Data distribution
When you create a table, you must specify the data distribution method by configuring the number of partitions and the number of tablets in a table. An appropriate data distribution method helps evenly distribute data across the nodes of your StarRocks cluster, reduces table scans, makes full use of the concurrency of the cluster, thereby improving query performance.
Basic concepts
Before you dive into the details of designing and managing data distribution, familiarize yourself with the following concepts:
-
Partitioning
Partitioning divides a table into multiple segments called partitions based on the partitioning column you specified. You can set a storage strategy for partitions, including the number of replicas, strategy of storing hot or cold data, and storage medium. StarRocks allows you to use multiple storage mediums within a cluster. For example, you can store the latest data on solid-state drives (SSD) to improve query performance, and historical data on SATA hard drives to reduce storage costs.
-
Bucketing
Bucketing divides a partition into multiple more manageable parts called tablets, which is the smallest unit of storage that you can use and allocate. StarRocks uses a hash algorithm to bucket data. Data with the same hash value of the bucketing column is distributed to the same tablet. StarRocks creates multiple replicas (three by default) for each tablet to prevent data loss. These replicas are managed by a separate local storage engine. You must specify the bucketing column when you create a table.
Partitioning methods
Modern distributed database systems generally use four basic partitioning methods: round-robin, range, list, and hash.
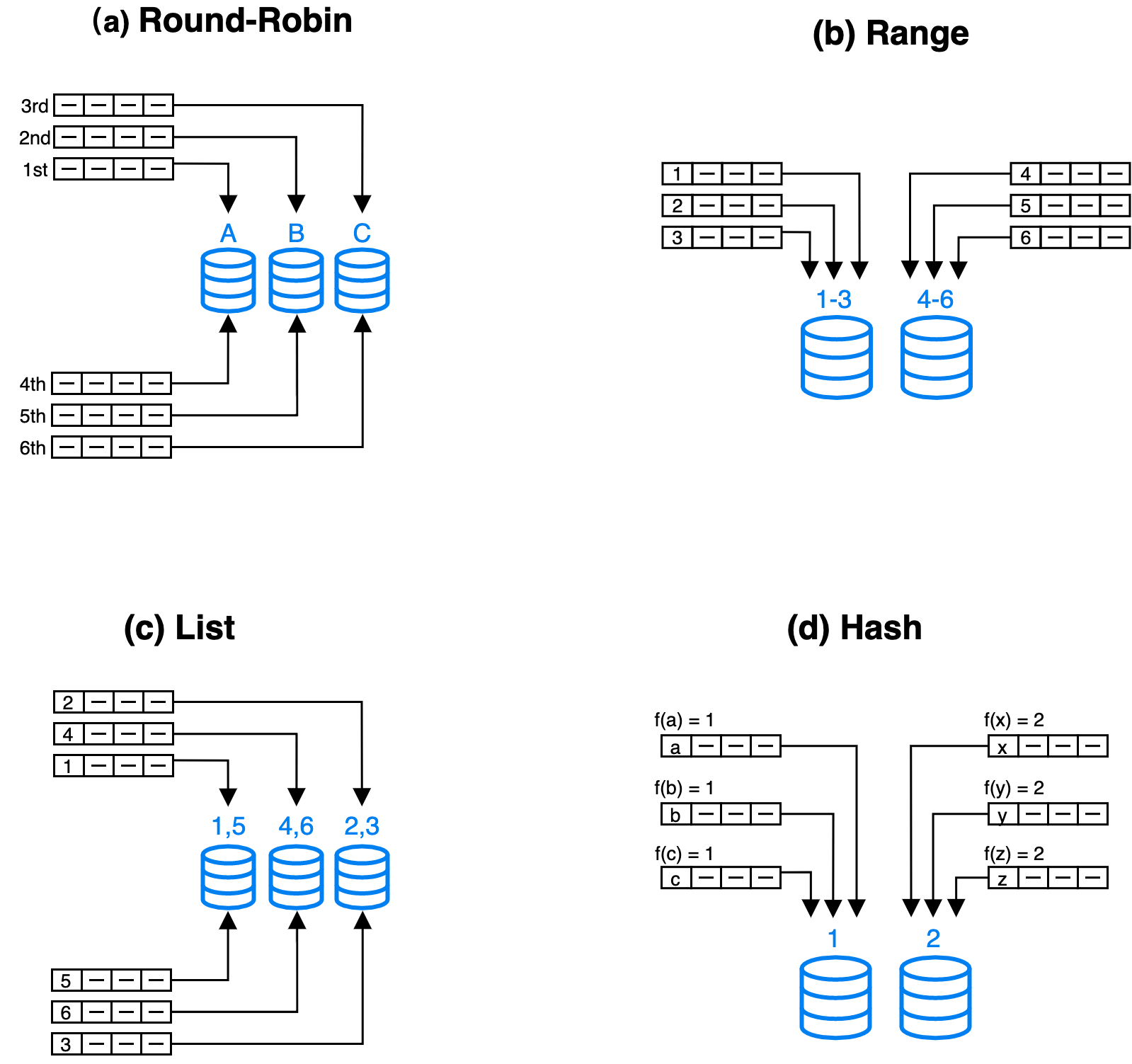
- Round-robin: distributes data across different nodes in a cyclic.
