name of the blob container that stores your data. azure.blob.sas_token Yes The SAS token that is used to access your Blob Storage account.
Azure Data Lake Storage Gen2
If you choose Data Lake Storage Gen2 as storage for your Hive cluster, take one of the following actions:
-
To choose the Managed Identity authentication method, configure
StorageCredentialParamsas follows:"azure.adls2.oauth2_use_managed_identity" = "true",
"azure.adls2.oauth2_tenant_id" = "<service_principal_tenant_id>",
"azure.adls2.oauth2_client_id" = "<service_client_id>"The following table describes the parameters you need to configure in
StorageCredentialParams.Parameter Required Description azure.adls2.oauth2_use_managed_identity Yes Specifies whether to enable the Managed Identity authentication method. Set the value to true.azure.adls2.oauth2_tenant_id Yes The ID of the tenant whose data you want to access. azure.adls2.oauth2_client_id Yes The client (application) ID of the managed identity. -
To choose the Shared Key authentication method, configure
StorageCredentialParamsas follows:"azure.adls2.storage_account" = "<storage_account_name>",
"azure.adls2.shared_key" = "<storage_account_shared_key>"The following table describes the parameters you need to configure in
StorageCredentialParams.Parameter Required Description azure.adls2.storage_account Yes The username of your Data Lake Storage Gen2 storage account. azure.adls2.shared_key Yes The shared key of your Data Lake Storage Gen2 storage account. -
To choose the Service Principal authentication method, configure
StorageCredentialParamsas follows:"azure.adls2.oauth2_client_id" = "<service_client_id>",
"azure.adls2.oauth2_client_secret" = "<service_principal_client_secret>",
"azure.adls2.oauth2_client_endpoint" = "<service_principal_client_endpoint>"The following table describes the parameters you need to configure
in StorageCredentialParams.Parameter Required Description azure.adls2.oauth2_client_id Yes The client (application) ID of the service principal. azure.adls2.oauth2_client_secret Yes The value of the new client (application) secret created. azure.adls2.oauth2_client_endpoint Yes The OAuth 2.0 token endpoint (v1) of the service principal or application.
Azure Data Lake Storage Gen1
If you choose Data Lake Storage Gen1 as storage for your Hive cluster, take one of the following actions:
-
To choose the Managed Service Identity authentication method, configure
StorageCredentialParamsas follows:"azure.adls1.use_managed_service_identity" = "true"The following table describes the parameters you need to configure in
StorageCredentialParams.Parameter Required Description azure.adls1.use_managed_service_identity Yes Specifies whether to enable the Managed Service Identity authentication method. Set the value to true. -
To choose the Service Principal authentication method, configure
StorageCredentialParamsas follows:"azure.adls1.oauth2_client_id" = "<application_client_id>",
"azure.adls1.oauth2_credential" = "<application_client_credential>",
"azure.adls1.oauth2_endpoint" = "<OAuth_2.0_authorization_endpoint_v2>"The following table describes the parameters you need to configure in
StorageCredentialParams.Parameter Required Description azure.adls1.oauth2_client_id Yes The client (application) ID of the service principal. azure.adls1.oauth2_credential Yes The value of the new client (application) secret created. azure.adls1.oauth2_endpoint Yes The OAuth 2.0 token endpoint (v1) of the service principal or application.
Google GCS
Hive catalogs support Google GCS from v3.0 onwards.
