Overview of data loading
Data loading is the process of cleansing and transforming raw data from various data sources based on your business requirements and loading the resulting data into StarRocks to facilitate blazing-fast data analytics.
You can load data into StarRocks by running load jobs. Each load job has a unique label that is specified by the user or automatically generated by StarRocks to identify the job. Each label can be used only for one load job. After a load job is complete, its label cannot be reused for any other load jobs. Only the labels of failed load jobs can be reused. This mechanism helps ensure that the data associated with a specific label can be loaded only once, thus implementing At-Most-Once semantics.
All the loading methods provided by StarRocks can guarantee atomicity. Atomicity means that the qualified data within a load job must be all successfully loaded or none of the qualified data is successfully loaded. It never happens that some of the qualified data is loaded while the other data is not. Note that the qualified data does not include the data that is filtered out due to quality issues such as data type conversion errors.
StarRocks supports two communication protocols that can be used to submit load jobs: MySQL and HTTP. For more information about the protocol supported by each loading method, see the Loading methods section of this topic.
You can load data into StarRocks tables only as a user who has the INSERT privilege on those StarRocks tables. If you do not have the INSERT privilege, follow the instructions provided in GRANT to grant the INSERT privilege to the user that you use to connect to your StarRocks cluster.
Supported data types
StarRocks supports loading data of all data types. You only need to take note of the limits on the loading of a few specific data types. For more information, see Data types.
Loading modes
StarRocks supports two loading modes: synchronous loading mode and asynchronous loading mode.
NOTE
If you load data by using external programs, you must choose a loading mode that best suits your business requirements before you decide the loading method of your choice.
Synchronous loading
In synchronous loading mode, after you submit a load job, StarRocks synchronously runs the job to load data, and returns the result of the job after the job finishes. You can check whether the job is successful based on the job result.
StarRocks provides two loading methods that support synchronous loading: Stream Load and INSERT.
The process of synchronous loading is as follows:
-
Create a load job.
-
View the job result returned by StarRocks.
-
Check whether the job is successful based on the job result. If the job result indicates a load failure, you can retry the job.
Asynchronous loading
In asynchronous loading mode, after you submit a load job, StarRocks immediately returns the job creation result.
-
If the result indicates a job creation success, StarRocks asynchronously runs the job. However, that does not mean that the data has been successfully loaded. You must use statements or commands to check the status of the job. Then, you can determine whether the data is successfully loaded based on the job status.
-
If the result indicates a job creation failure, you can determine whether you need to retry the job based on the failure information.
StarRocks provides three loading methods that support asynchronous loading: Broker Load, Routine Load, and Spark Load.
The process of asynchronous loading is as follows:
-
Create a load job.
-
View the job creation result returned by StarRocks and determine whether the job is successfully created. a. If the job creation succeeds, go to Step 3. b. If the job creation fails, return to Step 1.
-
Use statements or commands to check the status of the job until the job status shows FINISHED or CANCELLED.
The workflow of a Broker Load or Spark Load job consists of five stages, as shown in the following figure.