- Range: distributes data across different nodes based on the value range of partitioning columns.
- List: distributes data across different nodes based on the discrete values of partitioning columns, such as age.
- Hash: distributes data across different nodes based on a hash algorithm.
To achieve more flexible data distribution, you can combine the preceding four partitioning methods based on your business requirements, such as hash-hash, range-hash, and hash-list. StarRocks offers the following two partitioning methods:
-
Hash: A hash-partitioned table has only one partition (the entire table is considered a partition). The partition is divided into tablets based on the bucketing column and the number of tablets that you specified.
For example, the following statement creates a table
site_access. The table is divided into 10 tablets based on thesite_idcolumn.CREATE TABLE site_access(
site_id INT DEFAULT '10',
city_code SMALLINT,
user_name VARCHAR(32) DEFAULT '',
pv BIGINT SUM DEFAULT '0'
)
AGGREGATE KEY(site_id, city_code, user_name)
DISTRIBUTED BY HASH(site_id) BUCKETS 10; -
Range-hash: A range-hash partitioned table divides data into multiple partitions based on the partitioning column. Each partition is further divided into tablets based on the bucketing column and the number of tablets that you specified.
For example, the following statement creates a table
site_accessthat is partitioned by theevent_daycolumn. The table contains 3 partitions:p1,p2, andp3. Each partition is divided into 10 tablets based on thesite_idcolumn.CREATE TABLE site_access(
event_day DATE,
site_id INT DEFAULT '10',
city_code VARCHAR(100),
user_name VARCHAR(32) DEFAULT '',
pv BIGINT SUM DEFAULT '0'
)
AGGREGATE KEY(event_day, site_id, city_code, user_name)
PARTITION BY RANGE(event_day)
(
PARTITION p1 VALUES LESS THAN ("2020-01-31"),
PARTITION p2 VALUES LESS THAN ("2020-02-29"),
PARTITION p3 VALUES LESS THAN ("2020-03-31")
)
DISTRIBUTED BY HASH(site_id) BUCKETS 10;
Design partitioning and bucketing rules
Before you partition a table, determine the partitioning column, bucketing column, and the number of tablets.
Choose partitioning columns
Data in a partitioned table is divided based on partitioning columns, also called partition keys. Generally, date or area is used as the partitioning column. In StarRocks, only the column of the DATE, DATETIME or INT type can be used as the partitioning column. We recommend that you follow the suggestions below to decide the partitioning column:
- The column with low cardinality.
- The column that is often used as a filter in queries.
- The amount of data in each partition must be less than 100 GB.
Choose bucketing columns
Data in partitions can be subdivided into tablets based on the hash values of the bucketing columns and the number of buckets. We recommend that you choose the column that satisfy the following two requirements as the bucketing column.
- high cardinality column such as ID
- column that often used as a filter in queries
But if the column that satisfies both requirements does not exist, you need to determine the bucketing column according to the complexity of queries.
- If the query is complex, it is recommended that you select the high cardinality column as the bucketing column to ensure that the data is as balanced as possible in each bucket and improve the cluster resource utilization.
- If the query is relatively simple, then it is recommended to select the column that is often used as in the query condition as the bucketing column to improve the query efficiency.
If partition data cannot be evenly distributed into each tablet by using one bucketing column, you can choose multiple bucketing columns. You can decide on the number of bucketing columns based on the following scenarios:
- One bucketing column: This method can reduce data transmission between nodes. It improves the performance of short-running query because short-running query only runs on one server and scan a small amount of data.
- Multiple bucketing columns: This method makes the most of the concurrency performance of a distributed cluster. It improves the performance of long-running query because long-running query runs across multiple servers and scan a large amount of data by using multiple servers in parallel. We recommend that you choose three bucketing columns at most.
Precautions
- When a table is created, you must specify the bucketing columns.
- The data types of bucketing columns must be INTEGER, DECIMAL, DATE/DATETIME, or CHAR/VARCHAR/STRING.
- Bucketing columns cannot be modified after they are specified.
- The values of bucketing columns cannot be updated.
Examples
The following statement creates a table named site_access.