If you choose Google GCS as storage for your Hive cluster, take one of the following actions:
-
To choose the VM-based authentication method, configure
StorageCredentialParamsas follows:"gcp.gcs.use_compute_engine_service_account" = "true"The following table describes the parameters you need to configure in
StorageCredentialParams.Parameter Default value Value example Description gcp.gcs.use_compute_engine_service_account false true Specifies whether to directly use the service account that is bound to your Compute Engine. -
To choose the service account-based authentication method, configure
StorageCredentialParamsas follows:"gcp.gcs.service_account_email" = "<google_service_account_email>",
"gcp.gcs.service_account_private_key_id" = "<google_service_private_key_id>",
"gcp.gcs.service_account_private_key" = "<google_service_private_key>"The following table describes the parameters you need to configure in
StorageCredentialParams.Parameter Default value Value example Description gcp.gcs.service_account_email "" "user@hello.iam.gserviceaccount.com" The email address in the JSON file generated at the creation of the service account. gcp.gcs.service_account_private_key_id "" "61d257bd8479547cb3e04f0b9b6b9ca07af3b7ea" The private key ID in the JSON file generated at the creation of the service account. gcp.gcs.service_account_private_key "" "-----BEGIN PRIVATE KEY----xxxx-----END PRIVATE KEY-----\n" The private key in the JSON file generated at the creation of the service account. -
To choose the impersonation-based authentication method, configure
StorageCredentialParamsas follows:-
Make a VM instance impersonate a service account:
"gcp.gcs.use_compute_engine_service_account" = "true",
"gcp.gcs.impersonation_service_account" = "<assumed_google_service_account_email>"The following table describes the parameters you need to configure in
StorageCredentialParams.Parameter Default value Value example Description gcp.gcs.use_compute_engine_service_account false true Specifies whether to directly use the service account that is bound to your Compute Engine. gcp.gcs.impersonation_service_account "" "hello" The service account that you want to impersonate. -
Make a service account (temporarily named as meta service account) impersonate another service account (temporarily named as data service account):
"gcp.gcs.service_account_email" = "<google_service_account_email>",
"gcp.gcs.service_account_private_key_id" = "<meta_google_service_account_email>",
"gcp.gcs.service_account_private_key" = "<meta_google_service_account_email>",
"gcp.gcs.impersonation_service_account" = "<data_google_service_account_email>"The following table describes the parameters you need to configure in
StorageCredentialParams.Parameter Default value Value example Description gcp.gcs.service_account_email "" "user@hello.iam.gserviceaccount.com" The email address in the JSON file generated at the creation of the meta service account. gcp.gcs.service_account_private_key_id "" "61d257bd8479547cb3e04f0b9b6b9ca07af3b7ea" The private key ID in the JSON file generated at the creation of the meta service account. gcp.gcs.service_account_private_key "" "-----BEGIN PRIVATE KEY----xxxx-----END PRIVATE KEY-----\n" The private key in the JSON file generated at the creation of the meta service account. gcp.gcs.impersonation_service_account "" "hello" The data service account that you want to impersonate.
-
MetadataUpdateParams
A set of parameters about how StarRocks updates the cached metadata of Hive. This parameter set is optional.
StarRocks implements the automatic asynchronous update policy by default.
In most cases, you can ignore MetadataUpdateParams and do not need to tune the policy parameters in it, because the default values of these parameters already provide you with an out-of-the-box performance.
However, if the frequency of data updates in Hive is high, you can tune these parameters to further optimize the performance of automatic asynchronous updates.
In most cases, if your Hive data is updated at a granularity of 1 hour or less, the data update frequency is considered high.
| Parameter | Required | Description |
|---|---|---|
| enable_metastore_cache | No | Specifies whether StarRocks caches the metadata of Hive tables. Valid values: true and false. Default value: true. The value true enables the cache, and the value false disables the cache. |
| enable_remote_file_cache | No | Specifies whether StarRocks caches the metadata of the underlying data files of Hive tables or partitions. Valid values: true and false. Default value: true. The value true enables the cache, and the value false disables the cache. |
| metastore_cache_refresh_interval_sec | No | The time interval at which StarRocks asynchronously updates the metadata of Hive tables or partitions cached in itself. Unit: seconds. Default value: 7200, which is 2 hours. |
| remote_file_cache_refresh_interval_sec | No | The time interval at which StarRocks asynchronously updates the metadata of the underlying data files of Hive tables or partitions cached in itself. Unit: seconds. Default value: 60. |
| metastore_cache_ttl_sec | No | The time interval at which StarRocks automatically discards the metadata of Hive tables or partitions cached in itself. Unit: seconds. Default value: 86400, which is 24 hours. |
| remote_file_cache_ttl_sec | No | The time interval at which StarRocks automatically discards the metadata of the underlying data files of Hive tables or partitions cached in itself. Unit: seconds. Default value: 129600, which is 36 hours. |
| enable_cache_list_names | No | Specifies whether StarRocks caches Hive partition names. Valid values: true and false. Default value: true. The value true enables the cache, and the value false disables the cache. |
Examples
The following examples create a Hive catalog named hive_catalog_hms or hive_catalog_glue, depending on the type of metastore you use, to query data from your Hive cluster.