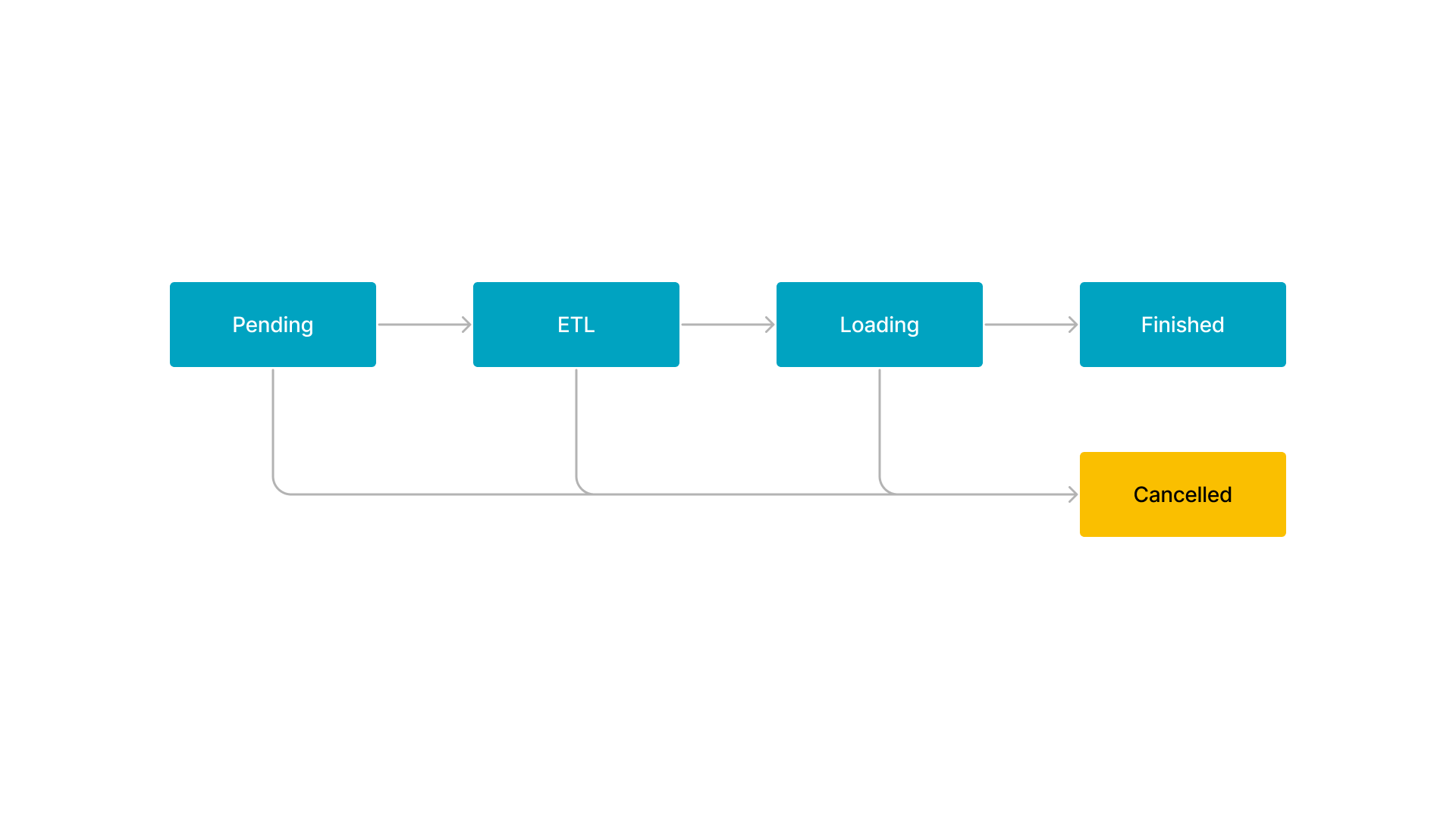
The workflow is described as follows:
-
PENDING
The job is in queue waiting to be scheduled by an FE.
-
ETL
The FE pre-processes the data, including cleansing, partitioning, sorting, and aggregation.
NOTE
If the job is a Broker Load job, this stage is directly finished.
-
LOADING
The FE cleanses and transforms the data, and then sends the data to the BEs. After all data is loaded, the data is in queue waiting to take effect. At this time, the status of the job remains LOADING.
-
FINISHED
When all data takes effect, the status of the job becomes FINISHED. At this time, the data can be queried. FINISHED is a final job state.
-
CANCELLED
Before the status of the job becomes FINISHED, you can cancel the job at any time. Additionally, StarRocks can automatically cancel the job in case of load errors. After the job is canceled, the status of the job becomes CANCELLED. CANCELLED is also a final job state.
The workflow of a Routine job is described as follows:
-
The job is submitted to an FE from a MySQL client.
-
The FE splits the job into multiple tasks. Each task is engineered to load data from multiple partitions.
-
The FE distributes the tasks to specified BEs.
-
The BEs execute the tasks, and report to the FE after they finish the tasks.
-
The FE generates subsequent tasks, retries failed tasks if there are any, or suspends task scheduling based on the reports from the BEs.