CREATE TABLE site_access(
event_day DATE,
site_id INT DEFAULT '10',
city_code VARCHAR(100),
user_name VARCHAR(32) DEFAULT '',
pv BIGINT SUM DEFAULT '0'
)
AGGREGATE KEY(event_day, site_id, city_code, user_name)
PARTITION BY RANGE(event_day)
(
PARTITION p1 VALUES LESS THAN ("2020-01-31"),
PARTITION p2 VALUES LESS THAN ("2020-02-29"),
PARTITION p3 VALUES LESS THAN ("2020-03-31")
)
DISTRIBUTED BY HASH(site_id) BUCKETS 10;
In this example, site_access uses site_id as the bucketing column because this column is always used as a filter in queries. When the bucketing column is used as a filter in queries, StarRocks only scans the relevant tablets, which greatly improves query performance.
Suppose you execute the following statement to query site_access. After you send the query, StarRocks only scans data in one tablet of site_access. The overall query speed is much faster than scanning 10 tablets.
select sum(pv)
from site_access
where site_id = 54321;
However, if site_id is unevenly distributed and a large number of queries are destined for only a few sites, the preceding bucketing method will cause severe data skew, causing system performance bottlenecks. In this case, you can use a combination of bucketing columns. For example, the following statement uses site_id and city_code as bucketing columns.
CREATE TABLE site_access
(
site_id INT DEFAULT '10',
city_code SMALLINT,
user_name VARCHAR(32) DEFAULT '',
pv BIGINT SUM DEFAULT '0'
)
AGGREGATE KEY(site_id, city_code, user_name)
DISTRIBUTED BY HASH(site_id,city_code) BUCKETS 10;
Determine the number of tablets
Tablets reflect how data files are organized in StarRocks. Since StarRocks 2.5, you do not need to set the number of buckets when a table is created, and StarRocks sets the number of buckets automatically.
CREATE TABLE site_access(
site_id INT DEFAULT '10',
city_code SMALLINT,
user_name VARCHAR(32) DEFAULT '',
pv BIGINT SUM DEFAULT '0'
)
AGGREGATE KEY(site_id, city_code, user_name)
DISTRIBUTED BY HASH(site_id,city_code); --do not need to set the number of buckets
If you intend to set the number of buckets, StarRocks 2.4 and later versions support using multiple threads to scan a tablet in parallel during a query, thereby reducing the dependency of scanning performance on the tablet count. We recommend that each tablet contains about 10 GB of raw data. You can estimate the amount of data in each partition of a table and then decide the number of tablets. To enable the parallel scanning on tablets, make sure the GLOBAL enable_tablet_internal_parallel is enabled.
Note: You cannot modify the number of tablets for an existing partition. You can only modify the number of tablets when you add a partition.
Manage partitions
Create partitions
You can partition a table in threes ways by using PARTITION BY RANGE clause:
-
Partition a table with the LESS THAN clause. For more information, see CREATE TABLE.
PARTITION BY RANGE (k1, k2, ...)
(
PARTITION partition_name1 VALUES LESS THAN ("value1", "value2", ...),
PARTITION partition_name2 VALUES LESS THAN ("value1", "value2", ...),
PARTITION partition_name3 VALUES LESS THAN (MAXVALUE)
) -
Partition a table by specifying values of a fixed range. For more information, see CREATE TABLE.
PARTITION BY RANGE (k1, k2, k3, ...)
(
PARTITION partition_name1 VALUES [("k1-lower1", "k2-lower1", "k3-lower1",...), ("k1-upper1", "k2-upper1", "k3-upper1", ...)],
PARTITION partition_name2 VALUES [("k1-lower1-2", "k2-lower1-2", ...), ("k1-upper1-2", MAXVALUE, )],
"k3-upper1-2", ...
) -
Partition a table by specifying START, END, and EVERY. You can create multiple partitions at a time by using this method. For more information, see CREATE TABLE.
PARTITION BY RANGE (k1, k2, ...)
(
START ("value1") END ("value2") EVERY (INTERVAL value3 day)
)
Examples
The following examples demonstrate how to partition a table by specifying START, END, and EVERY.