HDFS
If you use HDFS as storage, run a command like below:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083"
);
AWS S3
Instance profile-based authentication
-
If you use Hive metastore in your Hive cluster, run a command like below:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"aws.s3.use_instance_profile" = "true",
"aws.s3.region" = "us-west-2"
); -
If you use AWS Glue in your Amazon EMR Hive cluster, run a command like below:
CREATE EXTERNAL CATALOG hive_catalog_glue
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "glue",
"aws.glue.use_instance_profile" = "true",
"aws.glue.region" = "us-west-2",
"aws.s3.use_instance_profile" = "true",
"aws.s3.region" = "us-west-2"
);
Assumed role-based authentication
-
If you use Hive metastore in your Hive cluster, run a command like below:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"aws.s3.use_instance_profile" = "true",
"aws.s3.iam_role_arn" = "arn:aws:iam::081976408565:role/test_s3_role",
"aws.s3.region" = "us-west-2"
); -
If you use AWS Glue in your Amazon EMR Hive cluster, run a command like below:
CREATE EXTERNAL CATALOG hive_catalog_glue
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "glue",
"aws.glue.use_instance_profile" = "true",
"aws.glue.iam_role_arn" = "arn:aws:iam::081976408565:role/test_glue_role",
"aws.glue.region" = "us-west-2",
"aws.s3.use_instance_profile" = "true",
"aws.s3.iam_role_arn" = "arn:aws:iam::081976408565:role/test_s3_role",
"aws.s3.region" = "us-west-2"
);
IAM user-based authentication
-
If you use Hive metastore in your Hive cluster, run a command like below:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"aws.s3.use_instance_profile" = "false",
"aws.s3.access_key" = "<iam_user_access_key>",
"aws.s3.secret_key" = "<iam_user_access_key>",
"aws.s3.region" = "us-west-2"
); -
If you use AWS Glue in your Amazon EMR Hive cluster, run a command like below:
CREATE EXTERNAL CATALOG hive_catalog_glue
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "glue",
"aws.glue.use_instance_profile" = "false",
"aws.glue.access_key" = "<iam_user_access_key>",
"aws.glue.secret_key" = "<iam_user_secret_key>",
"aws.glue.region" = "us-west-2",
"aws.s3.use_instance_profile" = "false",
"aws.s3.access_key" = "<iam_user_access_key>",
"aws.s3.secret_key" = "<iam_user_secret_key>",
"aws.s3.region" = "us-west-2"
);
S3-compatible storage system
Use MinIO as an example. Run a command like below:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"aws.s3.enable_ssl" = "true",
"aws.s3.enable_path_style_access" = "true",
"aws.s3.endpoint" = "<s3_endpoint>",
"aws.s3.access_key" = "<iam_user_access_key>",
"aws.s3.secret_key" = "<iam_user_secret_key>"
);
Microsoft Azure Storage
Azure Blob Storage
-
If you choose the Shared Key authentication method, run a command like below:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"azure.blob.storage_account" = "<blob_storage_account_name>",
"azure.blob.shared_key" = "<blob_storage_account_shared_key>"
); -
If you choose the SAS Token authentication method, run a command like below:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"azure.blob.storage_account" = "<blob_storage_account_name>",
"azure.blob.container" = "<blob_container_name>",
"azure.blob.sas_token" = "<blob_storage_account_SAS_token>"
);
Azure Data Lake Storage Gen1
-
If you choose the Managed Service Identity authentication method, run a command like below:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"azure.adls1.use_managed_service_identity" = "true"
); -
If you choose the Service Principal authentication method, run a command like below:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"azure.adls1.oauth2_client_id" = "<application_client_id>",
"azure.adls1.oauth2_credential" = "<application_client_credential>",
"azure.adls1.oauth2_endpoint" = "<OAuth_2.0_authorization_endpoint_v2>"
);
Azure Data Lake Storage Gen2
-
If you choose the Managed Identity authentication method, run a command like below:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"azure.adls2.oauth2_use_managed_identity" = "true",
"azure.adls2.oauth2_tenant_id" = "<service_principal_tenant_id>",
"azure.adls2.oauth2_client_id" = "<service_client_id>"
); -
If you choose the Shared Key authentication method, run a command like below:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"azure.adls2.storage_account" = "<storage_account_name>",
"azure.adls2.shared_key" = "<shared_key>"
); -
If you choose the Service Principal authentication method, run a command like below:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"azure.adls2.oauth2_client_id" = "<service_client_id>",
"azure.adls2.oauth2_client_secret" = "<service_principal_client_secret>",