Loading methods
StarRocks provides five loading methods to help you load data in various business scenarios: Stream Load, Broker Load, Routine Load, Spark Load, and INSERT.
| Loading method | Data source | Business scenario | Data volume per load job | Data file format | Loading mode | Protocol |
|---|---|---|---|---|---|---|
| Stream Load |
| Load data files from local file systems or load data streams by using programs. | 10 GB or less |
| Synchronous | HTTP |
| Broker Load |
| Load data from HDFS or cloud storage. | Dozens of GB to hundreds of GB |
| Asynchronous | MySQL |
| Routine Load | Apache Kafka® | Load data in real time from Kafka. | MBs to GBs of data as mini-batches |
| Asynchronous | MySQL |
| Spark Load |
|
| Dozens of GB to TBs |
| Asynchronous | MySQL |
| INSERT INTO SELECT |
When you load data from AWS S3, only Parquet-formatted or ORC-formatted files are supported. |
| Not fixed (The data volume varies based on the memory size.) | StarRocks tables | Synchronous | MySQL |
| INSERT INTO VALUES |
|
| In small quantities | SQL | Synchronous | MySQL |
You can determine the loading method of your choice based on your business scenario, data volume, data source, data file format, and loading frequency. Additionally, take note of the following points when you select a loading method:
-
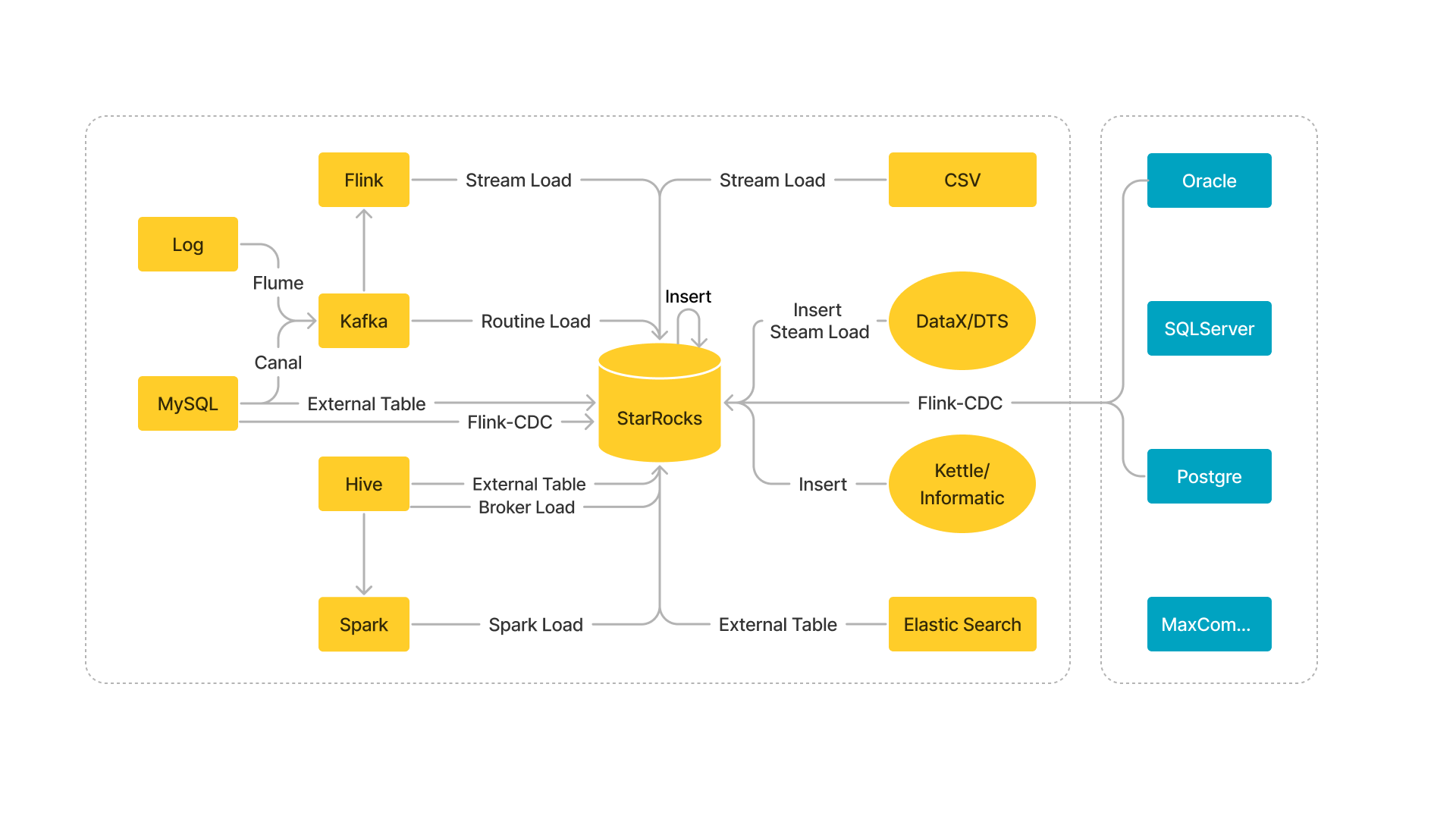
When you load data from Kafka, we recommend that you use Routine Load. However, if the data requires multi-table joins and extract, transform and load (ETL) operations, you can use Apache Flink® to read and pre-process the data from Kafka and then use flink-connector-starrocks to load the data into StarRocks.