-
The data type of the partitioning column is DATE and you specify the time range of partitioning via START and END and define the time range via EVERY. Example:
CREATE TABLE site_access (
datekey DATE,
site_id INT,
city_code SMALLINT,
user_name VARCHAR(32),
pv BIGINT DEFAULT '0'
)
ENGINE=olap
DUPLICATE KEY(datekey, site_id, city_code, user_name)
PARTITION BY RANGE (datekey) (
START ("2021-01-01") END ("2021-01-04") EVERY (INTERVAL 1 DAY)
)
DISTRIBUTED BY HASH(site_id) BUCKETS 10
PROPERTIES ("replication_num" = "3"
);The PARTITION BY RANGE clause in this example is equal to the following:
PARTITION BY RANGE (datekey) (
PARTITION p20210101 VALUES [('2021-01-01'), ('2021-01-02')),
PARTITION p20210102 VALUES [('2021-01-02'), ('2021-01-03')),
PARTITION p20210103 VALUES [('2021-01-03'), ('2021-01-04'))
) -
The data type of the partitioning column is DATE and you specify different EVERY clauses for different time ranges (which cannot overlap with each other). Example:
CREATE TABLE site_access(
datekey DATE,
site_id INT,
city_code SMALLINT,
user_name VARCHAR(32),
pv BIGINT DEFAULT '0'
)
ENGINE=olap
DUPLICATE KEY(datekey, site_id, city_code, user_name)
PARTITION BY RANGE (datekey)
(
START ("2019-01-01") END ("2021-01-01") EVERY (INTERVAL 1 YEAR),
START ("2021-01-01") END ("2021-05-01") EVERY (INTERVAL 1 MONTH),
START ("2021-05-01") END ("2021-05-04") EVERY (INTERVAL 1 DAY)
)
DISTRIBUTED BY HASH(site_id) BUCKETS 10
PROPERTIES(
"replication_num" = "1"
);The PARTITION BY RANGE clause in this example is equal to the following:
PARTITION BY RANGE (datekey) (
PARTITION p2019 VALUES [('2019-01-01'), ('2020-01-01')),
PARTITION p2020 VALUES [('2020-01-01'), ('2021-01-01')),
PARTITION p202101 VALUES [('2021-01-01'), ('2021-02-01')),
PARTITION p202102 VALUES [('2021-02-01'), ('2021-03-01')),
PARTITION p202103 VALUES [('2021-03-01'), ('2021-04-01')),
PARTITION p202104 VALUES [('2021-04-01'), ('2021-05-01')),
PARTITION p20210501 VALUES [('2021-05-01'), ('2021-05-02')),
PARTITION p20210502 VALUES [('2021-05-02'), ('2021-05-03')),
PARTITION p20210503 VALUES [('2021-05-03'), ('2021-05-04'))
) -
The data type of the partitioning column is INT and you specify the value range of partitioning by using START and END and define the incremental value via EVERY. Example:
Note: Do not double quote the incremental value defined by EVERY.
CREATE TABLE site_access (
datekey INT,
site_id INT,
city_code SMALLINT,
user_name VARCHAR(32),
pv BIGINT DEFAULT '0'
)
ENGINE=olap
DUPLICATE KEY(datekey, site_id, city_code, user_name)
PARTITION BY RANGE (datekey) (START ("1") END ("5") EVERY (1)
)
DISTRIBUTED BY HASH(site_id) BUCKETS 10
PROPERTIES ("replication_num" = "1"
);The PARTITION BY RANGE clause in this example is equal to the following:
PARTITION BY RANGE (datekey) (
PARTITION p2019 VALUES [('2019-01-01'), ('2020-01-01')),
PARTITION p2020 VALUES [('2020-01-01'), ('2021-01-01')),
PARTITION p202101 VALUES [('2021-01-01'), ('2021-02-01')),
PARTITION p202102 VALUES [('2021-02-01'), ('2021-03-01')),
PARTITION p202103 VALUES [('2021-03-01'), ('2021-04-01')),
PARTITION p202104 VALUES [('2021-04-01'), ('2021-05-01')),
PARTITION p20210501 VALUES [('2021-05-01'), ('2021-05-02')),
PARTITION p20210502 VALUES [('2021-05-02'), ('2021-05-03')),
PARTITION p20210503 VALUES [('2021-05-03'), ('2021-05-04'))
) -
After a table is created, you can use the ALTER TABLE statement to add partitions for the table.
ALTER TABLE site_access
ADD PARTITIONS START ("2021-01-04") END ("2021-01-06") EVERY (INTERVAL 1 DAY);
Add a partition
You can add new partitions to store input data in a table. By default, the number of tablets in the new partition is equal to the number of tablets in the existing partitions. You can also adjust the number of tablets according to the amount of data in the new partition.
The following statement adds a new partition p4 to table site_access to store data generated in April.
ALTER TABLE site_access
ADD PARTITION p4 VALUES LESS THAN ("2020-04-30")
DISTRIBUTED BY HASH(site_id) BUCKETS 20;
Delete a partition
The following statement deletes partition p1 from table site_access.
ALTER TABLE site_access
DROP PARTITION p1;
Note: If a partition is deleted within 24 hours, the data of the partition remains in Trash. During the period, you can execute the RECOVER statement to restore this data.
Restore a partition
The following statement restores partition p1 to table site_access.
RECOVER PARTITION p1 FROM site_access;
View partitions
The following statement displays all partitions in table site_access.
SHOW PARTITIONS FROM site_access;