"azure.adls2.oauth2_client_endpoint" = "<service_principal_client_endpoint>"
);
Google GCS
-
If you choose the VM-based authentication method, run a command like below:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"gcp.gcs.use_compute_engine_service_account" = "true"
); -
If you choose the service account-based authentication method, run a command like below:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"gcp.gcs.service_account_email" = "<google_service_account_email>",
"gcp.gcs.service_account_private_key_id" = "<google_service_private_key_id>",
"gcp.gcs.service_account_private_key" = "<google_service_private_key>"
); -
If you choose the impersonation-based authentication method:
-
If you make a VM instance impersonate a service account, run a command like below:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"gcp.gcs.use_compute_engine_service_account" = "true",
"gcp.gcs.impersonation_service_account" = "<assumed_google_service_account_email>"
); -
If you make a service account impersonate another service account, run a command like below:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"gcp.gcs.service_account_email" = "<google_service_account_email>",
"gcp.gcs.service_account_private_key_id" = "<meta_google_service_account_email>",
"gcp.gcs.service_account_private_key" = "<meta_google_service_account_email>",
"gcp.gcs.impersonation_service_account" = "<data_google_service_account_email>"
);
-
View Hive catalogs
You can use SHOW CATALOGS to query all catalogs in the current StarRocks cluster:
SHOW CATALOGS;
You can also use SHOW CREATE CATALOG to query the creation statement of an external catalog. The following example queries the creation statement of a Hive catalog named hive_catalog_glue:
SHOW CREATE CATALOG hive_catalog_glue;
Switch to a Hive Catalog and a database in it
You can use one of the following methods to switch to a Hive catalog and a database in it:
-
Use SET CATALOG to specify a Hive catalog in the current session, and then use USE to specify an active database:
-- Switch to a specified catalog in the current session:
SET CATALOG <catalog_name>
-- Specify the active database in the current session:
USE <db_name> -
Directly use USE to switch to a Hive catalog and a database in it:
USE <catalog_name>.<db_name>
Drop a Hive catalog
You can use DROP CATALOG to drop an external catalog.
The following example drops a Hive catalog named hive_catalog_glue:
DROP Catalog hive_catalog_glue;
View the schema of a Hive table
You can use one of the following syntaxes to view the schema of a Hive table:
-
View schema
DESC[RIBE] <catalog_name>.<database_name>.<table_name> -
View schema and location from the CREATE statement
SHOW CREATE TABLE <catalog_name>.<database_name>.<table_name>
Query a Hive table
-
Use SHOW DATABASES to view the databases in your Hive cluster:
SHOW DATABASES FROM <catalog_name> -
Use SELECT to query the destination table in the specified database:
SELECT count(*) FROM <table_name> LIMIT 10
Load data from Hive
Suppose you have an OLAP table named olap_tbl, you can transform and load data like below:
INSERT INTO default_catalog.olap_db.olap_tbl SELECT * FROM hive_table
Grant privileges on Hive tables and views
You can use the GRANT statement to grant the privileges on all tables and views within a Hive catalog to a specific role. The command syntax is as follows:
GRANT SELECT ON ALL TABLES IN ALL DATABASES TO ROLE <role_name>
For example, use the following commands to create a role named hive_role_table, switch to the Hive catalog hive_catalog, and then grant the role hive_role_table the privilege to query all tables and views within the Hive catalog hive_catalog:
-- Create a role named hive_role_table.
CREATE ROLE hive_role_table;
-- Switch to the Hive catalog hive_catalog.
SET CATALOG hive_catalog;
-- Grant the role hive_role_table the privilege to query all tables and views within the Hive catalog hive_catalog.
GRANT SELECT ON ALL TABLES IN ALL DATABASES TO ROLE hive_role_table;
Create a Hive database
Similar to the internal catalog of StarRocks, if you have the CREATE DATABASE privilege on a Hive catalog, you can use the CREATE DATABASE statement to create a database in that Hive catalog. This feature is supported from v3.2 onwards.
You can grant and revoke privileges by using GRANT and REVOKE.
Switch to a Hive catalog, and then use the following statement to create a Hive database in that catalog:
CREATE DATABASE <database_name>
[PROPERTIES ("location" = "<prefix>://<path_to_database>/<database_name.db>")]
The location parameter specifies the file path in which you want to create the database, which can be in either HDFS or cloud storage.