-
When you load data from Hive, Iceberg, Hudi, or Delta Lake, we recommend that you create a Hive catalog, Iceberg catalog, Hudi Catalog, or Delta Lake Catalog and then use INSERT to load the data.
-
When you load data from another StarRocks cluster or from an Elasticsearch cluster, we recommend that you create a StarRocks external table or an Elasticsearch external table and then use INSERT to load the data.
NOTICE
StarRocks external tables only support data writes. They do not support data reads.
-
When you load data from MySQL databases, we recommend that you create a MySQL external table and then use INSERT to load the data. If you want to load data in real time, we recommend that you load the data by following the instructions provided in Realtime synchronization from MySQL.
-
When you load data from other data sources such as Oracle, PostgreSQL, and SQL Server, we recommend that you create a JDBC external table and then use INSERT to load the data.
The following figure provides an overview of various data sources supported by StarRocks and the loading methods that you can use to load data from these data sources.
Memory limits
StarRocks provides parameters for you to limit the memory usage for each load job, thereby reducing memory consumption, especially in high concurrency scenarios. However, do not specify an excessively low memory usage limit. If the memory usage limit is excessively low, data may be frequently flushed from memory to disk because the memory usage for load jobs reaches the specified limit. We recommend that you specify a proper memory usage limit based on your business scenario.
The parameters that are used to limit memory usage vary for each loading method. For more information, see Stream Load, Broker Load, Routine Load, Spark Load, and INSERT. Note that a load job usually runs on multiple BEs. Therefore, the parameters limit the memory usage of each load job on each involved BE rather than the total memory usage of the load job on all involved BEs.
StarRocks also provides parameters for you to limit the total memory usage of all load jobs that run on each individual BE. For more information, see the "System configurations" section of this topic.
Usage notes
Automatically fill in the destination column while loading
When you load data, you can choose not to load the data from a specific field of your data file:
-
If you have specified the
DEFAULTkeyword for the destination StarRocks table column mapping the source field when you create the StarRocks table, StarRocks automatically fills the specified default value into the destination column.Stream Load, Broker Load, Routine Load, and INSERT supports
DEFAULT current_timestamp,DEFAULT <default_value>, andDEFAULT (<expression>). Spark Load supports onlyDEFAULT current_timestampandDEFAULT <default_value>.NOTE
DEFAULT (<expression>)supports only the functionsuuid()anduuid_numeric(). -
If you did not specify the
DEFAULTkeyword for the destination StarRocks table column mapping the source field when you create the StarRocks table, StarRocks automatically fillsNULLinto the destination column.NOTE
If the destination column is defined as
NOT NULL, the load fails.For Stream Load, Broker Load, Routine Load, and Spark Load, you can also specify the value you want to fill in the destination column by using the parameter that is used to specify column mapping.
For information about the usage of NOT NULL and DEFAULT, see CREATE TABLE.