- When you use Hive metastore as the metastore of your Hive cluster, the
locationparameter defaults to<warehouse_location>/<database_name.db>, which is supported by Hive metastore if you do not specify that parameter at database creation. - When you use AWS Glue as the metastore of your Hive cluster, the
locationparameter does not have a default value, and therefore you must specify that parameter at database creation.
The prefix varies based on the storage system you use:
| Storage system | Prefix value |
|---|---|
| HDFS | hdfs |
| Google GCS | gs |
| Azure Blob Storage |
|
| Azure Data Lake Storage Gen1 | adl |
| Azure Data Lake Storage Gen2 |
|
| AWS S3 or other S3-compatible storage (for example, MinIO) | s3 |
Drop a Hive database
Similar to the internal databases of StarRocks, if you have the DROP privilege on a Hive database, you can use the DROP DATABASE statement to drop that Hive database. This feature is supported from v3.2 onwards. You can only drop empty databases.
When you drop a Hive database, the database's file path on your HDFS cluster or cloud storage will not be dropped along with the database.
Switch to a Hive catalog, and then use the following statement to drop a Hive database in that catalog:
DROP DATABASE <database_name>
Create a Hive table
Similar to the internal databases of StarRocks, if you have the CREATE TABLE privilege on a Hive database, you can use the CREATE TABLE, CREATE TABLE AS SELECT (CTAS), or CREATE TABLE LIKE statement to create a managed table in that Hive database.
This feature is supported since v3.2.
Switch to a Hive catalog and a database in it, and then use the following syntax to create a Hive managed table in that database.
Syntax
CREATE TABLE [IF NOT EXISTS] [database.]table_name
(column_definition1[, column_definition2, ...
partition_column_definition1,partition_column_definition2...])
[partition_desc]
[PROPERTIES ("key" = "value", ...)]
[AS SELECT query]
[LIKE [database.]<source_table_name>]
Parameters
column_definition
The syntax of column_definition is as follows:
col_name col_type [COMMENT 'comment']
The following table describes the parameters.
| Parameter | Description |
|---|---|
| col_name | The name of the column. |
| col_type | The data type of the column. The following data types are supported: TINYINT, SMALLINT, INT, BIGINT, FLOAT, DOUBLE, DECIMAL, DATE, DATETIME, CHAR, VARCHAR[(length)], ARRAY, MAP, and STRUCT. The LARGEINT, HLL, and BITMAP data types are not supported. |
NOTICE
All non-partition columns must use
NULLas the default value. This means that you must specifyDEFAULT "NULL"for each of the non-partition columns in the table creation statement. Additionally, partition columns must be defined following non-partition columns and cannot useNULLas the default value.
partition_desc
The syntax of partition_desc is as follows:
PARTITION BY (par_col1[, par_col2...])
Currently StarRocks only supports identity transforms, which means that StarRocks creates a partition for each unique partition value.
NOTICE
Partition columns must be defined following non-partition columns. Partition columns support all data types excluding FLOAT, DOUBLE, DECIMAL, and DATETIME and cannot use
NULLas the default value. Additionally, the sequence of the partition columns declared inpartition_descmust be consistent with the sequence of the columns defined incolumn_definition.
PROPERTIES
You can specify the table attributes in the "key" = "value" format in properties.
The following table describes a few key properties.
| Property | Description |
|---|---|
| location | The file path in which you want to create the managed table. When you use HMS as metastore, you do not need to specify the location parameter, because StarRocks will create the table in the default file path of the current Hive catalog. When you use AWS Glue as metadata service:
|
| file_format | The file format of the managed table. Only the Parquet format is supported. Default value: parquet. |
| compression_codec | The compression algorithm used for the managed table. The supported compression algorithms are SNAPPY, GZIP, ZSTD, and LZ4. Default value: gzip. This property is deprecated in v3.2.3, since which version the compression algorithm used for sinking data to Hive tables is uniformly controlled by the session variable connector_sink_compression_codec. |
Examples
-
Create a non-partitioned table named
unpartition_tbl. The table consists of two columns,idandscore, as shown below:CREATE TABLE unpartition_tbl
(
id int,
score double
); -
Create a partitioned table named
partition_tbl_1. The table consists of three columns,action,id, anddt, of whichidanddtare defined as partition columns, as shown below:CREATE TABLE partition_tbl_1
(
action varchar(20),
id int,
dt date
)
PARTITION BY (id,dt); -
Query an existing table named
partition_tbl_1, and create a partitioned table namedpartition_tbl_2based on the query result ofpartition_tbl_1. Forpartition_tbl_2,idanddtare defined as partition columns, as shown below:CREATE TABLE partition_tbl_2
PARTITION BY (k1, k2)
AS SELECT * from partition_tbl_1;
Sink data to a Hive table
Similar to the internal tables of StarRocks, if you have the INSERT privilege on a Hive table (which can be a managed table or an external table), you can use the INSERT statement to sink the data of a StarRocks table to that Hive table (currently only Parquet-formatted Hive tables are supported). This feature is supported from v3.2 onwards. Sinking data to external tables is disabled by default. To sink data to external tables, you must set the system variable ENABLE_WRITE_HIVE_EXTERNAL_TABLE to true.
Switch to a Hive catalog and a database in it, and then use the following syntax to sink the data of StarRocks table to a Parquet-formatted Hive table in that database.
Syntax
INSERT {INTO | OVERWRITE} <table_name>
[ (column_name [, ...]) ]
{ VALUES ( { expression | DEFAULT } [, ...] ) [, ...] | query }
-- If you want to sink data to specified partitions, use the following syntax:
INSERT {INTO | OVERWRITE} <table_name>
PARTITION (par_col1=<value> [, par_col2=<value>...])
{ VALUES ( { expression | DEFAULT } [, ...] ) [, ...] | query }
NOTICE
Partition columns do not allow
NULLvalues. Therefore, you must make sure that no empty values are loaded into the partition columns of the Hive table.
Parameters
| Parameter | Description |
|---|---|
| INTO | To append the data of the StarRocks table to the Hive table. |
| OVERWRITE | To overwrite the existing data of the Hive table with the data of the StarRocks table. |
| column_name | The name of the destination column to which you want to load data. You can specify one or more columns. If you specify multiple columns, separate them with commas (,). You can only specify columns that actually exist in the Hive table, and the destination columns that you specify must include the partition columns of the Hive table. The destination columns you specify are mapped one on one in sequence to the columns of the StarRocks table, regardless of what the destination column names are. If no destination columns are specified, the data is loaded into all columns of the Hive table. If a non-partition column of the StarRocks table cannot be mapped to any column of the Hive table, StarRocks writes the default value NULL to the Hive table column. If the INSERT statement contains a query statement whose returned column types differ from the data types of the destination columns, StarRocks performs an implicit conversion on the mismatched columns. If the conversion fails, a syntax parsing error will be returned. |
| expression | Expression that assigns values to the destination column. |
| DEFAULT | Assigns a default value to the destination column. |
| query | Query statement whose result will be loaded into the Hive table. It can be any SQL statement supported by StarRocks. |
| PARTITION | The partitions into which you want to load data. You must specify all partition columns of the Hive table in this property. The partition columns that you specify in this property can be in a different sequence than the partition columns that you have defined in the table creation statement. If you specify this property, you cannot specify the column_name property. |
Examples
-
Insert three data rows into the
partition_tbl_1table:INSERT INTO partition_tbl_1
VALUES
("buy", 1, "2023-09-01"),
("sell", 2, "2023-09-02"),
("buy", 3, "2023-09-03"); -
Insert the result of a SELECT query, which contains simple computations, into the
partition_tbl_1table:INSERT INTO partition_tbl_1 (id, action, dt) SELECT 1+1, 'buy', '2023-09-03'; -
Insert the result of a SELECT query, which reads data from the
partition_tbl_1table, into the same table:INSERT INTO partition_tbl_1 SELECT 'buy', 1, date_add(dt, INTERVAL 2 DAY)
FROM partition_tbl_1
WHERE id=1; -
Insert the result of a SELECT query into the partitions that meet two conditions,
dt='2023-09-01'andid=1, of thepartition_tbl_2table:INSERT INTO partition_tbl_2 SELECT 'order', 1, '2023-09-01';Or
INSERT INTO partition_tbl_2 partition(dt='2023-09-01',id=1) SELECT 'order'; -
Overwrite all
actioncolumn values in the partitions that meet two conditions,dt='2023-09-01'andid=1, of thepartition_tbl_1table withclose:INSERT OVERWRITE partition_tbl_1 SELECT 'close', 1, '2023-09-01';Or
INSERT OVERWRITE partition_tbl_1 partition(dt='2023-09-01',id=1) SELECT 'close';
Drop a Hive table
Similar to the internal tables of StarRocks, if you have the DROP privilege on a Hive table, you can use the DROP TABLE statement to drop that Hive table. This feature is supported from v3.1 onwards. Note that currently StarRocks supports dropping only managed tables of Hive.