Set write quorum for data loading
If your StarRocks cluster has multiple data replicas, you can set different write quorum for tables, that is, how many replicas are required to return loading success before StarRocks can determine the loading task is successful. You can specify write quorum by adding the property write_quorum when you CREATE TABLE, or add this property to an existing table using ALTER TABLE. This property is supported from v2.5.
System configurations
This section describes some parameter configurations that are applicable to all of the loading methods provided by StarRocks.
FE configurations
You can configure the following parameters in the configuration file fe.conf of each FE:
-
max_load_timeout_secondandmin_load_timeout_secondThese parameters specify the maximum timeout period and minimum timeout period of each load job. The timeout periods are measured in seconds. The default maximum timeout period spans 3 days, and the default minimum timeout period spans 1 second. The maximum timeout period and minimum timeout period that you specify must fall within the range of 1 second to 3 days. These parameters are valid for both synchronous load jobs and asynchronous load jobs.
-
desired_max_waiting_jobsThis parameter specifies the maximum number of load jobs that can be held waiting in queue. The default value is 1024 (100 in v2.4 and earlier, and 1024 in v2.5 and later). When the number of load jobs in the PENDING state on an FE reaches the maximum number that you specify, the FE rejects new load requests. This parameter is valid only for asynchronous load jobs.
-
max_running_txn_num_per_dbThis parameter specifies the maximum number of ongoing load transactions that are allowed in each database of your StarRocks cluster. A load job can contain one or more transactions. The default value is 100. When the number of load transactions running in a database reaches the maximum number that you specify, the subsequent load jobs that you submit are not scheduled. In this situation, if you submit a synchronous load job, the job is rejected. If you submit an asynchronous load job, the job is held waiting in queue.
NOTE
StarRocks counts all load jobs together and does not distinguish between synchronous load jobs and asynchronous load jobs.
-
label_keep_max_secondThis parameter specifies the retention period of the history records for load jobs that have finished and are in the FINISHED or CANCELLED state. The default retention period spans 3 days. This parameter is valid for both synchronous load jobs and asynchronous load jobs.
BE configurations
You can configure the following parameters in the configuration file be.conf of each BE:
-
write_buffer_sizeThis parameter specifies the maximum memory block size. The default size is 100 MB. The loaded data is first written to a memory block on the BE. When the amount of data that is loaded reaches the maximum memory block size that you specify, the data is flushed to disk. You must specify a proper maximum memory block size based on your business scenario.
- If the maximum memory block size is exceedingly small, a large number of small files may be generated on the BE. In this case, query performance degrades. You can increase the maximum memory block size to reduce the number of files generated.
- If the maximum memory block size is exceedingly large, remote procedure calls (RPCs) may time out. In this case, you can adjust the value of this parameter based on your business needs.
-
streaming_load_rpc_max_alive_time_secThe waiting timeout period for each Writer process. The default value is 600 seconds. During the data loading process, StarRocks starts a Writer process to receive data from and write data to each tablet. If a Writer process does not receive any data within the waiting timeout period that you specify, StarRocks stops the Writer process. When your StarRocks cluster processes data at low speeds, a Writer process may not receive the next batch of data within a long period of time and therefore reports a "TabletWriter add batch with unknown id" error. In this case, you can increase the value of this parameter.
-
load_process_max_memory_limit_bytesandload_process_max_memory_limit_percentThese parameters specify the maximum amount of memory that can be consumed for all load jobs on each individual BE. StarRocks identifies the smaller memory consumption among the values of the two parameters as the final memory consumption that is allowed.
-
load_process_max_memory_limit_bytes: specifies the maximum memory size. The default maximum memory size is 100 GB. -
load_process_max_memory_limit_percent: specifies the maximum memory usage. The default value is 30%. This parameter differs from themem_limitparameter. Themem_limitparameter specifies the total maximum memory usage of your StarRocks cluster, and the default value is 90% x 90%.If the memory capacity of the machine on which the BE resides is M, the maximum amount of memory that can be consumed for load jobs is calculated as follows:
M x 90% x 90% x 30%.
-
System variable configurations
You can configure the following system variable:
-
query_timeoutThe query timeout duration. Unit: seconds. Value range:
1to259200. Default value:300. This variable will act on all query statements in the current connection, as well as INSERT statements.
Troubleshooting
For more information, see FAQ about data loading.