When you drop a Hive table, you must specify the FORCE keyword in the DROP TABLE statement. After the operation is complete, the table's file path is retained, but the table's data on your HDFS cluster or cloud storage is all dropped along with the table. Exercise caution when you perform this operation to drop a Hive table.
Switch to a Hive catalog and a database in it, and then use the following statement to drop a Hive table in that database.
DROP TABLE <table_name> FORCE
Manually or automatically update metadata cache
Manual update
By default, StarRocks caches the metadata of Hive and automatically updates the metadata in asynchronous mode to deliver better performance. Additionally, after some schema changes or table updates are made on a Hive table, you can also use REFRESH EXTERNAL TABLE to manually update its metadata, thereby ensuring that StarRocks can obtain up-to-date metadata at its earliest opportunity and generate appropriate execution plans:
REFRESH EXTERNAL TABLE <table_name> [PARTITION ('partition_name', ...)]
You need to manually update metadata in the following situations:
-
A data file in an existing partition is changed, for example, by running the
INSERT OVERWRITE ... PARTITION ...command. -
Schema changes are made on a Hive table.
-
An existing Hive table is deleted by using the DROP statement, and a new Hive table with the same name as the deleted Hive table is created.
-
You have specified
"enable_cache_list_names" = "true"inPROPERTIESat the creation of your Hive catalog, and you want to query new partitions that you just created on your Hive cluster.noteFrom v2.5.5 onwards, StarRocks provides the periodic Hive metadata cache refresh feature. For more information, see the below "Periodically refresh metadata cache" section of this topic. After you enable this feature, StarRocks refreshes your Hive metadata cache every 10 minutes by default. Therefore, manual updates are not needed in most cases. You need to perform a manual update only when you want to query new partitions immediately after the new partitions are created on your Hive cluster.
Note that the REFRESH EXTERNAL TABLE refreshes only the tables and partitions cached in your FEs.
Periodically refresh metadata cache
From v2.5.5 onwards, StarRocks can periodically refresh the cached metadata of the frequently accessed Hive catalogs to perceive data changes. You can configure the Hive metadata cache refresh through the following FE parameters:
| Configuration item | Default | Description |
|---|---|---|
| enable_background_refresh_connector_metadata | true in v3.0false in v2.5 | Whether to enable the periodic Hive metadata cache refresh. After it is enabled, StarRocks polls the metastore (Hive Metastore or AWS Glue) of your Hive cluster, and refreshes the cached metadata of the frequently accessed Hive catalogs to perceive data changes. true indicates to enable the Hive metadata cache refresh, and false indicates to disable it. This item is an FE dynamic parameter. You can modify it using the ADMIN SET FRONTEND CONFIG command. |
| background_refresh_metadata_interval_millis | 600000 (10 minutes) | The interval between two consecutive Hive metadata cache refreshes. Unit: millisecond. This item is an FE dynamic parameter. You can modify it using the ADMIN SET FRONTEND CONFIG command. |
| background_refresh_metadata_time_secs_since_last_access_secs | 86400 (24 hours) | The expiration time of a Hive metadata cache refresh task. For the Hive catalog that has been accessed, if it has not been accessed for more than the specified time, StarRocks stops refreshing its cached metadata. For the Hive catalog that has not been accessed, StarRocks will not refresh its cached metadata. Unit: second. This item is an FE dynamic parameter. You can modify it using the ADMIN SET FRONTEND CONFIG command. |
Using the periodic Hive metadata cache refresh feature and the metadata automatic asynchronous update policy together significantly accelerates data access, reduces the read load from external data sources, and improves query performance.
Appendix: Understand metadata automatic asynchronous update
Automatic asynchronous update is the default policy that StarRocks uses to update the metadata in Hive catalogs.
By default (namely, when the enable_metastore_cache and enable_remote_file_cache parameters are both set to true), if a query hits a partition of a Hive table, StarRocks automatically caches the metadata of the partition and the metadata of the underlying data files of the partition. The cached metadata is updated by using the lazy update policy.
For example, there is a Hive table named table2, which has four partitions: p1, p2, p3, and p4. A query hits p1, and StarRocks caches the metadata of p1 and the metadata of the underlying data files of p1. Assume that the default time intervals to update and discard the cached metadata are as follows:
- The time interval (specified by the
metastore_cache_refresh_interval_secparameter) to asynchronously update the cached metadata ofp1is 2 hours. - The time interval (specified by the
remote_file_cache_refresh_interval_secparameter) to asynchronously update the cached metadata of the underlying data files ofp1is 60 seconds. - The time interval (specified by the
metastore_cache_ttl_secparameter) to automatically discard the cached metadata ofp1is 24 hours. - The time interval (specified by the
remote_file_cache_ttl_secparameter) to automatically discard the cached metadata of the underlying data files ofp1is 36 hours.
The following figure shows the time intervals on a timeline for easier understanding.
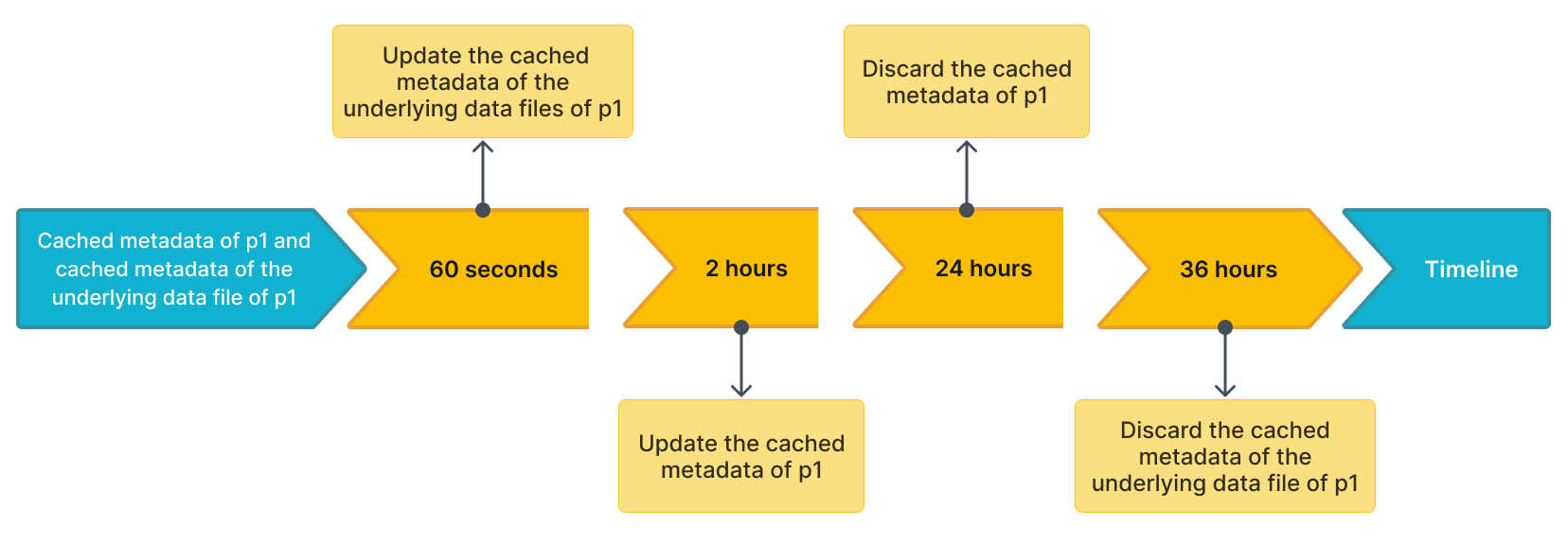
Then StarRocks updates or discards the metadata in compliance with the following rules:
- If another query hits
p1again and the current time from the last update is less than 60 seconds, StarRocks does not update the cached metadata ofp1or the cached metadata of the underlying data files ofp1. - If another query hits
p1again and the current time from the last update is more than 60 seconds, StarRocks updates the cached metadata of the underlying data files ofp1. - If another query hits
p1again and the current time from the last update is more than 2 hours, StarRocks updates the cached metadata ofp1. - If
p1has not been accessed within 24 hours from the last update, StarRocks discards the cached metadata ofp1. The metadata will be cached at the next query. - If
p1has not been accessed within 36 hours from the last update, StarRocks discards the cached metadata of the underlying data files ofp1. The metadata will be cached at the next query.
